









然而,AI 領域的科學家們并沒有停下前進的腳步。上個周末,人工智能領域最卓越的科學家之一:斯坦福大學終身教授、谷歌云首席科學家李飛飛在未來論壇年會上,為我們做了一場名為“超越 ImageNet 的視覺智能”的精彩演講。她告訴我們,AI 不僅僅能夠精準辨認物體,還能夠理解圖片內容、甚至能根據一張圖片寫一小段文章,還能“看懂”視頻……
我們都知道,地球上有很多種動物,這其中的絕大多數都有眼睛,這告訴我們視覺是最為重要的一種感覺和認知方式。它對動物的生存和發展至關重要。
所以無論我們在討論動物智能還是機器智能,視覺是非常重要的基石。世界上所存在的這些系統當中,我們目前了解最深入的是人類的視覺系統。從 5 億多年前寒武紀大爆發開始,我們的視覺系統就不斷地進化發展,這一重要的過程得以讓我們理解這個世界。而且視覺系統是我們大腦當中最為復雜的系統,大腦中負責視覺加工的皮層占所有皮層的 50%,這告訴我們,人類的視覺系統非常了不起。
寒武紀物種大爆發
一位認知心理學家做過一個非常著名的實驗,這個實驗能告訴大家,人類的視覺體系有多么了不起。大家看一下這個視頻,你的任務是如果看到一個人的話就舉手。每張圖呈現的時間是非常短的,也就是 1/10 秒。不僅這樣,如果讓大家去尋找一個人,你并不知道對方是什么樣的人,或者 TA 站在哪里,用什么樣的姿勢,穿什么樣的衣服,然而你仍然能快速準確地識別出這個人。
1996 年的時候,法國著名的心理學家、神經科學家 Simon J. Thorpe 的論文證明出視覺認知能力是人類大腦當中最為了不起的能力,因為它的速度非常快,大概是 150 毫秒。在 150 毫秒之內,我們的大腦能夠把非常復雜的含動物和不含動物的圖像區別出來。那個時候計算機與人類存在天壤之別,這激勵著計算機科學家,他們希望解決的最為基本的問題就是圖像識別問題。
在 ImageNet 之外,在單純的物體識別之外,我們還能做些什么?
過了 20 年到現在,計算機領域內的專家們也針對物體識別發明了幾代技術,這個就是眾所周知的 ImageNet。我們在圖像識別領域內取得了非常大的進步:8 年的時間里,在 ImageNet 挑戰賽中,計算機對圖像分類的錯誤率降低了 10 倍。同時,這 8 年當中一項巨大的革命也出現了: 2012 年,卷積神經網絡(convolutionary neural network)和 GPU(圖形處理器,Graphic Processing Unit)技術的出現,對于計算機視覺和人工智能研究來說是個非常令人激動的進步。作為科學家,我也在思考,在 ImageNet 之外,在單純的物體識別之外,我們還能做些什么?
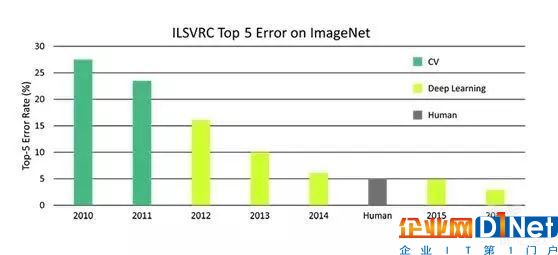
8年時間內計算機對圖像分類的錯誤率統計
8年的時間里,在ImageNet挑戰賽中,計算機對圖像分類的錯誤率降低了10倍。
通過一個例子告訴大家:兩張圖片,都包含一個動物和一個人,如果只是單純的觀察這兩張圖中出現的事物,這兩張圖是非常相似的,但是他們呈現出來的故事卻是完全不同的。當然你肯定不想出現在右邊這張圖的場景當中。

兩張相似的圖片呈現不同的故事
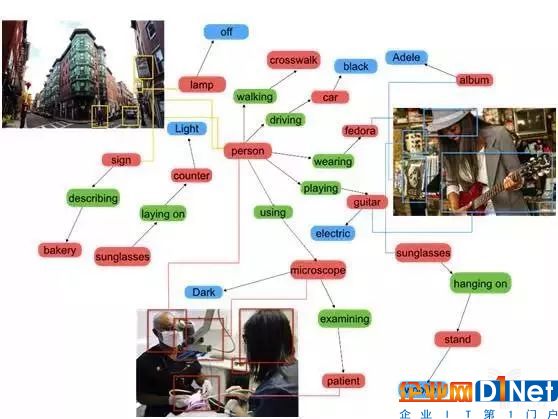
這里體現出了一個非常重要的問題,也就是人類能夠做到的、最為重要、最為基礎的圖像識別功能——理解圖像中物體之間的關系。為了模擬人類,在計算機的圖像識別任務中,輸入的是圖像,計算機所輸出的信息包括圖像中的物體、它們所處的位置以及物體之間的關系。目前我們有一些前期工作,但是絕大多數由計算機所判斷的物體之間的關系都是十分有限的。
最近我們開始了一項新的研究,我們使用深度學習算法和視覺語言模型,讓計算機去了解圖像中不同物體之間的關系。
計算機能夠告訴我們不同物體之間的空間關系,能在物體之間進行比較,觀察它們是否對稱,然后了解他們之間的動作,以及他們之間的介詞方位關系。所以這是一個更為豐富的方法,去了解我們的視覺世界,而不僅僅是簡單識別一堆物體的名稱。

Visual Relationship Detection with Language Priors
更有趣的是,我們甚至可以讓計算機實現 Zero short(0 樣本學習)對象關系識別。舉個例子,用一張某人坐在椅子上、消防栓在旁邊的圖片訓練算法。然后再拿出另一張圖片,一個人坐在消防栓上。雖然算法沒見過這張圖片,但能夠表達出這是“一個人坐在消防栓上”。類似的,算法能識別出“一匹馬戴著帽子”,雖然訓練集里只有“人騎馬”以及“人戴著帽子”的圖片。
讓 AI 讀懂圖像
在物體識別問題已經很大程度上解決以后,我們的下一個目標是走出物體本身,關注更為廣泛的對象之間的關系、語言等等。
ImageNet 為我們帶來了很多,但是它從圖像中識別出的信息是非常有限的。COCO 軟件則能夠識別一個場景中的多個物體,并且能夠生成一個描述場景的短句子。但是視覺信息數據遠不止這些。
經過三年的研究,我們發現了一個可以有更為豐富的方法來描述這些內容,通過不同的標簽,描述這些物體,包括他們的性質、屬性以及關系,然后通過這樣的一個圖譜建立起他們之間的聯系,我們稱之為 Visual Genome dataset(視覺基因組數據集)。這個數據集中包含 10 多萬張圖片,100 多萬種屬性和關系標簽,還有幾百萬個描述和問答信息。在我們這樣一個數據集中,能夠非常精確地讓我們超越物體識別,來進行更加精確的對于物體間關系識別的研究。
視覺基因組數據集視覺基因組數據集原理示意圖
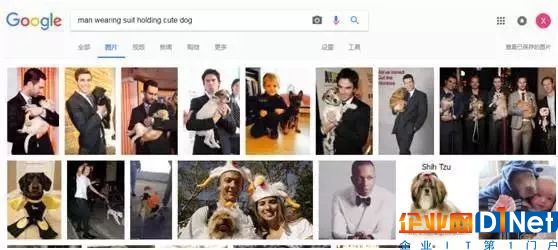
那么我們到底要怎么使用這個工具呢?場景識別就是一個例子:它單獨來看是一項簡單的任務,比如在谷歌里搜索“穿西裝的男人”或者“可愛的小狗”,都能直接得到理想的結果。但是當你搜索“穿西裝的男人抱著可愛的小狗”的時候,它的表現就變得糟糕了,這種物體間的關系是一件很難處理的事情。
絕大多數搜索引擎的這種算法,在搜索圖像的時候,可能很多還是僅僅使用物體本身的信息,算法只是簡單地了解這個圖有什么物體,但是這是不夠的。比如搜索一個坐在椅子上的男性的圖片,如果我們能把物體之外、場景之內的關系全都包含進來,然后再想辦法提取精確的關系,這個結果就會更好一些。
2015 年的時候,我們開始去探索這種新的呈現方法,我們可以去輸入非常長的描述性的段落,放進 ImageNet 數據集中,然后反過來把它和我們的場景圖進行對比,我們通過這種算法能夠幫助我們進行很好的搜索,這就遠遠地超過了我們在之前的這個圖像搜索技術當中所看到的結果。
Google搜索準確率示意圖
Google圖片的準確率已經得到了顯著提升
這看起來非常棒,但是大家會有一個問題,在哪里能夠找到這些場景圖像呢?構建起一個場景圖是一件非常復雜并且很困難的事情。目前 Visual Genome 數據集中的場景圖都是人工定義的,里面的實體、結構、實體間的關系和到圖像的匹配都是我們人工完成的,過程挺痛苦的,我們也不希望以后還要對每一個場景都做這樣的工作。
所以我們下一步的工作,就是希望能夠出現自動地產生場景圖的一個技術。所以我們在今年夏天發表的一篇 CVPR 文章中做了這樣一個自動生成場景圖的方案:對于一張輸入圖像,我們首先得到物體識別的備選結果,然后用圖推理算法得到實體和實體之間的關系等等;這個過程都是自動完成的。
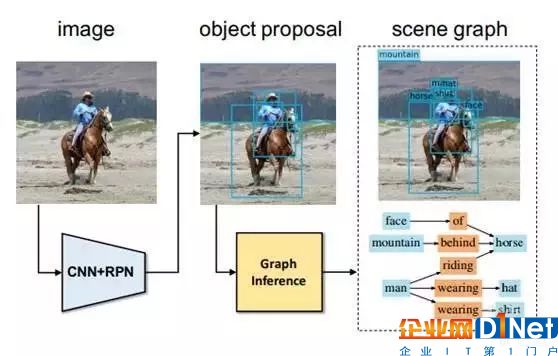
Scene Graph Generation by Iterative Message Passing
人工智能可以像人類一樣看懂視頻?
Visual Genome 數據集能讓計算機更好地了解場景信息,但是還是不夠的。而且實際上到現在為止,我們僅僅探索了認知心理學家所討論的一個概念——現場感知(scene gist perception):只需要輕輕一瞥,就能把握主整個場景中的物體和它們之間的關系。那么在此之外呢?
小編想回過頭去看看十年前我在加州理工學院讀博士的時候做的一個心理學實驗,小編用 10 美元/小時的費用招募人類被試,通過顯示器給他們快速呈現出一系列照片,每張照片閃現之后用一個類似墻紙一樣的圖像蓋住它,目的是把他們視網膜暫留的信息清除掉。然后讓他們盡可能多地寫下自己看到的東西。有些照片只顯示了 1/40 秒(27毫秒),有些照片則顯示了 0.5 秒的時間,我們的被試能夠在這么短的時間里理解場景信息。如果小編給的實驗費用更高的話,大家甚至能做的更好。進化給了我們這樣的能力,只看到一張圖片就可以講出一個很長的故事。
2015 年開始,我們使用卷積神經網絡和遞歸神經網絡算法比如 LSTM 來建立圖像和語言之間的關系。從此之后我們就可以讓計算機給幾乎任何東西配上一個句子。比如這兩個例子,“一位穿著橙色馬甲的工人正在鋪路”和“穿著黑色T恤的男人正在彈吉他”。
不過圖像所包含的信息很豐富,一個簡短的句子不足以涵蓋所有,所以我們下一步的工作就是稠密捕獲(dense capture)。讓計算機將一張圖片分為幾個部分,然后分別對各個部分進行描述,而不是僅僅用一個句子描述整個場景。
除了此之外,我們今年所做的工作邁上了一個新的臺階,計算機面對圖像不只是簡單的說明句子,還要生成文字段落,把它們以具有空間意義的方式連接起來。這與認知心理學家所做的實驗當中人類的描述結果是非常接近的。

A Hierarchical Approach for Generating Descriptive Image Paragraphs
COCO 能夠根據圖片寫出幾個句子(粉色部分)
新算法能夠生成一個段落(藍色部分)
A Hierarchical Approach for Generating Descriptive Image Paragraphs
但是我們并沒有停止在這里,我們開始讓計算機識別視頻。這是一個嶄新且豐富的計算機視覺研究領域。互聯網上有很多視頻,有各種各樣的數據形式,了解這些視頻是非常重要的。我們可以用跟上面相似的稠密捕獲模型去描述更長的故事片段。把時間的元素加入進去,計算機就能夠識別一段視頻并對它進行描述。
視覺認知和邏輯推理的結合
最后,小編想談談在簡單認知以外,我們如何讓人工智能達到任務驅動的水平。從一開始人類就希望用語言給機器人下達指定,然后機器人用視覺方法觀察世界、理解并完成任務。
在 20 世紀七八十年代的時候,人工智能的先驅們就已經在研究如何讓計算機根據他們的指令完成任務了。比如下面這個例子,人類說:“藍色的角錐體很好。我喜歡不是紅色的立方體,但是我也不喜歡任何一個墊著角錐體的東西。那我喜歡那個灰色的盒子嗎?” 那么機器或者人工智能就會回答:“不,因為它墊著一個角錐體”。它能夠對這個復雜的世界做理解和推理。
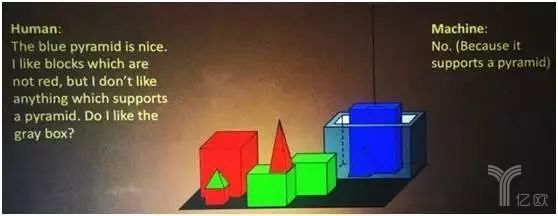
案例示意圖一
最近,我們和 Facebook 合作重新研究這類問題,創造了帶有各種幾何體的場景,我們命名為 Clever dataset。這個數據集包含成對的問題和答案,這其中會涉及到屬性的辨別、計數、對比、空間關系等等。我們會給人工智能提問,看它會如何理解、推理、解決這些問題。
我們將人工智能和人類對這類推理問題的回答做了個比較:人類能達到超過 90% 的正確率,機器雖然能做到接近 70% 了,但是仍然有巨大的差距。有這個差距就是因為人類能夠組合推理,機器則做不到。
因此我們開始尋找一種能夠讓人工智能表現得更好的方法:我們把一個問題分解成帶有功能的程序段,然后在程序段基礎上訓練一個能回答問題的執行引擎。這個方案在嘗試推理真實世界問題的時候就具有高得多的組合能力。這項工作我們剛剛發表于 ICCV。
比如我們提問“紫色的東西是什么形狀的?”,它就會回答“是一個立方體”,并且能夠準確定位這個紫色立方體的位置。這表明了它的推理是正確的。它還可以數出東西的數目。這都體現出了算法可以對場景做推理。
人類視覺已經發展了很久,計算機的視覺識別雖然在出現后的 60 年里有了長足的進步,但也仍然只是一門新興學科。
















 京公網安備 11010502049343號
京公網安備 11010502049343號