









在當今快節奏的分析開發環境中,數據科學家的任務將不僅僅是構建機器學習模型并將其部署到生產環境當中。現在,他們需要負責定期監控、微調、更新、再訓練、替換和啟動模型-在某些情況下,還需要整合數百甚至數千個模型。
因此便出現了不同層次的模型管理需求。在下面的文章中,我將著重介紹從單一的模型管理到建立整個模型工廠的每一種方法。
機器學習的工作流程基礎
您可能想知道,我是如何使用我的訓練過程的結果來獲得新的數據的?有很多選項,例如在用于訓練和以標準化格式導出模型的同一系統中進行評分。或者,您也可以將模型推送到其他系統中,例如將模型作為數據庫中的SQL語句來進行評分,或者將模型打包,以便在完全不同的運行時環境中進行處理。從模型管理的角度來看,您只需要能夠支持所有必需的選項。
標準流程如下所示:

注意:在現實中,除非有少部分數據處理(轉換/集成)是生產中“模型”的一部分,否則模型本身通常都不是非常有用。這就是許多部署選項的不足之處,因為它們僅支持預測模型的部署。
機器學習模型的評估與監控
模型管理的一個重要部分是確保模型保持其應有的性能。正如許多數據科學家所被迫的那樣,定期收集過去的數據只能確保模型沒有突然改變。持續監控允許您測量模型是否開始“漂移”,即是否由于現實的變化而變得過時。有時,最好使用包括人工標注的數據來測試邊界案例,或者只是確保模型不會犯嚴重錯誤。
最后,模型評估的結果應該是對模型質量的某種形式的評分,例如分類的準確性。有時,您需要更多依賴于應用程序的度量,例如預測成本或風險度量。然而,對于您如何處理這些評分,則又是另一回事了。
更新和再訓練機器學習模型
在下一個階段,我們將從監視轉移到實際管理上來。假設您的監控解決方案開始報告越來越多的錯誤。在這種情況下,您可以觸發自動模型更新、再訓練,甚至是完全替換模型。
一些模型管理設置只是訓練一個新模型,然后部署它。然而,由于訓練可能占用大量的資源和時間,一種更明智的方法是讓這種轉換與性能相關聯。定義一個性能閾值以確保替換現有模型的實際價值。你需要對前一個模型(通常稱為冠軍模型)和新訓練模型(挑戰模型)進行評估;對它們進行評分并決定是應該部署新模型還是保留舊模型。在某些情況下,您可能只想在新模型的性能顯著優于舊模型時才愿意經歷模型部署的麻煩。
即使有了持續的監控、再訓練和替換,如果您不在管理系統的其他地方采取預防措施,機器學習模型的模型仍然會有季節性的變化。例如,如果該模型是用來預測服裝的銷售配額的,那么季節可能將顯著的影響這些預測。如果你每個月都進行監控和再訓練,年復一年,您自然可以有效地訓練模型以適應當前季節。您還可以手動設置季節性模型的組合,這些模型的權重會根據季節的不同而不同。
有時模型需要保證特定情況下的特定行為。將專家知識注入模型學習是實現這一目標的一種方法,但是具有可以覆蓋訓練模型輸出的單獨規則模型則是一種更透明的解決方案。
雖然有些模型可以更新,但算法可能會很健忘。很久以前的數據在決定模型參數方面的作用將越來越小。這有時是可取的,但如何適當的調整遺忘速度的確是一個難題。
另一種方法是重新訓練模型,從頭構建一個新模型。這允許您使用適當的數據抽樣(和評分)策略,以確保新模型是在過去和最近數據的正確組合上訓練的。
現在,管理過程看起來更像是這樣:

管理多個機器學習模型
假設您現在想要持續地監視和更新/再訓練整個模型集。您可以使用與單模型情況相同的方式處理此問題,但是對于多個模型,就會出現與接口和實際管理相關的問題。您如何向用戶傳達許多模型的狀態,并讓用戶與它們交互,以及由誰來控制所有這些流程的執行?必須有一個所有模型的儀表板視圖,該視圖具有管理和控制單個模型的功能。
大多數工作流工具允許將它們的內部作為服務公開,因此您可以設置一個單獨的程序,以確保您的單個模型管理過程被正確地調用。您可以構建單獨的應用程序,也可以使用現有的開源軟件來編排建模工作流、監督這些流程并總結它們的輸出。
當您將大量機器學習模型分組到不同的模型族中時,管理它們也將變得更加有趣。你可以用類似的方法來處理預測相似行為的模型。如果您經常需要新模型,這將特別有用。當模型相似時,您可以通過從集合中的現有模型初始化一個新模型來節省時間和精力,而不是從頭開始,或者僅僅根據孤立的過去數據來對新模型進行訓練。您可以使用最相似的模型(由對象的相似性度量決定)或混合模型來進行初始化。
模型管理的設置現在看起來是這樣的:
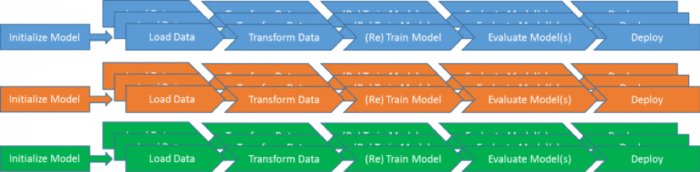
如果您充分抽象了模型之間的接口,您應該能夠隨意的進行混合和匹配。這將允許新模型重用負載、轉換、(重新)訓練、評估和部署策略,并以任意方式組合它們。對于每個特定模型,您只需要定義在這個通用模型管理管道中的每個階段使用哪些特定的流程步驟。
如下所示:
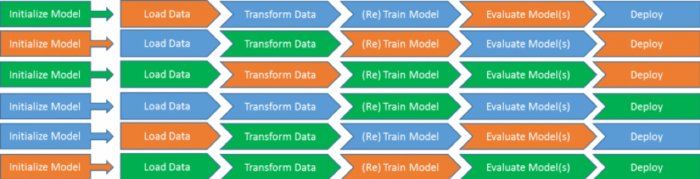
部署模型可能只有兩種不同的方式,但是訪問數據則有十多種不同的方法。如果你還必須將它分成不同的模型流程族,那么你最終會得到一百多種不同的結果。
機器學習模型工廠
機器學習模型管理的最后一步是創建模型工廠。例如,這可以通過僅定義上面的各個部分(流程步驟)并以配置文件中定義的靈活方式來進行組合配置。然后,無論何時,當有人想要在以后更改數據訪問或首選的模型部署時,您只需要調整特定的流程步驟,而不必去修改使用它的所有流程。這是一個極有效的省時方法。
在這個階段,將評估步驟分為兩部分是有意義的,一部分計算模型的分數,另一部分決定如何處理該分數。后者可以包括處理冠軍/挑戰者場景的不同策略,并且獨立于實際得分的計算。
這樣,讓一個模型工廠投入實際工作將會非常簡單。你只需要配置每個流程步驟的哪個具體方案用于哪個模型管道。對于每個模型,您可以自動比較過去和當前的性能,并據此決定是否觸發再訓練和更新。在關于企業可伸縮模型流程的白皮書中對此進行了詳細描述。
雖然其中包含了大量的信息,但是數據科學家將會掌握上述的每一個級別,因為他們也必須掌握。而今天的海量信息將很快變得微不足道。現在,我們必須開發可靠的管理實踐,以處理日益龐大的數據量和隨之而來的大量模型,以便最終理解這些數據。
Michael Berthold博士是KNIME的創始人兼首席執行官。他在數據分析、機器學習、人工智能和規則歸納方面有超過25年的研究和行業經驗。作為康斯坦茨大學、卡內基梅隆大學和加州大學伯克利分校的教授,以及英特爾、Utopy和Tripos的工業專家,Michael有著悠久的學術生涯。
















 京公網安備 11010502049343號
京公網安備 11010502049343號