


上周,谷歌發(fā)布了一篇文章,詳細(xì)對(duì)他們的第一代張量處理單元(TPU)與英特爾的一款GPU、英偉達(dá)的一款GPU進(jìn)行了速度與效能上的對(duì)比。這款TPU相對(duì)于GPU和CPU來說有非常明顯的優(yōu)勢,這引起了眾多媒體的關(guān)注。近日,英偉達(dá)的CEO、聯(lián)合創(chuàng)始人黃仁勛在英偉達(dá)官方博客上發(fā)表了一篇文章,以此回應(yīng)谷歌的測試結(jié)果。
谷歌的TPU是專為谷歌機(jī)器學(xué)習(xí)平臺(tái)Tensorflow 設(shè)計(jì)的ASIC(專用集成電路),谷歌用來測試的TPU版本在2015年被應(yīng)用在他們的數(shù)據(jù)中心。為了體現(xiàn)對(duì)比的公平,谷歌將該TPU與當(dāng)代的英偉達(dá)Kepler K80 GPU和英特爾Haswell CPU進(jìn)行了比較。
這個(gè)做法看起來確實(shí)公平,不過根據(jù)黃仁勛在博客中的說法,谷歌用來做對(duì)比的是舊版芯片。英偉達(dá)目前最新的Pascal芯片是Kepler兩代以后的版本了,而且英特爾的Kaby Lake架構(gòu)也已經(jīng)超過Haswell三代。此外,Kepler不像Pascal,并沒有在機(jī)器學(xué)習(xí)應(yīng)用上作最佳化的使用,而谷歌定制的這種ASIC就只是用來進(jìn)行深度學(xué)習(xí)應(yīng)用的。
筆者認(rèn)為,芯片與芯片之間的對(duì)比,已經(jīng)被先進(jìn)的技術(shù)所廢棄。英偉達(dá)和英特爾已經(jīng)公布了他們新一代芯片的架構(gòu)細(xì)節(jié),谷歌卻一直對(duì)被測的2015 TPU是否已經(jīng)被其他更強(qiáng)大的芯片超越而保持沉默。當(dāng)然,谷歌會(huì)把2015 TPU這個(gè)秘密泄漏出來,部分原因是他們也許有了一個(gè)新的秘密。
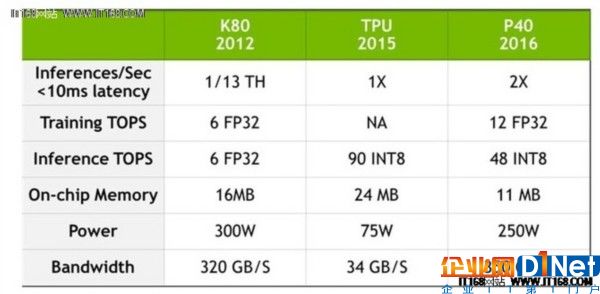
英偉達(dá)發(fā)表了上面那個(gè)表格,借此說明他們的Pascal架構(gòu)在與谷歌2015 TPU的比較中已經(jīng)超越了Kepler。在這個(gè)表格中,TOPS引用了浮點(diǎn)運(yùn)算(每秒數(shù)以億萬計(jì)的操作),F(xiàn)P表示“浮點(diǎn)數(shù)”,INT表示“整數(shù)”。
在表格中可以看到,Pascal比Kepler強(qiáng)大了很多,不過我們并不知曉Pascal是如何與谷歌TPU進(jìn)行對(duì)比的。
黃仁勛在博客中煞費(fèi)苦心地指出,谷歌和英偉達(dá)的做法是殊途同歸的——都是為了促進(jìn)芯片技術(shù)的發(fā)展,以使其能夠支持大型人工只能的大規(guī)模計(jì)算。
速度和能效是芯片能否用于大量AI型設(shè)備的重要參數(shù)。不過,使芯片間的對(duì)比有意義的唯一方法是在芯片設(shè)計(jì)時(shí)使其適應(yīng)相同的角色。如果芯片A和芯片B都沒有獲得或丟失某些額外功能,那么這兩者之間的對(duì)比才真正有意義。即便是功能不同的問題解決了,除了速度和能效之外的因素也必須考慮在內(nèi)。

數(shù)據(jù)中心規(guī)模的AI中,TPU、GPU和CPU都是不可替換的,因?yàn)樗鼈儞碛懈髯圆煌淖饔谩PU和GPU從CPU中接收指令,沒有CPU它們就無法實(shí)現(xiàn)各自的功能;而CPU和GPU是支持多種軟件平臺(tái)執(zhí)行各種任務(wù)的常規(guī)芯片;ASIC則建立在為特殊應(yīng)用工作的基礎(chǔ)之上。值得注意的是,上面的表格中TPU一列,Training TOPS欄中為“NA”(not applicable,即不適用)。這表示2015 TPU專門用于運(yùn)行在Tensorflow上深度學(xué)習(xí)模型的推理,并不能進(jìn)行AI訓(xùn)練。
特別要指出的是,數(shù)據(jù)中心規(guī)模的AI需要所有這三種芯片的有效使用。哪個(gè)芯片用于什么地方取決于運(yùn)行在數(shù)據(jù)中心的機(jī)器以及AI軟件如何配置。廠商們將重點(diǎn)放在“芯片大戰(zhàn)”,可能對(duì)于搶明天的頭條有些作用,但對(duì)數(shù)據(jù)中心來說,其意義是非常有限的。






GPU與谷歌TPU究竟孰強(qiáng)孰弱")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)