









人工智能就像個不斷移動的標靶,而企業要做的就是努力“正中靶心”。

當然,當我們看到Alexa、Siri以及AlphaGO不斷占據新聞頭條的同時,不得不承認的另一個現實情況是——包括機器學習、深度學習等在內的諸多人工智能技術仍然存在非常多的局限性,這還需要我們投入巨大的精力和時間去克服。
為此,在今天的文章中,我們將全面探討人工智能技術目前面臨的障礙以及對應的解決方法。
據麥肯錫全球研究院在最近的研究報告(相關文章《麥肯錫在全球調研分析了160個案例,給出5個行業的34個AI應用場景》)中指出,行業中的領導企業往往更青睞于對人工智能技術的投資和應用(如圖1)。
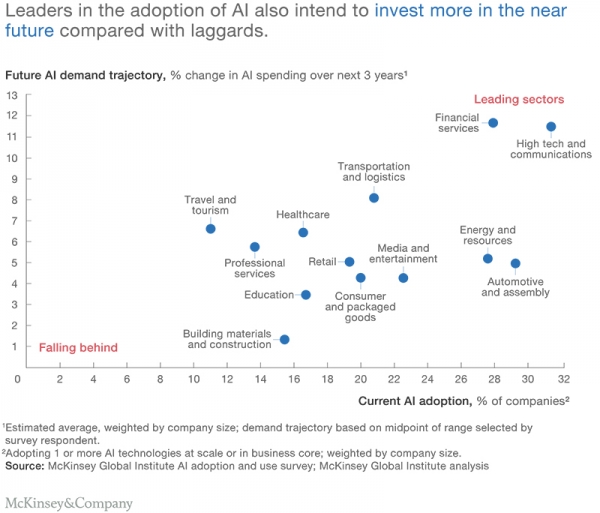
因此,要提升企業在未來的競爭力,就必須要有能力掌握更為充分的信息以應對人工智能難題。換句話來說,我們不僅需要理解AI在促進創新、洞察力以及決策、推動營收增長乃至改進效率水平等層面的現實意義,同時也有必要深入了解人工智能還無法實現價值的領域。
挑戰、局限與機遇:從深度學習技術談起
可以說,深度學習是人工智能領域目前最受關注的發展成果,利用包含數百萬個分層構建的模擬“神經元”的大型神經網絡,它正在幫助我們提升分類與預測的準確性。其中,最常見的網絡被稱為卷積神經網絡(簡稱CNN)與遞歸神經網絡(簡稱RNN)。這些神經網絡能夠通過數據訓練,并配合反向傳播算法實現“學習”。
雖然這一技術已經取得了一系列進展,但需要注意的是,其中還有最關鍵的一步,就是如何將人工智能方法與問題和可用數據匹配起來。由于這些系統是“訓練”而來,而非編程而來的,因此其學習過程往往需要大量標記數據才能準確執行復雜的任務。然而,獲取大規模數據集往往相當困難,即使能夠實現,標記工作也需要巨大的人力投入。
此外,我們很難判斷深度學習訓練所使用的數學模型要如何才能達成特定的預測、推薦或決策要求。這就是“黑匣子”問題,即使模型能夠支持實現既定的目標,但效用恐怕也將十分有限。考慮到這一點,用戶有時候的確需要了解這背后的運作原理,以及為何在特定情況下某些因素的權重要比其它因素更高等等。然而,這并不容易。
基于此,下面我們列舉了人工智能技術及其應用目前存在的五大局限,以及與之對應的解決方案:
1- 需要大量的數據標記
大多數現有的AI模型都是通過“監督學習”訓練而成的。這意味著人類必須對樣本數據進行標記與分類,但這一過程很可能存在一些難以察覺的錯誤。強化學習與生成式對抗網絡(GAN)是解決這一問題的兩個重要手段。
強化學習。強化學習是一種無監督學習的方法,它允許算法通過反復試驗完成學習任務。有點像是“胡蘿卜加大棒”的簡單訓練方式:即對于算法在執行任務時所做出的每一次嘗試,如果其行為獲得成功,則給予“報酬”(例如更高的分數); 如果不成功,則給予“懲罰”。經過不斷重復,使得學習環境能夠準確反映現實情況,從而提升模型的效能。
目前這一方法已經廣泛應用于游戲領域,AlphaGo就是一個典型例子。此外,強化學習還擁有在商業領域應用的巨大潛力,比如,通過構建一套人工智能驅動型交易組合,從而在盈利與虧損之間學習發現正確的交易規律; 比如,打造產品推薦引擎,以積分方式為銷售活動提供決策建議; 甚至以按時交付或減少燃油消耗作為報酬指標,開發運輸路線選擇的軟件等等。
生成式對抗網絡。生成式對抗網絡是一種半監督學習的方法,通過兩套相互對抗的神經網絡,不斷完善各自對同一概念的理解。以識別鳥類圖像為例,一套網絡負責正確分辨鳥類圖像,而另一套網絡則負責生成與鳥類非常相似的其它圖像對前者進行迷惑。當兩套網絡的表現最終趨于穩定時,其各自對鳥類圖像也擁有了更為準確的認知。
生成式對抗網絡能夠在一定程度上降低對數據集數量的要求。舉例來說,通過訓練算法從醫學圖像當中識別不同類型的腫瘤時,以往科學家們往往需要從人類標記的數百萬張包含特定腫瘤類型或階段的圖像當中提取信息并創建數據集。但經過訓練的生成式對抗網絡就可以通過繪制逼真的腫瘤圖像,從而訓練腫瘤檢測算法,在此基礎上將小型人類標記數據集與生成對抗網絡的輸出結果相結合,快速完成學習。
2- 需要海量的數據集
目前,機器學習技術要求訓練數據集不僅包含人工注釋信息,同時在體量上也需要夠大、夠全面。而深度學習也要求模型能夠對成千上萬條的數據記錄進行學習,才能獲得相對理想的分類能力; 甚至在某些情況下,其需要學習的數據要達到數百萬條才能實現與人類相近的判斷準確率。舉例來說,如果希望讓自動駕駛車輛學會如何在多種天氣條件下行駛,就需要在數據集當中輸入可能遇到的各類不同環境條件。
然而,在現實應用中大量數據集往往很難獲取。對此,一次性學習(One-shot learning)是一種能夠減少對大型數據集需求的技術,只需要利用少量現實的演示或示例(在某些情況下甚至只需要單一示例)就可以完成學習,快速掌握新技能。如此一來,人工智能的決策行為將更接近于人類,即只需要單一的樣本就可以精確識別出同一類別的其它多種實例。
具體而言,數據科學家們首先會在變化的虛擬環境中預先訓練出一套模型,使其能夠利用自身的知識順利找到正確的解決方案。一次性學習通常被認為是計算機視覺中的對象分類問題,旨在從一個或僅少數幾個訓練圖像中學習關于對象類別的信息,并且已經成功應用到包括計算機視覺和藥物研發在內的具有高維數據的領域。
3- “黑匣子”問題
可解釋性對于人工智能系統絕不是什么新問題。隨著深度學習的逐步普及,其應用范圍將不斷擴大。但這也意味著,更為多樣化以及更前沿的應用往往存在著更嚴重的不透明問題。
規模更大、復雜度更高的模型使得人們很難解釋計算機作出某項決策的原因。然而,隨著人工智能應用范圍的擴大,監管機構將對人工智能模型的可解釋性作出嚴格規定。
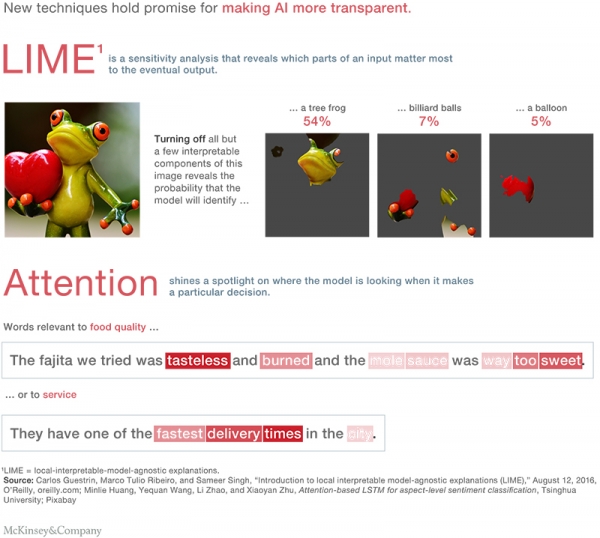
對此,目前有兩種新的方法用以提高模型的透明度,分別為與模型無關的解釋技術(Local Interpretable Model-Agnostic Explanations,簡稱LIME)與關注技術(attention techniques)(如圖2)。
LIME方法是在一套經過訓練的模型當中,確定其作出某個決策過程中更多依賴的那部分輸入數據,并利用可解釋代理模型對此進行預測。這種方法通過對特定的數據區段進行分析,并觀察預測結果的變化,從而對模型進行微調,最終形成更為精確的解釋。
關注技術(attention techniques)則是對模型認為最重要的輸入數據進行可視化處理,并分析這部分數據與所作出決策之間的關系。
除此之外,還有另一種方法——廣義相加模型(簡稱GAM)(簡稱GAM)。線性模型簡單、直觀、便于理解,但是,在現實生活中,變量的作用通常不是線性的,線性假設很可能不能滿足實際需求,甚至直接違背實際情況。廣義加性模型是一種自由靈活的統計模型,它可以用來探測到非線性回歸的影響。通過對單特征模型的利用,它能夠限制不同變量的相互作用,從而確保每項特征的輸出更容易被加以解釋。
通過這些方法,我們正在慢慢揭開人工智能決策的“神秘面紗”,這一點對于增強人工智能的采用范圍具有極為重要的現實意義。
4- 學習模型的“通用性”
與人類的學習方式不同,人工智能模型很難將其學習到的經驗舉一反三。因此,即使在相似度很高的案例中,企業也必須多次投入資源來訓練新的模型,而這就意味著新的成本。
解決這個問題其中的一種的有效方式是遷移學習。即把一個領域(即源領域)的知識,遷移到另外一個領域(即目標領域),使得目標領域能夠取得更好的學習效果。在人工智能領域,就是通過訓練人工智能模型完成某項任務,并將其迅速遷移至另一項類似但有所不同的任務環境中來實現“舉一反三”。
隨著遷移學習的逐步成熟,其將能夠幫助企業更快構建起新型的應用程序,并為現有的應用程序提供更多功能。
舉例來說,在創建虛擬助理時,遷移學習能夠將用戶在某一領域(例如音樂)的偏好推廣到其它領域(例如書籍)。再比如,遷移學習還能幫助石油天然氣生產商,擴大AI算法訓練規模,從而對管道及鉆井平臺等設備進行預測性維護。
另一種方法,是利用能夠在多個問題當中應用的廣義性架構。譬如DeepMind在AlphaZero當中就設計了一套對應三種不同游戲的架構模型。
5- 數據與算法中的“偏見”
如果輸入的數據摻雜了人的偏好或者某些數據被忽略、某些數據被偏重,那么就有可能使得算法結果存在“偏見”。在具體的應用中,有可能造成錯誤的招聘決策、不當的科學或醫療預測、不合理的金融模式或刑事司法決策,甚至在法律層面引發濫用問題。但是,在大多數情況下,這些“偏見”往往難以被察覺。
目前,業界正在進行多項研究工作,從而建立最佳實踐以解決學術、非營利與私營部門所面臨的這一實際問題。
企業應該如何擊中“移動中的標靶”
要解決上面提到的這些局限性難題,我們還有很長的路要走。然而,事實上,人工智能面臨的最大局限可能在于我們的想象力。下面,麥肯錫為希望利用人工智能技術實現飛躍的企業領導者提出了一些建議:
做好功課,緊盯目標,并隨時跟進。雖然大多數高管并不需要了解卷積神經網絡與遞歸神經網絡之間的區別,但也要對目前它們所能實現的功能有大致了解,在掌握其短期發展的可能性的同時著眼未來。
了解數據科學與機器學習專家提出的專業知識,同時與AI先行者們進行交流,補齊自己的短板。
采用精準的數據策略。人工智能算法需要人為的幫助與引導,為此,企業可以提前制定全面的數據策略。該策略不僅需要關注對來自不同系統的數據進行匯總的技術,同時還應關注數據可用性,以及數據的獲取、標記、治理等任務。
雖然如上文所說,一些方法可以減少AI算法訓練所需要的數據量,但監督式學習仍然是目前的主流。同時,減少對數據的需求并不意味著不需要數據。因此,企業最關鍵的還是要了解并掌握自己的數據,并考慮如何對其加以利用。
打通數據,橫向思考。遷移學習技術目前仍處于起步階段。因此,如果您需要解決大型倉儲體系的預測性維護問題,您是否能夠利用相同的解決方案支持消費產品?面對多種銷售渠道,適用于其中之一的解決方案是否也能夠作用于其它渠道?因此,要讓算法能夠“舉一反三”,還應該鼓勵業務部門進行數據共享,這對于未來人工智能的應用將具有非常重要的意義。
主動當一個先行者。當然,只是單純跟上當前的人工智能技術還不足以保持企業長期的競爭優勢。企業領導者需要鼓勵自己的數據科學工作人員或合作伙伴與外部專家合作,利用新興技術來解決應用問題。
此外,要隨時了解技術的可行性與可用性。目前各類機器學習工具、數據集以及標準應用(包括語音、視覺與情緒檢測)類訓練模型正得到廣泛應用。隨時關注相關項目,并對其加以利用,將有效提升企業的先發優勢。
這兩年來,雖然人工智能技術已經令人們變得興奮不已,但實際上目前它的發展所需要的技術、工具與流程還沒有完全成形,研究人員正積極解決各類最為棘手的現實問題,作為企業,現在應該做的就是抓緊時間了解AI前沿所發生的一切,并以此為基礎定位組織與學習思路,最終利用甚至推動由此帶來的一切可能性。
















 京公網安備 11010502049343號
京公網安備 11010502049343號