









距離Google發布TPU也有一個星期了,掐指一算,國內眾媒體和大眾的解讀的熱情也差不多該降下來了。我想在這里說點大家可能不愿意聽的。
噢,我當然不是說這次發布沒有意義,雖然TPU已經是一個開展了數年,甚至也實用了一兩年了的項目,包括雷鋒網在內的媒體在之前進行過無數次的報道了。但在這之前并沒有多少人能了解它的具體結構和細節指標。大家對它的看法多數還是停留在猜想中。這次谷歌公布了許多非常詳細的技術指標,確實能讓許多對TPU有好奇心的人一飽眼福。
但要說再往深一層里解讀,我實在是覺得沒有必要。大家都知道我國語文教育的一大特點就是喜歡讓我們解讀文章背后的意思,有時候我禁不住會懷疑,是不是正因為當初語文學得好的那一批人長大后很多真正從事了與寫作有關的行業,才導致一旦有比芝麻稍微大一點的事發生,各種解讀文就如雨后春筍般冒了出來,是閱讀理解做習慣了?好吧,老實說,這個地圖炮開的我自己也覺得很沒有意思,實在是因為我看到有些媒體一如既往的秉持小事化大,大事化炸的風格。尤其是一篇公眾號的文章說谷歌在TPU的對外宣傳上吹的“天花亂墜”,并由此直線上升到批判西方一向善于“炒作一些概念”,讓我感覺到有些話不吐不快:谷歌畢竟就只是發了一篇描述一個數年前就開始的項目的內部結構和一些性能參數的論文和一篇提煉了其中一些內容的博文而已啊。要說吹的天花亂墜,恐怕國內外的某些媒體同行的功勞更大一些吧。
沒錯,這次發布確實可以算是件大事,但硬要說它對AI的未來有什么意義,會對現在的運算芯片市場有什么影響,體現了Google什么什么方面的實力……真不一定有必要。很大程度上,這些略顯強行的解讀并沒有什么意義。這個被谷歌“吹”的“天花亂墜”的“概念”,只不過是市場發展一個很自然的產物罷了。
TPU的架構是不是以前就有?
是的,TPU采用的脈動陣列處理結構最早由美籍華人計算機科學家孔祥重(H.T.Kung)和澳大利亞計算機科學家及數學家Richard P. Brent提出,它與現在流行的SIMD結構(單指令多數據流)結構有相似之處,但又有著明顯的區別。簡單解釋一下的話,就是在脈動陣列處理結構下,數據向負責處理的運算陣列(運算陣列中有許多個獨立的運算單元)傳遞和處理的方式是有嚴格的流程規定的,以確保能將所有芯片的處理能力最大限度的發揮出來,在這種計算方式中,需要運算的數字就像流水一樣井然有序的“流”進每個處理器中,并得到這些處理器的同時處理。當全部的數字都“流”進去的時候,計算也就在同時完成了。這樣精細安排結構的代價就是其通用性受到了限制。80年代初,中科院的前輩們就曾將這種架構的計算設備用在石油勘探上過。
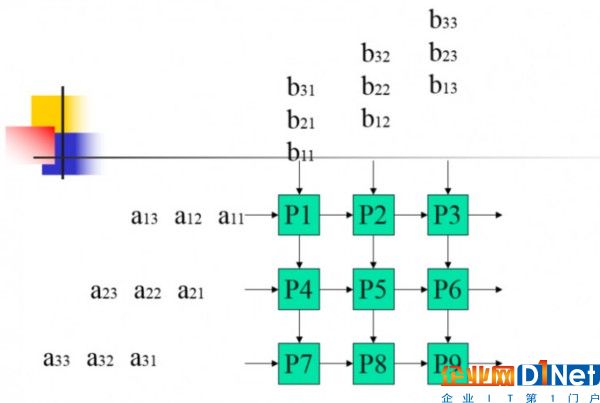
(如果你有一定線性代數基礎的話,應該可以理解,上面就是脈動陣列處理機在進行矩陣乘法運算時的過程,舉個例子,其中的a11每次向右移一格,剛好依次與自己在同一格相遇的b11、b12、b13相乘,而b11則是每次向下一格,剛好依次與a11、a21、a31相乘,以此類推)
這個架構在今天的日常生活中并不多見。相比之下通用性更好的SIMD成為了今天的主流。而通用性或許是SIMD勝出很關鍵的一個原因,畢竟相對于在某個領域的速度快點,更多人需要的是一種通用的能滿足他們各種需求的計算設備,你不可能要求每個人要用電腦來做什么事之前先根據自己的需求把電路的結構優化一下。
不過當今的世界對于計算能力的需求其實處于一個很矛盾的狀態。通用平臺早就已經能滿足大部分人的需求,以至于像做手機這樣的事都慢慢被大家戲稱為搭積木——SOC已經給手機需要的絕大多數運算量提供了一個很好的解決方案,而且這個運算量也已經慢慢超出了大眾使用的需求,更不用說電腦了。但是在另一方面,在一些科研的前沿領域,比如深度學習。計算量卻一直顯得捉襟見肘,訓練一個深度學習算法動輒需要幾周甚至幾個月。當摩爾定律指出的硬件發展規律慢慢開始表現出瓶頸,開始有人嘗試使用一些不那么主流的架構,或者研發一些新的架構。TPU就屬于找到了一些以前的架構,并嘗試能不能利用現在的技術將它的優勢更好的發揮出來。
在TPU這件事上,谷歌高調嗎?
谷歌一點也不高調,而且這種不高調簡直是全方位的不高調。首先,TPU不賣,至少谷歌已經在很多場合公開表示過TPU不會進入市場售賣,雷鋒網也對此進行過報道。也就是說谷歌完全沒有必要像英特爾或者英偉達那樣費勁吆喝自己的產品,好博取更大的市場份額。從谷歌自己的表述來看,它之所以設計這么一個專用的芯片,是因為自己的越來越多的產品開始使用非常復雜的深度學習模型,從而產生了真真切切的提升計算能力的需求。這也是谷歌同英特爾和英偉達這兩家同樣為人工智能設計了芯片的公司的不同之處:后者是看到了市場上這樣的需求,于是自己針對這種需求設計了好產品,以期獲得更好的銷量,而谷歌是自己就有這種需求。所以設計了一個產品來滿足它。出發點是滿足自己的需求,也同樣意味著沒有必要向市場太過高調的宣傳自己的產品。
事實上谷歌對TPU這件事也確實一直比較低調,包括這次的發布,基本也只是在博客上說了一下性能相對于以前硬件的優勢,發了一篇中規中矩的論文,不像英特爾和英偉達的新產品通常還要開個發布會,更何況這也不是新產品,而是谷歌內部已經使用了幾年的芯片。谷歌甚至還在論文里說:現在在計算機對新架構的嘗試實在是比較少,因此希望TPU的發布能給后來者以啟示,在此基礎上做出更成功的繼任產品。也就是說谷歌都不介意其他廠商模仿自己的產品,只要對計算平臺的整體水平有所促進就行。這樣的行為,我實在是沒法將其與“天花亂墜的炒作概念”聯系起來。也沒有感覺到有什么往市場或者人工智能發展方面進行“深度解讀”的必要性。

谷歌真的在論文里說,“我希望我們的后繼者能造出比我們更強的產品”
如果說非要針對TPU說出個一二三,那我們到底應該怎么看待它?
前面說過了,TPU不賣,如果谷歌不反悔的話,這就意味著我們除非自己進了谷歌,想用上TPU只能寄希望于谷歌的云服務能開放我們對TPU的使用權限了,這首先是說,TPU不太可能會成為英特爾和英偉達產品的直接競爭對手。但就算TPU進入了市場,仍然有許多其他的因素會影響它的最終成績。
前兩天TPU的發布還讓黃仁勛親自出來發聲要把Google懟回去,天知道他一邊懟心里會不會一邊有那么一種“我為什么要跟他糾結于幾倍還是幾十倍性能這種破事上……沒辦法,誰讓觀眾愿意看呢”的想法。

因為不管大家有沒有意識到,一個硬件發布的最終意義,不是去和別的硬件比在這種計算上又快了多少倍,那種計算上又省了多少電,而是它對它的購買者來說,夠不夠劃算?對于開發者來說,到底夠不夠好用?(當然,有很多時候這兩者可能是同一人)
什么叫劃不劃算?性價比這個詞我相信大家一定不陌生,有些硬件,可能擁有能把整個世界踩在腳下的計算能力,但對于一個全新的領域來說,新硬件的性能越強大,往往也意味著需要越高的水平才能駕馭。在實際的開發中,知道如何用最簡潔的方法編寫代碼、如何使用才能發揮出硬件的最大實力和使用多強的硬件一樣重要甚至要更重要。如果代碼寫的不好,計算機總是要在重復的步驟上浪費很多時間,那用再強的硬件也沒有多大意義。超級大企業里專門研究這種方向的部門肯定有很多厲害的人物,他們會知道如何把這些個硬件的性能榨干到一絲不剩,但是現在和以后可能會出現的更多輕度使用AI技術來改善自己業務水平的中小企業往往沒有條件和動力去找到這樣的人,而且他們對時間的緊迫程度要求也不一定會很高,算法訓練慢上幾天一個月,他們可能不是很在意。所以最后影響銷量的最大因素可能還是營銷和價格……除非能在性價比上拉開非常非常大的差距。
在講到性價比的同時,我們也提到了好不好用。這款硬件是橫刀千軍、自重三噸的大錘,還是彈藥稀缺卻能百步穿楊的步槍?一個開發者要花掉多少時間才能學會這個硬件能提供的大部分特性?它的易擴展性、穩定性到不到位?這其中任何一點差距都可能導致開發者還沒來得及贏回訓練算法的那幾周時間,先在設計算法上卡了一個月。一款好的硬件發展的最終境界應該是達到對使用者透明的程度,也就是使用者在編程的過程終不需要去關心它的存在,只要按照自己的需要去寫程序就好了,而這個硬件自然就能找到最合適的辦法把程序運行出來。越能接近這種程度的硬件,可以說是會越受歡迎的。目前的這些硬件,不管是TPU,還是在文章中被拿來和其相比的K80和Haswell CPU,目前在AI開發方面都還沒法達到這種程度。也就是說,我的看法是:為AI定制的硬件估計還有很長的路要走,TPU與NVIDIA和英特爾的同類產品相比,可能有一些優勢,但終究沒有拉開質的差距,何況以黃仁勛的反應來看,它的性能優勢也沒有到輕輕松松幾十倍那么夸張,仍然能順利的歸入硬件性能的自然發展曲線之列。那在這基礎之上,再做更多的琢磨揣測,就顯得很無必要了。
無論如何,每一次的進步都是值得我們為之鼓掌的,但同時,也是無需強行解讀的。在硬件向著那個方向努力發展的時候,我們只要好好關注這領域的動向,客觀的評價每一次進步,并將這些進步應用于自己的實際工作中(如果這是你的工作的話),這樣,應該就是對這些努力研發新硬件的先驅者們最大的鼓勵了。
















 京公網安備 11010502049343號
京公網安備 11010502049343號