









Maluuba是微軟旗下一家致力于通用人工智能的公司。近日,該公司新發布了一個開放的對話數據集。該數據集基于假期預定的場景——具體來說,查找航班和賓館。
近年來,聊天機器人的數量越來越多,尤其是自一年前Facebook向這些機器人開放Messenger平臺以來。目前,大多數機器人僅支持簡單的順序交互。類似旅行規劃這樣的高級場景對聊天機器人來說仍然很困難。借助這個數據集,Maluuba(最近被微軟收購)幫助研究人員和開發人員讓他們的聊天機器人更智能。
Maluuba讓兩個人在聊天室中對話并收集了這些數據。一個人扮演用戶,另一個人充當計算機。用戶試圖查找特價機票,另一個充當聊天機器人的人使用數據庫檢索信息。交互只包含文本(沒有口語交互),研究人員有意識地選擇了這個方法。大部分人都喜歡打字,而不是說話,那也就是說,這份數據集就遠離了質量不高的語音識別和背景噪聲。該數據集包含1369句有關旅行規劃的對話,可以免費下載。
Maluuba還提供了一種表示對話的方式。讓旅行規劃更加困難的是,用戶經常改變談話主題。你可能同時討論去滑鐵盧、蒙特利爾、多倫多的計劃。對于我們人類而言,將人們在交談中制定的不同計劃分開并不困難。不過,如果用戶在預訂之前探討了多個選項,那么計算機往往會遇到問題。當你突然輸入一個新目的地,大多數聊天機器人都會忘記你剛剛談論的所有內容。下面左邊那副圖是“傳統”聊天機器人的交互。當用戶說出一個新城市時,機器人會忘記舊城市。右側是微軟發布的數據集中出現的一個模式:用戶在做出決定之前比較多個城市。
[點擊查看大圖]
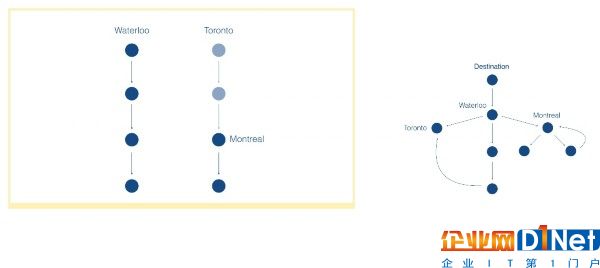
這就是為什么微軟引入了所謂的“框”。每次用戶修改了以前設置的值,向導程序就會新建一個框。每個跟蹤框會記錄所有用戶提到的不同的約束集合。這讓你可以同時談論預定到蒙特利爾最貴200美元的旅行和到多倫多最貴300美元的旅行。這種會話記憶向著構建可以在在線旅游場景中幫助用戶探討不同航班的機器人邁進了一步。
傳統的聊天機器人,就像你可以在Pandorabots上創建的機器人那樣,會設法將對話導向所謂的“格位填充(slot-filling)”。機器人會設法在你給出的答案中找出一些屬性(如名字和年齡)。一旦聊天機器人知道了這些屬性,對話就會繼續,機器人會設法填充下一個格位。其他公司,如被Facebook收購的Wit,已經通過“故事”把這種理念向前推進了一步。這個位于語言理解層之上的“柔性層(flexible layer)”已經創建了“讓人感覺更自然的”對話。Maluuba發布的數據集更進一步,它側重于進行同時涉及多個主題的對話。
3月28日,Tim Peterson發表了一篇文章,探討目前聊天機器人的缺點。該數據集解決了Peterson談到的其中一個問題:由于聊天機器人的用戶少導致聊天機器人開發人員可以獲得的數據少。由于許多聊天機器人在理解自然語言時都有問題,所以開發人員經常向他們的機器人添加“快速回復”。有了這些回復,用戶可以從一個機器人確定可以理解的、較小的選項集中選擇他們的回復。雖然這特性個對于那些知道要說什么的用戶有用,但那同時也意味著,對于那些相對不常見的用戶查詢,永遠都不會開發相應的回復。
[點擊查看大圖]
查看英文原文:Microsoft Releases Dialogue Dataset to Make Chatbots Smarter
















 京公網安備 11010502049343號
京公網安備 11010502049343號