










谷歌公布 TPU 論文(被ISCA-17 接收)引發新一輪討論,連英偉達CEO黃仁勛都親自撰文回應。使用 TPU 代表了谷歌為其人工智能服務設計專用硬件邁出的第一步,為特定人工智能任務制造更多的專用處理器很可能成為未來的趨勢。TPU 推理性能卓越的技術原理是什么,TPU 出現后智能芯片市場格局又會出現哪些變化?中國在智能芯片市場上的位置如何?
中科院計算所研究員包云崗指出,計算機體系結構旗艦年會ISCA是各大公司展示硬實力的舞臺,每年的關鍵技術對信息產業的推動作用不容忽視。寒武紀創始人兼CEO陳天石指出,需要密切注意谷歌 TPU 給智能領域帶來的新生態,“是與之融合,還是與之抗衡,是每個芯片公司需要考慮的問題”。
如果說現在是 AI 走出實驗室,走進三百六十行紛紛落地的時代,那么支撐這場技術應用大浪潮的背后,正是芯片、硬件行業的茁壯發展和慘烈競爭。要將一款芯片研發出來并且推向市場,需要幾十億乃至幾百億美元的巨資,更不用說這伴隨的人力資源和研發時間。很多的項目都死掉了。而把握住并且乘上了深度學習這股浪潮的 GPU 巨頭英偉達,現在是以季度乃至月為單位往外推出新品,其速度和效率令人咂舌。GPU 在深度學習市場勢不可擋。
上周,谷歌公布了張量處理器(TPU)的論文——TPU 已經在谷歌數據中心內部使用大約兩年,而且TPU 在推理方面的性能要遠超過 GPU(“盡管在一些應用上利用率很低,但 TPU 平均比當前的 GPU 或 CPU 快15~30倍,性能功耗比高出約 30~80 倍”)——不啻一塊巨石,在業內激起了又一波圍繞深度學習專用加速器的熱浪。TPU 的出現以及谷歌研發芯片這一舉動本身,都對整個智能產業有著深遠的意義。
任何一款新的芯片都值得我們關注,因為這影響著千千萬萬的應用和使用這些應用人。下面,我們從谷歌 TPU 的誕生講起,全面回顧這款芯片及其出現在智能領域代表的新的趨勢和重要意義。
TPU 誕生:從谷歌決定自己打造更高效的芯片說起
2011年,Google 意識到他們遇到了問題。他們開始認真考慮使用深度學習網絡了,這些網絡運算需求高,令他們的計算資源變得緊張。Google 做了一筆計算,如果每位用戶每天使用3分鐘他們提供的基于深度學習語音識別模型的語音搜索服務,他們就必須把現有的數據中心擴大兩倍。他們需要更強大、更高效的處理芯片。
他們需要什么樣的芯片呢?中央處理器(CPU)能夠非常高效地處理各種計算任務。但 CPU 的局限是一次只能處理相對來說很少量的任務。另一方面,圖像處理單元(GPU) 在執行單個任務時效率較低,而且所能處理的任務范圍更小。不過,GPU 的強大之處在于它們能夠同時執行許多任務。例如,如果你需要乘3個浮點數,CPU 會強過 GPU;但如果你需要做100萬次3個浮點數的乘法,那么 GPU 會碾壓 CPU。
GPU 是理想的深度學習芯片,因為復雜的深度學習網絡需要同時進行數百萬次計算。Google 使用 Nvidia GPU,但這還不夠,他們想要更快的速度。他們需要更高效的芯片。單個 GPU 耗能不會很大,但是如果 Google 的數百萬臺服務器日夜不停地運行,那么耗能會變成一個嚴重問題。
谷歌決定自己造更高效的芯片。
TPU 首次公開亮相,號稱“把人工智能技術推進 7 年”
2016年5月,谷歌在I/O大會上首次公布了TPU(張量處理單元),并且稱這款芯片已經在谷歌數據中心使用了一年之久,李世石大戰 AlphaGo 時,TPU 也在應用之中,并且谷歌將 TPU 稱之為 AlphaGo 擊敗李世石的“秘密武器”。
作為芯片制造商的大客戶,谷歌揭幕 TPU 對 CPU 巨頭英特爾和 GPU 巨頭英偉達來說都是不小的商業壓力。為了適應市場趨勢,英特爾和英偉達都在去年分別推出了適用于深度學習的處理器架構和芯片意欲擴張當下的市場份額,但看來“專用芯片”的需求比他們預計還要更深。
不僅如此,單是谷歌自己打造芯片的這一行為,就對芯片制造商構成了巨大影響。尤其是谷歌基礎設施副總裁 Urs Holzle 在 2016 年的發布會上表示,使用 TPU 代表了谷歌為其人工智能服務設計專用硬件邁出的第一步,今后谷歌將設計更多系統層面上的部件,隨著該領域逐漸成熟,谷歌“極有可能”為特定人工智能任務制造更多的專用處理器。
當時,Holzle 對 TechCrunch 記者說:“有些時候 GPU 對機器學習而言太通用了。”
顯然,面向機器學習研發專用的處理器已經是芯片行業的發展趨勢。

2016年谷歌首次公開TPU時給出的圖片,當時出于保密考慮,關鍵部分都蓋著散熱片,看不出具體設計。
當時,TPU 團隊主要負責人、計算機體系結構領域大牛 Norm Jouppi 介紹,TPU 專為谷歌 TensorFlow 等機器學習應用打造,能夠降低運算精度,在相同時間內處理更復雜、更強大的機器學習模型并將其更快投入使用。Jouppi 表示,谷歌早在 2013 年就開始秘密研發 TPU,并且在一年前將其應用于谷歌的數據中心。2016年 TPU 消息剛剛公布時,Jouppi 在 Google Research 博客中特別提到,TPU 從測試到量產只用了 22 天,其性能把人工智能技術往前推進了差不多 7 年,相當于摩爾定律 3 代的時間。
在公布自行設計 TPU 芯片時,Google 并沒有透露更多有關芯片架構或功能的信息,所以引發了許多猜測。上周,谷歌終于公開了 TPU 的論文,我們也終于得以了解 TPU 的技術細節。當然,這也掀起了新一輪的討論熱潮。
TPU 重磅論文解密架構設計,75 位聯合作者,“能效比CPU/GPU 高30~80倍”
谷歌上周公布的 TPU 論文《在數據中心分析中對張量處理器性能進行分析》。論文聯合了一共 75 位作者,由大牛 Norman Jouppi 領銜,堪稱“重磅”。

摘要
許多架構師認為,現在只有領域定制硬件(domain-specific hardware)能帶來成本、能耗、性能上的重大改進。本研究評估了自2015年以來部署在各數據中心,用于加速神經網絡(NN)的推理過程的一種定制 ASIC 芯片——張量處理器(TPU)。TPU 的核心是一個65,536的8位矩陣乘單元陣列(matrix multiply unit)和片上28MB的軟件管理存儲器,峰值計算能力為92 TeraOp/s(TOPS)。與CPU和GPU由于引入了Cache、亂序執行、多線程和預取等造成的執行時間不確定相比,TPU 的確定性執行模塊能夠滿足 Google 神經網絡應用上 99% 相應時間需求。CPU/GPU的結構特性對平均吞吐率更有效,而TPU針對響應延遲設計。正是由于缺乏主流的CPU/GPU硬件特性,盡管擁有數量巨大的矩陣乘單元 MAC 和極大的偏上存儲,TPU 的芯片相對面積更小,耗能更低。
我們將 TPU 與服務器級的 Intel Haswell CPU 和 Nvidia K80 GPU 進行比較,這些硬件都在同一時期部署在同個數據中心。測試負載為基于 TensorFlow 框架的高級描述,應用于實際產品的 NN 應用程序(MLP,CNN 和 LSTM),這些應用代表了我們數據中心承載的95%的 NN 推理需求。盡管在一些應用上利用率很低,但 TPU 平均比當前的 GPU 或 CPU 快15~30倍,性能功耗比(TOPS/Watt)高出約 30~80 倍。此外,在 TPU 中采用 GPU 常用的 GDDR5 存儲器能使性能TPOS指標再高 3 倍,并將能效比指標 TOPS/Watt 提高到 GPU 的 70 倍,CPU 的 200 倍。
也就是在這篇論文中,谷歌公布了第一代 TPU(谷歌于 2015 年就在其數據中心部署)的設計圖及其他細節。

谷歌上周公布的論文中,給出了第一代 TPU 的電路板細節。可以插入服務器的一個SATA盤位中,但卡使用的是PCIEGen3x16連接。
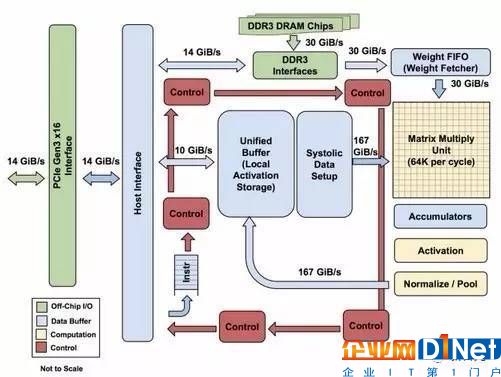
TPU 模塊圖。主要的計算部件是右上角的黃色矩陣乘單元。輸入是藍色的權重數據隊列FIFO和藍色的統一緩沖(Unified Buffer),輸出是藍色的累加器(Accumulators)。黃色的激活單元在累加之后執行非線性函數,然后數據返回統一緩沖區。
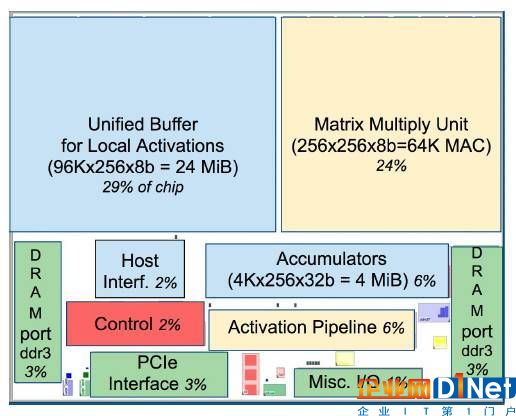
TPU晶圓的布局規劃。形狀與圖1中一致。亮(藍)色的數據緩沖占據晶圓面積的37%,亮(黃)色的計算部分占據30%,中(綠)色I/O部分占10%,而暗(紅)色的控制僅占2%。控制部分在CPU或者GPU中都比TPU更大(并且也更難設計)。
谷歌稱 TPU 為張量處理單元,專為 TensorFlow 定制設計,TensorFlow 是 Google 的一個開源機器學習軟件庫。
這篇論文將第一代的 TPU 與部署在 Google 的相同數據中心的服務器級 Intel Haswell CPU 和 Nvidia K80 GPU 進行了性能對比。由于 TPU 是專為推理投產一個定制的ASIC芯片(并購買市售的GPU用于訓練),因此論文中的性能比較也僅限于推理操作。
關于“推理”和“訓練”兩者之間的關聯,我們可以看論文里的解釋:
神經網絡的兩個主要階段是訓練(Training或者學習Learning)和推理(inference或者預測Prediction),也可以對應于開發和產品階段。開發人員選擇網絡的層數和神經網絡類型,并且通過訓練來確定權重。實際上,當前的訓練幾乎都是基于浮點運行,這也是GPU為何如此流行的原因之一。一個稱為量化(quantization)的步驟,將浮點數轉換為很窄僅使用 8 個數據位的整數,對推理過程通常是足夠了。8 位的整數乘法比IEEE 754標準下16位浮點乘法降低 6 倍的能耗,占用的硅片面積也少 6 倍;而整數加法的收益是13倍的能耗與38倍的面積。
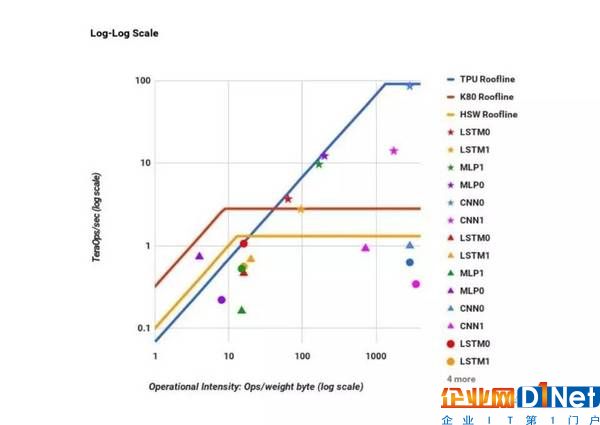
TPU(藍線)、GPU(紅線)和 CPU(金線)的性能功耗比。
論文在速度和效率兩方面進行了比較。速度以存儲帶寬函數每秒執行的 tera-操作測量。TPU 比 CPU 和 GPU 快 15~30 倍。效率則以每瓦特能量消耗執行的 tera-操作計算。TPU 比 CPU 和 GPU 效率高 30~80 倍。
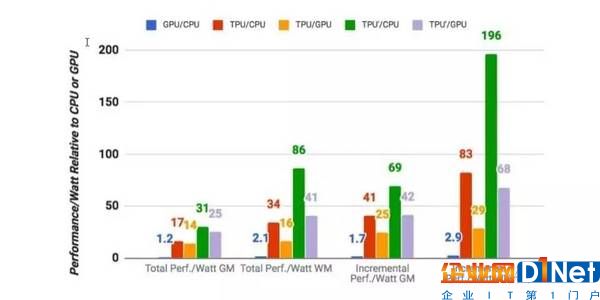
TPU,GPU,CPU 和改進的 TPU 的性能對比。
GPU(藍色)和TPU(紅色)相對于CPU的能效比(功耗/瓦,TDP),以及 TPU 相對于GPU 的能效比。TPU’是改進的TPU。綠色代表改進的 TPU 與 CPU 對比的性能,淺紫色代表改進的 TPU與 GPU 對比性能。總和數據(Total)包含了主機服務器的功耗,增量數據(Incremental)則不包含主機服務器的功耗。GM 和 WM 是幾何與加權平均數據。
對硬件研究的啟示:軟硬件協同開發可能進一步提升設計門檻
新智元轉載了 NUDT 研究組對 TPU 論文的專業分析,文章以論文《在數據中心中對張量處理器進行性能分析》為基礎,從專業的角度總結了一些啟示。
現在我們引用如下:
底層硬件設計,特別是以處理器設計為代表的研發工作門檻并未降低。但由于無論專用和通用處理器都需要得到最終用戶的認可,考慮軟件的真實需求,軟硬件協同開發可能進一步提升設計門檻。(即:硅碼農還是有市場需求的)
相比于神經網絡模型、軟件框架和應用的當前的進化速度,傳統ASIC半定制或者全定制的開發周期和速度難以加速。但仍然有可能保持專用設計一定的壽命,并通過性能模型評估確定改進方案。(即:研發還是老套路,但會更困難。要硅馬跑得快又少吃草或最好不吃草的情況只會惡化)
真實應用的部署和數據收集是必需的,而且有極強的說服力,當然最終目的是獲得處理器目標用戶的認可。(即:總有人能做出叫好又叫座的設計,有足夠資源配合可能性更高些)
。在論文發布之前,甚至在初步閱讀論文時很多評論表示,TPU設計沒有細節,連照片都蓋著散熱片。但仔細閱讀論文能看到,Google在2015年就提交了相關的論文申請,在AlphaGO下棋的時候就可以通過專利局網站看到相關專利了。(即:先進商業公司和上市公司的知識產權保護,購并和調查并非是裝樣子的。)
專業知識,仍然是一切的基礎。包括TPU計算核心:由65536個乘法器構成的256x256矩陣單元,其脈動執行 Systolic Execution 都能夠追溯到1984年哈佛大學研究人員在TOC上發表的論文。在NUDT求學過的應該很容易聯想起向量、行波流水等概念。(即:學習和專業知識的儲備依然有價值)
專家看法:要注意谷歌 TPU 給智能領域帶來的新生態
中科院計算所研究員包云崗撰文評論稱:
一、計算機體系結構和算法是信息技術進步的兩大引擎。過去40年處理器性能提升了1,000,000倍,單臺計算機內存容量增長了1,000,000,000倍。這是什么概念,上世紀70年代語音識別算法只能放幾十個單詞的語音到內存中進行訓練,但今天可以成千上萬人的幾十億個單詞的語音放到內存中進行訓練。大數據需要大處理能力。
二、處理器體系結構研究有時會顯得很神奇,同樣的算法、同樣的晶體管,不同的組織方式性能就會讓算法運行起來有幾十到幾百倍的差別。有時又會顯得很無奈,使勁優化也只能提升1%的性能。但不管如何,處理器終究還是“大國重器”或“貴司重器”,這是知識密集型和資本密集型的活,不是一般公司可以玩得起,搞得敢做體系結構研究的人也越來越少。如何建起人才培養生態、吸引更多學生加入體系結構研究,需要業界更多支持。
三、計算機體系結構旗艦年會ISCA每年只錄50篇左右論文,但對信息技術的推動作用不容忽視,成為各大公司展示硬實力的舞臺——微軟在2014年ISCA上發表其FPGA在數據中心應用的論文,引領全世界一波FPGA熱潮;Google 則是在今年ISCA上公布張量處理器TPU細節;而10年前則有D.E. Shaw在2007年ISCA上發表了其黑科技——分子動力學專用機Anton;而國內計算所也是在2016年ISCA首次發布了面向神經網絡處理器的寒武紀指令集。
寒武紀創始人兼CEO陳天石在接受新智元專訪時稱:
一、谷歌 TPU 肯定還會繼續做下去
在TPU的ISCA2017論文中,Google引用了DianNao全系列學術論文外加ACM旗艦雜志Communications of the ACM刊登的DianNao系列綜述,同時還專門用英文注釋這幾個名字的含義(Big computer, general computer, vision computer),對我們前期工作顯示了相當的尊重。Google還引用了寒武紀團隊發表的Cambricon指令集論文(國際上首個智能處理器指令集),從側面反映Google同行一直在跟蹤我們最新的工作。
Google TPU未來肯定還會繼續做下去。我們的早期學術合作者Olivier Temam教授在幾年前加入了Google,許多業界的朋友猜測未來DianNao系列的學術思想會與TPU發生某種程度的融合。我們對此樂見其成,也非常期待與國際同行在這一領域同場競技。
二、脈動陣列架構使 TPU 處理卷積比較高效,但 TPU 性能做到極致還有距離
脈動陣列架構處理卷積會比較高效,但在其他一些workload上效率可能又不大好。因此從效率角度說,TPU的性能離做到極致還有距離。TPU的優秀性能與其采用了8位運算器是分不開的。這樣做可以使單位面積的芯片能擺放更多的運算器,對內存帶寬的需求也大大降低,這使得TPU獲得了很好的絕對性能。當然,降低運算器的位寬并不是提升性能、降低面積功耗的唯一辦法。稀疏化神經網絡是另外一條道路。在稀疏神經網絡中,由于模型每層的稀疏度可以在[0,1]連續區間變化,這使得整個模型的識別精度和模型的運算/訪存量之間的tradeoff是連續可控的。相比之下,直接把模型降到8位,可能會帶來不可控的識別精度丟失。當前深度學習發展日新月異,我們認為應對兩種思路兼容并包。
三、應用層面的深刻變化催生了當前這一輪芯片的百花齊放
Google 這樣的公司,從最開始使用 CPU 這樣的通用芯片,過渡到 GPU 與 FPGA,但是FPGA無法提供想象的速度,又再過渡到專屬的 ASIC來面對應用的需求。而Facebook 走的是全GPU路線,微軟在開發 FPGA。每個廠商肯定都不會把雞蛋放在一個籃子里。例如Google雖然自己做了TPU,但肯定還是會大量采購CPU和GPU。目前這一輪芯片的百花齊放其實根源是應用層面發生了深刻的變化。未來待應用層面相對穩定以后,芯片的定位和市場會進入一個穩定期。
Google應該主要是將TPU應用于人工智能云服務,而不會直接出售TPU。對于芯片領域的創業公司來說,不用太擔心Google會直接搶飯碗,但是需要密切注意TPU給智能領域帶來的新生態。是與之融合,還是與之抗衡,是每個芯片公司需要考慮的問題。
關于泛AI領域,中國的成就有目共睹。這里我更想說一說處理器這塊(也呼吁社會各界給予更多關注):目前我國的處理器架構領域學術和工程水平不斷提高,在許多方向上(不光是智能處理器這塊)已經和國際同行難分伯仲。例如通用CPU這塊,我們國內有龍芯、申威、飛騰,有兆芯和海光,也有華為海思這樣的民企,已經是百花齊放。我堅信國內同行的共同努力最終一定會帶動我國整個處理器行業的跨越式發展,在未來進一步解決了工藝瓶頸后,一定可以做到和美國并駕齊驅。
英偉達黃仁勛親自撰文將最新GPU與TPU對比,表示不服反被吐槽
有趣的是,英偉達 CEO 黃仁勛昨天親自在官博發表署名文章,將 TPU 和英偉達的最新品 P40 做了比較——盡管外界都已經意識到,TPU 論文里沒有將第一代 TPU 跟英偉達最新款的 GPU 做比較,但黃仁勛顯然還是忍不住。
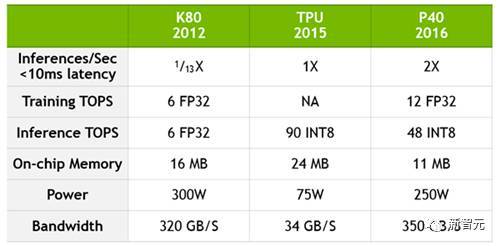
黃仁勛文章的結果是,英偉達 Tesla P40 在 GoogleNet 推斷任務中的性能是 Google TPU 的 2倍。不僅如此,P40 的帶寬也是 TPU 的十倍還多。
但是,這篇文章并沒有如想象中那樣“更新”GPU與 TPU 的性能,而是引來了各界的無情吐槽。在Twitter、Reddit 和 HackerNews 等技術網站,網友紛紛指出,首先,相同情況下,TPU 的能耗是 75W,而 P40 的能耗是 250W。此外,谷歌論文里的是第一代 TPU(2015 年部署在谷歌數據中心),現在肯定已經升級好幾代了——黃仁勛用最新 GPU與第一代TPU對比,GPU性能更優也無疑是必然的結果。
不過,黃仁勛在文章里指出的以下幾點值得注意:
“雖然Google和NVIDIA選擇了不同的開發道路,但我們的方法中還是有一些共同點。特別是:
人工智能需要加速計算。在摩爾定律放緩的時代,加速器提供了深度學習重要的數據處理需求。
張量處理是深度學習訓練和推理性能的核心。
張量處理是企業在構建現代數據中心時必須重點考慮的新工作量(wordload)。
加速張量處理可以大大降低修建現代數據中心的成本。
TPU 是深度學習的未來嗎?
鑒于深度學習近年來強勁的影響力,連《福布斯》這樣的大眾媒體都對谷歌TPU 進行了分析報道,作者 Kevin Murnane 指出,論文中給出的這些對比的數字非常厲害,但是必須注意以下幾點,才能說 TPU 是深度學習的未來。
首先,Google 在測試中使用的是 2015年初生產的芯片。自那以后 Nvidia 和 Intel 都對自己的芯片進行了升級改進,因此與現在的芯片比較結果會怎樣我們還無法知道。不過,盡管如此,兩年前 TPU 的優勢就已經如此巨大,Intel 和 Nvidia 不大可能把這個差距完全消除。
還有一個更重要的考慮因素是芯片性質的比較。Intel 的 CPU 是專為靈活性設計的通用芯片,一次運行的進程數量有限。Nvidia 的 GPU 是專為一次運行許多神經網絡計算設計的通用芯片。而 Google 的 TPU 是專門用于在 TensorFlow 中執行特性功能的 ASIC(專用集成電路)。
CPU 的靈活性最大,它可以運行各種各樣的程序,包括使用各種軟件庫的深度學習網絡執行的學習和推理。GPU 不像 CPU 那樣靈活,但它在深度學習計算方面更好,因為它能夠執行學習和推理,并且不局限于單個的軟件庫。該測試中的 TPU 則幾乎沒有靈活性。它只能在 TensorFlow 中執行推理,但它的性能非常好。
早期的生成深度學習網絡
深度學習計算中的芯片部署都不是零和博弈。現實世界的深度學習網絡需要系統的 GPU 與其他 GPU 或諸如 Google TPU 之類的 ASIC 通信。GPU 是理想的工作環境,具有深度學習所需的靈活性。但是,當完全專用于某個軟件庫或平臺時,則 ASIC 是最理想的。
谷歌的 TPU 顯然符合這樣的要求。TPU 的卓越性能使得 TensorFlow 和 TPU 很可能是一起升級的。雖然谷歌官方已經多次明確表示,他們不會對外銷售 TPU。不過,利用 Google 云服務做機器學習解決方案的第三方可以得益于 TPU 卓越性能的優勢。
智能芯片市場格局一變再變,谷歌 TPU 的出現讓面向神經網絡/深度學習特定領域加速的芯片趨勢更加明顯。高端 AI 應用需要強大的芯片做支撐。軟硬件缺了哪一塊中國的智能生態也發展不起來。中國處理器學術和工程都在不斷提高,我們期待中國芯早日出現在世界舞臺與國際同行競技。
參考資料
包云崗,《說點Google TPU的題外話》
CPUinNUDT,《基于論文,對谷歌 TPU 的最全分析和專業評價》
https://www.forbes.com/sites/kevinmurnane/2017/04/10/the-great-strengths-and-important-limitations-of-googles-machine-learning-chip/#2ff4fbca259f
https://blogs.nvidia.com/blog/2017/04/10/ai-drives-rise-accelerated-computing-datacenter/

3月27日,新智元開源·生態AI技術峰會暨新智元2017創業大賽頒獎盛典隆重召開,包括“BAT”在內的中國主流 AI 公司、600多名行業精英齊聚,共同為2017中國人工智能的發展畫上了濃墨重彩的一筆。
訪問以下鏈接,回顧大會盛況:
阿里云棲社區:http://yq.aliyun.com/webinar/play/199
愛奇藝:http://www.iqiyi.com/l_19rrfgal1z.html
騰訊科技:http://v.qq.com/live/p/topic/26417/preview.html

















 京公網安備 11010502049343號
京公網安備 11010502049343號