










Spark的核心概念是RDD,而RDD的關鍵特性之一是其不可變性,來規(guī)避分布式環(huán)境下復雜的各種并行問題。這個抽象,在數(shù)據(jù)分析的領域是沒有問題的,它能最大化的解決分布式問題,簡化各種算子的復雜度,并提供高性能的分布式數(shù)據(jù)處理運算能力。
然而在機器學習領域,RDD的弱點很快也暴露了。機器學習的核心是迭代和參數(shù)更新。RDD憑借著邏輯上不落地的內(nèi)存計算特性,可以很好的解決迭代的問題,然而RDD的不可變性,卻非常不適合參數(shù)反復多次更新的需求。這本質(zhì)上的不匹配性,導致了Spark的MLlib庫,發(fā)展一直非常緩慢,從2015年開始就沒有實質(zhì)性的創(chuàng)新,性能也不好。
為此,Angel在設計生態(tài)圈的時候,優(yōu)先考慮了Spark。在V1.0.0推出的時候,就已經(jīng)具備了Spark on Angel的功能,基于Angel為Spark加上了PS功能,在不變中加入了變化的因素,可謂如虎添翼。
我們將以L-BFGS為例,來分析Spark在機器學習算法的實現(xiàn)上的問題,以及Spark on Angel是如何解決Spark在機器學習任務中的遇到的瓶頸,讓Spark的機器學習更加強大。
1. L-BFGS算法說明
L-BFGS模型參數(shù)更新過程如下:
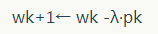
計算pk = Hk-1 gk 偽代碼如下所示,這是人們常說的two-loop recursion算法,是Limited-BFGS算法的核心部分。
返回值 r 是我們說要的pk。

其中,H0-1 是單位陣,yk=gk-gk-1, sk=wk-w k-1k-1,L-BFGS算法將最近 m 輪生成的 yk 和 sk 序列,記做 {yk} 和 {sk}。基于計算 {yk} 和 {sk} 計算 pk 。
2.L-BFGS的Spark實現(xiàn)
2.1 實現(xiàn)框架
Spark中的driver負責協(xié)調(diào)整個Spark任務執(zhí)行的同時,需要保存最近 m 輪的 {yk} 和 {sk} 序列,并在driver上執(zhí)行two-loop recursion算法。而executor負責分布式地計算梯度向量。
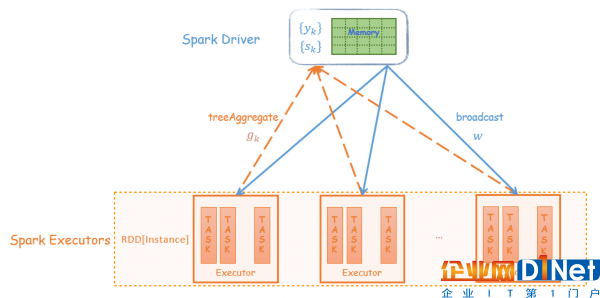
迭代過程:
(1)每輪迭代,將每個executor計算的梯度Aggregate到driver
(2)yk 和 sk 保存在driver上,在driver端執(zhí)行two-loop recursion算法
(3)driver上更新模型 w,并將 w 廣播到每個Executor
2.2 性能分析
基于Spark的L-BFGS實現(xiàn)的算法優(yōu)點比較明顯:
HDFS I/O
Spark可以快速讀寫HDFS上的訓練數(shù)據(jù);
細粒度的負載均衡
并行計算梯度時,Spark具有強大的并行調(diào)度機制,保證task快速執(zhí)行;
容錯機制
當計算節(jié)點掛掉、任務失敗,Spark會根據(jù)RDD的DAG關系鏈實現(xiàn)數(shù)據(jù)的重計算。但是對于迭代式算法,每輪迭代要用RDD的action操作,打斷RDD的DAG,避免因為重計算引起邏輯的錯亂;
基于內(nèi)存的計算
基于內(nèi)存的計算過程,可以加速機器學習算法中計算梯度過程的耗時。
該實現(xiàn)的缺點:
treeAggregate引起的網(wǎng)絡瓶頸
Spark用treeAggregate聚合梯度時,如果模型維度達到億級,每個梯度向量都可能達到幾百兆;此時treeAggregate的shuffle的效率非常低;
driver單點
保存{yk}和{sk}序列需要較大的內(nèi)存空間; two-loop recursion算法是由driver單點執(zhí)行,該過程是多個高維度的向量的運算; 每輪迭代,driver都需要和executor完成高維度向量的aggregate和broadcast。3.L-BFGS的Spark on Angel實現(xiàn)
3.1 實現(xiàn)框架
Spark on Angel借助Angel PS-Service的功能為Spark引入PS的角色,減輕整個算法流程對driver的依賴。two-loop recursion算法的運算交給PS,而driver只負責任務的調(diào)度,大大減輕的對driver性能的依賴。
Angel PS由一組分布式節(jié)點組成,每個vector、matrix被切分成多個partition保存到不同的節(jié)點上,同時支持vector和matrix之間的運算;
{yk} 和 {sk} 序列分布式地保存到Angel PS上,two-loop recursion算法中高維度的向量計算也是在PS上完成。Spark executor每輪迭代過程會從PS上Pull w 到本地,并將計算的梯度向量Push到PS。
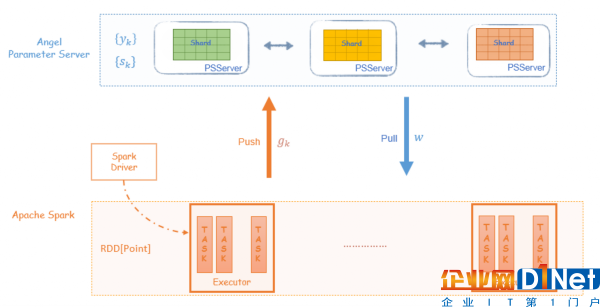
迭代過程:
(1)每輪迭代,executor 將PS上的模型 w pull 到本地,計算梯度,然后梯度向量push給PS
(2)yk 和 sk 保存在PS上,在PS端執(zhí)行two-loop recursion算法
(3)PS上更新模型 w
3.2 性能分析
整個算法過程,driver只負責任務調(diào)度,而復雜的two-loop recursion運算在PS上運行,梯度的Aggregate和模型的同步是executor和PS之間進行,所有運算都變成分布式。在網(wǎng)絡傳輸中,高維度的PSVector會被切成小的數(shù)據(jù)塊再發(fā)送到目標節(jié)點,這種節(jié)點之間多對多的傳輸大大提高了梯度聚合和模型同步的速度。
這樣Spark on Angel完全避開了Spark中driver單點的瓶頸,以及網(wǎng)絡傳輸高維度向量的問題。
4.“輕易強快”的Spark on Angel
Spark on Angel是Angel為解決Spark在機器學習模型訓練中的缺陷而設計的“插件”,沒有對Spark做"侵入式"的修改,是一個獨立的框架。可以用 “輕”、“易”、“強”、“快” 來概括Spark on Angel的特點。
4.1 輕——"插件式"的框架
Spark on Angel是Angel為解決Spark在機器學習模型訓練中的缺陷而設計的“插件”。Spark on Angel沒有對Spark中的RDD做侵入式的修改,Spark on Angel是依賴于Spark和Angel的框架,同時其邏輯又獨立于Spark和Angel。
因此,Spark用戶使用Spark on Angel非常簡單,只需在Spark的提交腳本里做三處改動即可,詳情可見Angel的Github Spark on Angel Quick Start文檔。
可以看到提交的Spark on Angel任務,其本質(zhì)上依然是一個Spark任務,整個任務的執(zhí)行過程與Spark一樣的。
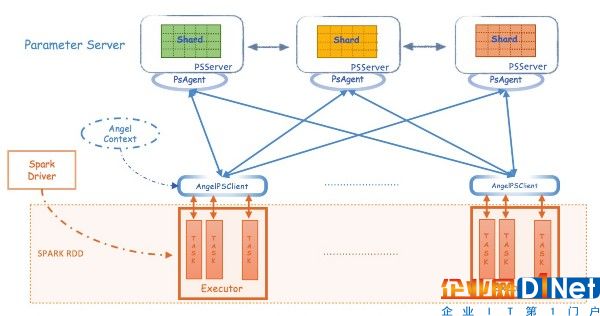
source ${Angel_HOME}/bin/spark-on-angel-env.sh$SPARK_HOME/bin/spark-submit --master yarn-cluster --conf spark.ps.jars=$SONA_ANGEL_JARS --conf spark.ps.instances=20 --conf spark.ps.cores=4 --conf spark.ps.memory=10g --jars $SONA_SPARK_JARS ....Spark on Angel能夠成為如此輕量級的框架,得益于Angel對PS-Service的封裝,使Spark的driver和executor可以通過PsAgent、PSClient與Angel PS做數(shù)據(jù)交互。
4.2 強——功能強大,支持breeze庫
breeze庫是scala實現(xiàn)的面向機器學習的數(shù)值運算庫。Spark MLlib的大部分數(shù)值優(yōu)化算法都是通過調(diào)用breeze來完成的。如下所示,Spark和Spark on Angel兩種實現(xiàn)都是通過調(diào)用breeze.optimize.LBFGS實現(xiàn)的。Spark的實現(xiàn)是傳入的類型是breeze庫的DenseVector,而Spark on Angel的實現(xiàn)是傳入BreezePSVector。
BreezePSVector是指Angel PS上的Vector,該Vector實現(xiàn)了breeze NumericOps下的方法,如常用的 dot,scale,axpy,add等運算,因此在LBFGS[BreezePSVector] two-loop recursion算法中的高維度向量運算是BreezePSVector之間的運算,而BreezePSVector之間全部在Angel PS上分布式完成。
Spark的L-BFGS實現(xiàn)import breeze.optimize.LBFGS val lbfgs = new LBFGS[DenseVector](maxIter, m, tol) val states = lbfgs.iterations(Cost(trainData), initWeight)接口調(diào)用里的Vector泛型從DenseVector變成 BreezePSVector import breeze.optimize.LBFGS val lbfgs = new LBFGS[BreezePSVector](maxIter, m, tol) val states = lbfgs.iterations(PSCost(trainData), initWeightPS)
4.3 易——編程接口簡單
Spark能夠在大數(shù)據(jù)領域這么流行的另外一個原因是:其編程方式簡單、容易理解,Spark on Angel同樣繼承了這個特性。
Spark on Angel本質(zhì)是一個Spark任務,整個代碼實現(xiàn)邏輯跟Spark是一致的;當需要與PSVector做運算時,調(diào)用相應的接口即可。
如下代碼所示,LBFGS在Spark和Spark on Angel上的實現(xiàn),二者代碼的整體思路是一樣的,主要的區(qū)別是梯度向量的Aggregate和模型 的pull/push。
因此,如果將Spark的算法改造成Spark on Angel的任務,只需要修改少量的代碼即可。
L-BFGS需要用戶實現(xiàn)DiffFunction,DiffFunction的calculte接口輸入?yún)?shù)是 ,遍歷訓練數(shù)據(jù)并返回 loss 和 gradient。
其完整代碼,請前往Github SparseLogistic。
Spark的DiffFunction實現(xiàn) case class Cost(trainData: RDD[Instance]) extends DiffFunction[DenseVector] { def calculate(w: DenseVector): (Double, DenseVector) = { // 廣播 w val bcW = sc.broadcast(w) // 通過treeAggregate的方式計算loss和gradient val (cumGradient, cumLoss) = trainData .treeAggregate((new DenseVector(x.length), 0.0)) (seqOp, combOp) val resGradient = new DenseVector(cumGradient.toArray.map(_ / sampleNum)) (cumLoss / sampleNum, resGradient) }calculate接口輸入?yún)?shù)是 w ,遍歷訓練數(shù)據(jù)并返回 loss 和 cumGradient。其中 w 和 cumGradient都是BreezePSVector;計算梯度時,需要將 Pull 到本地,本地的gradient值,需要通過PSVector的incrementAndFlush方式Push到遠程PS上的cumGradient向量。
case class PSCost(trainData: RDD[Instance]) extends DiffFunction[BreezePSVector] { override def calculate(w: BreezePSVector): (Double, BreezePSVector) = { // 初始化gradient向量:cumGradient val cumGradient = pool.createZero().mkBreeze() // 計算梯度和loss val cumLoss = trainData.mapPartitions { iter => // pull模型 w 到 executor 本地 val localW = w.toRemote.pull() val (gradient, loss) = calculateGradAndLoss(iter, localW) // incement本地的grad到PS的cumGradient cumGradient.toRemote.incrementAndFlush(gradient) Iterator.single(loss) }.sum() cumGradient *= 1.0 / sampleNum (cumLoss / sampleNum, cumGradient) } }4.4 快——性能強勁
我們分別實現(xiàn)了SGD、LBFGS、OWLQN三種優(yōu)化方法的LR,并在Spark和Spark on Angel上做了實驗對比。
該實驗代碼請前往Github SparseLRWithX.scala。
說明1:三組對比實驗的資源配置如下,我們盡可能保證所有任務在資源充足的情況下執(zhí)行,因此配置的資源比實際需要的偏多;
說明2:執(zhí)行Spark任務時,需要加大spark.driver.maxResultSize參數(shù);而Spark on Angel就不用配置此參數(shù)。
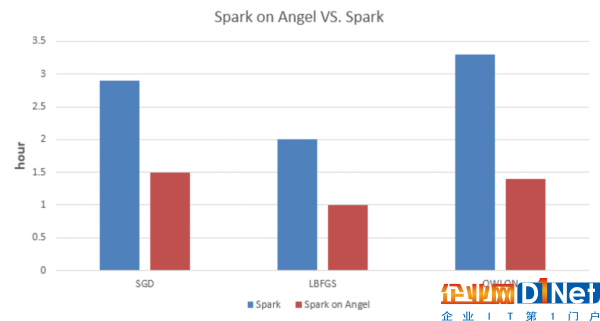
如上數(shù)據(jù)所示,Spark on Angel相較于Spark在訓練LR模型時有50%以上的加速;對于越復雜的模型,其加速的比例越大。
5.結語
Spark on Angel的出現(xiàn)可以高效、低成本地克服Spark在機器學習領域遇到的瓶頸;我們將繼續(xù)優(yōu)化Spark on Angel,并提高其性能。也歡迎大家在Github上一起參與我們的改進。
Angel項目Github:Angel,喜歡的話到Github上給我們Star。
感謝蔡芳芳對本文的審校。

















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號