









在這篇文章中,我們將比較深度學習與傳統(tǒng)的機器學習技術(shù)。在這樣做的過程中,我們將找出兩種技術(shù)的優(yōu)點和缺點,以及它們在哪里,如何獲得最佳的使用。
深度學習>經(jīng)典機器學習
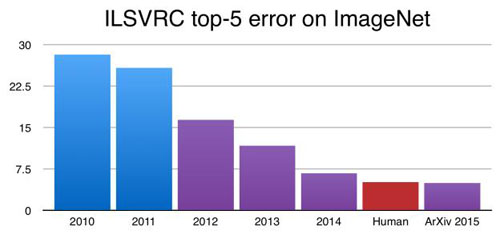
一流的表現(xiàn):深度網(wǎng)絡已經(jīng)實現(xiàn)了遠遠超過傳統(tǒng)ML方法的精確度,包括語音、自然語言、視覺和玩游戲等許多領域。在許多任務中,經(jīng)典ML甚至無法競爭。例如,下圖顯示了ImageNet數(shù)據(jù)集上不同方法的圖像分類準確性,藍色表示經(jīng)典ML方法,紅色表示深度卷積神經(jīng)網(wǎng)絡(CNN)方法。
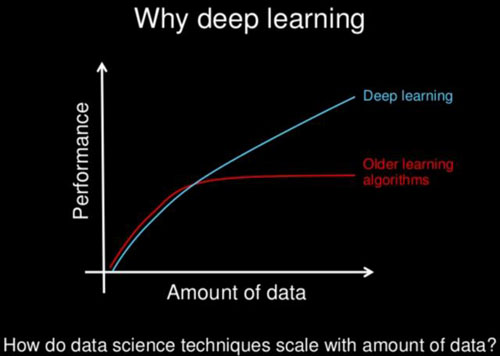
使用數(shù)據(jù)進行有效縮放:與傳統(tǒng)ML算法相比,深度網(wǎng)絡使用更多的數(shù)據(jù)可以更好地擴展。下面的圖表是一個簡單而有效的例子。很多時候,通過深層網(wǎng)絡來提高準確性的最佳建議就是使用更多的數(shù)據(jù)!使用經(jīng)典的ML算法,這種快速簡單的修復方法甚至幾乎沒有效果,并且通常需要更復雜的方法來提高準確性。
不需要特征工程:經(jīng)典的ML算法通常需要復雜的特征工程。首先在數(shù)據(jù)集上執(zhí)行深度探索性數(shù)據(jù)分析,然后做一個簡單的降低維數(shù)的處理。最后,必須仔細選擇最佳功能以傳遞給ML算法。當使用深度網(wǎng)絡時,不需要這樣做,因為只需將數(shù)據(jù)直接傳遞到網(wǎng)絡,通常就可以實現(xiàn)良好的性能。這完全消除了整個過程的大型和具有挑戰(zhàn)性的特征工程階段。
適應性強,易于轉(zhuǎn)換:與傳統(tǒng)的ML算法相比,深度學習技術(shù)可以更容易地適應不同的領域和應用。首先,遷移學習使得預先訓練的深度網(wǎng)絡適用于同一領域內(nèi)的不同應用程序是有效的。
例如,在計算機視覺中,預先訓練的圖像分類網(wǎng)絡通常用作對象檢測和分割網(wǎng)絡的特征提取前端。將這些預先訓練的網(wǎng)絡用作前端,可以減輕整個模型的訓練,并且通常有助于在更短的時間內(nèi)實現(xiàn)更高的性能。此外,不同領域使用的深度學習的基本思想和技術(shù)往往是相當可轉(zhuǎn)換的。
例如,一旦了解了語音識別領域的基礎深度學習理論,那么學習如何將深度網(wǎng)絡應用于自然語言處理并不是太具有挑戰(zhàn)性,因為基準知識非常相似。對于經(jīng)典ML來說,情況并非如此,因為構(gòu)建高性能ML模型需要特定領域和特定應用的ML技術(shù)和特征工程。對于不同的領域和應用而言,經(jīng)典ML的知識庫是非常不同的,并且通常需要在每個單獨的區(qū)域內(nèi)進行廣泛的專業(yè)研究。
經(jīng)典機器學習>深度學習
對小數(shù)據(jù)更好:為了實現(xiàn)高性能,深層網(wǎng)絡需要非常大的數(shù)據(jù)集。之前提到的預先訓練過的網(wǎng)絡在120萬張圖像上進行了訓練。對于許多應用來說,這樣的大數(shù)據(jù)集并不容易獲得,并且花費昂貴且耗時。對于較小的數(shù)據(jù)集,傳統(tǒng)的ML算法通常優(yōu)于深度網(wǎng)絡。
財務和計算都便宜:深度網(wǎng)絡需要高端GPU在大量數(shù)據(jù)的合理時間內(nèi)進行訓練。這些GPU非常昂貴,但是如果沒有他們訓練深層網(wǎng)絡來實現(xiàn)高性能,這在實際上并不可行。要有效使用這樣的高端GPU,還需要快速的CPU、SSD存儲以及快速和大容量的RAM。傳統(tǒng)的ML算法只需要一個體面的CPU就可以訓練得很好,而不需要最好的硬件。由于它們在計算上并不昂貴,因此可以更快地迭代,并在更短的時間內(nèi)嘗試許多不同的技術(shù)。
更容易理解:由于傳統(tǒng)ML中涉及直接特征工程,這些算法很容易解釋和理解。此外,調(diào)整超參數(shù)并更改模型設計更加簡單,因為我們對數(shù)據(jù)和底層算法都有了更全面的了解。另一方面,深層網(wǎng)絡是“黑匣子”型,即使現(xiàn)在研究人員也不能完全了解深層網(wǎng)絡的“內(nèi)部”。由于缺乏理論基礎、超參數(shù)和網(wǎng)絡設計也是一個相當大的挑戰(zhàn)。















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號