









你有沒有過這種體驗?標題挺吸引人,點進去看是廣告,剛想評論心儀文章,評論區已經被噴子占領。類似這樣的不良社區氛圍非常傷害大家的閱讀體驗。例如美團收購摩拜的事件,一篇販賣焦慮的文章《摩拜創始人套現15億背后,你的同齡人,正在拋棄你》掃蕩了朋友圈,但同樣的事件,在知乎上“怎么看待美團收購摩拜”的問題下,高贊回答都是客觀理性的分析,讀者在評論區的互動也異常活躍卻不是對立攻擊。
為什么知乎上還能有這樣的理性討論?客觀、理性和專業的用戶、回答者是關鍵,而用戶愿意在知乎而非其他平臺客觀討論的基礎,則是其社區環境、崇尚專業和友善的氛圍所決定的,這也正是知乎對比其他平臺的最大優勢之一。
隨著AI 時代來臨,算法被廣泛用于內容推薦和廣告變現上,算法推薦對內容氛圍的破壞正在引發業界擔憂和反思。近期,快手和今日頭條就因為“算法應當有怎樣的價值觀”而廣受輿論關注,4月9日下午,今日頭條等四款應用遭遇全網下架處理。
同樣是算法,全行業都在研究用戶喜好,拼命推薦內容,而知乎似乎更關注內容生產的本身,將算法大規模應用于社區氛圍的管理,以生產出有價值和對用戶有幫助的內容。知乎通過開發“悟空”、“瓦力”等算法機器人7X24小時管理社區氛圍,譬如,“瓦力”每天處理內容近萬條,對于舉報上來的不友善內容,0. 3 秒內進行處理。這個速度在整個行業都是名列前茅的。
知乎也決心加強技術能力的建設,在技術圈,今年知乎大力招募算法人才的消息已經不脛而走,明顯已開始發力。而知乎在大眾和互聯網圈的品牌效應也是驚人,身邊不少技術朋友表現出了興趣。下面我們可以從知乎技術團隊發布的專欄了解下這家公司的算法思路和應用,這幾篇文章詳細介紹了知乎算法是如何通過識別垃圾廣告導流信息,處理人身攻擊類內容,或是識別答非所問等方面來維護平臺氛圍和內容質量的,其中不少思路值得業內工程師們借鑒。(以下內容知乎技術授權“吳懟懟”發布,如有不妥之處歡迎指正討論)
以下為Quote:
算法在社區氛圍的應用(一):識別垃圾廣告導流信息近期,我們發現社區內出現了垃圾廣告的導流內容,影響用戶體驗,破壞認真、專業和友善的社區氛圍。為了解決這種情況,我們進行了大量努力和探索。最開始在識別導流信息上采用的是干擾轉換+正則匹配+匹配項回溯的方式進行異常導流信息的識別與控制,取得了很好的效果。
但是我們發現,隨著我們處理這些內容的同時,他們正在逐步增加導流信息的各種變體,常見的有以下幾種方式:第一種變體是導流前綴的變化,如 QQ 導流前綴變化成企鵝,「騰順」等等;第二變體是不使用前綴,如退款 123377281;第三種變體是導流中隨機插入非特殊字符,如 319xxxx053xxxx7178。我們對這些變體進行了收集整理和分析。
通過對典型導流樣本的分析,我們發現盡管導流信息變體在不斷演化,但是它們所在的上下文變化并不明顯。因此,我們嘗試通過序列標注的方式來識別導流內容,提高算法的識別準確度。
模型常用的序列標注算法,有 HMM、CRF、RNN、BILSTM-CRF 等。BILSTM-CRF 在多個自然語言序列標注問題(NER、POS)上都表現優秀,同時,通過實驗,我們也發現 BILSTM-CRF 表現優于其他模型。
網絡結構BILSTM-CRF 模型結構如下圖所示:
第一層為 Embedding 層,將輸入文本轉換為詞向量表示。
第二層為雙向 LSTM 層。LSTM 具有強大的序列建模能力,能夠捕捉長遠的上下文信息,同時還擁有神經網絡擬合非線性的能力。相比單向的 LSTM,雙向 LSTM 不僅能夠利用以前的上下文信息,還能利用未來的上下文信息。
第三層為一個全連接層。作用是將上一層的輸出,映射為 [T,C] 的向量,T為輸入序列長度,C為標簽數量。輸出的也就是每個 timestep 對應的狀態 score。
最后一層為 linear-chain CRF 層。CRF 計算的是一種聯合概率,優化的是整個序列(最終目標),而不是將每個時刻的最優拼接起來。在 CRF 層,使用 viterbi 解碼算法從狀態 score 和轉移矩陣中解碼得到輸出狀態序列。
BILSTM-CRF 模型同時結合了 LSTM 和 CRF 的優點,使得其在序列標注任務上具有極強的優勢。
CRF從上述網絡結構,可知要優化的目標函數由最后一層決定。
通常給定一個線性鏈條件隨機場 ,當觀測序列為時,
標簽序列為的概率可寫為
其中,Z(x) 為歸一化函數,對所有可能的標簽序列求和。
是特征函數,通常考慮轉移特征和狀態特征兩方面。狀態特征描述標簽之間的相似程度,是上一層網絡的輸出。
轉移特征考慮狀態之間的變化趨勢
在模型的概率給出之后,可以使用最大似然估計優化參數,即最小化負對數似然 -logP(y|x),從而得到整個網絡的 loss function。
是否包含前后綴?
訓練模型之前,我們需要標記訓練數據。
標記訓練數據的一個問題是,是否要包含導流信息的前后綴。如「加V:xxxxxx」,是否需要包含「加V」。通常情況下,答案應該是不包含,因為我們的實體是微信號,「加 V」不屬于我們要識別的實體。
但是,我們在實驗過程中發現,如果不加前后綴,模型會把大量的英文單詞,或者字母數字組合,標記為導流內容。原因是,作為中文社區,英文單詞出現頻率很低,同時大部分導流信息都是字母數字組合,從而使得模型出現錯誤。
針對這種情況,我們在處理數據時,將導流信息的前后綴也作為實體的一部分,有效的降低了上述問題出現的概率。
實體編碼序列標注模型另一個需要注意的問題是,實體編碼的格式。常用的序列實體編碼方式有IO、BIO、BMEWO三種。
IO 編碼是最簡單的編碼,它將屬于類型X的實體的序列元素標記為 I_X,不屬于任何實體的序列元素標記為 O。這種編碼存在缺陷,因為它不能代表彼此相鄰的兩個實體,因為沒有邊界標簽。
BIO 編碼是當前實體編碼的行業標準。它將表示實體的 I_X 標簽細分為實體開始標簽 B_X和實體延續標簽 I_X。
BMEWO 編碼進一步區分實體結束元素 E_X 和實體中間元素令 M_X,并為單元素實體添加一個全新的標簽 W_X。
上述三種編碼的示例,如下所示:
綜合考慮,我們選擇 BIO 編碼,一是滿足我們對于導流信息的區分,二是其標記方式相對通用。
效果在實驗階段,分別將 HMM、BILSTM、BIGRU、BILSTM-CRF 做了一系列的對比,將表現比較好的 BILSTM-CRF 放在線上與原本的 Base 模型進行 AB 實驗。從結果上來看,寬深度學習模型在線下/線上都有比較好的效果。線上實驗結論如下:
后續的改進為了提高模型的效果,我們需要使用更多的訓練數據,構造更復雜的網絡結構,使用更多的超參數設置訓練模型。然而,不斷增加的模型尺寸和超參數極大地延長了訓練時間。很明顯,計算能力已經成為了模型優化的主要瓶頸。相比 CNN 和 Attention 等操作,LSTM 仍然不太適應多線程 /GPU 計算,訓練速度偏慢,不能充分利用GPU的并行計算優勢。因此,我們還在嘗試 SRU 等RNN 加速方案,希望在模型效果損失不大的情況下,提高模型的訓練速度。
我們當前采用的是Char-based model,Char-based model在一個優勢在于利用詞元(lemmas)和形態學信息(morphological information ),能更好的處理導流內容內部結構,如手機號的組成。另一方面,Word-based model 更多的利用詞語信息,詞語比字具有更高的抽象等級,通常正確率會更高。我們希望通過訓練一個新的分詞模型的方式,使得在保持處理導流內容內部結構的情況下,構建 Word-based model。
算法在社區氛圍的應用(二):深度學習在不友善文本識別中的應用此前,我們常常收到知友們的反饋說「好煩哦,TA 又不友善了」、「我要舉報 XX,TA 在評論區又開始杠上了」、「這種辱罵他人的人,你們都不處理嗎?」等等。今年年初,我們開始嘗試用深度學習算法輔助審核人員處理不友善問題,經過近三個月的探索和嘗試,目前該算法第一版已經上線,并且取得相對不錯的效果。
知乎不友善文本識別應用的場景和策略
目前,瓦力識別不友善的算法已經應用在知友們的舉報和社區實時產生的內容中。針對這兩種內容的不同場景和特點,我們采用了不同的處理策略:
舉報內容的處理策略瓦力有效地提升了我們的舉報處理效率和響應速度。目前,我們每天約收到知友們近 25,000 條舉報。在這些舉報中,大約有 7,000 條是關于不友善的內容。模型訓練階段,我們利用經過人工標注的舉報內容進行模型訓練。線上預測階段,如果模型預測某條內容屬于不友善的概率x 大于閾值 p_abuse,瓦力會在 0.3 秒間完成判斷并直接刪除,內容被處理后,知友們也會收到相應的私信通知;如果模型預測該內容屬于非不友善類型的概率 x 大于閾值 p_friend,則認為該內容屬于非不友善內容,那么該舉報會被忽略;不滿足以上條件的內容,我們會進行多次人工審核判斷,人工審核后的判斷標準也會用于下一輪模型的迭代和升級。
我們重視每一個舉報,并根據舉報內容增強瓦力可識別的范圍和準確度,還會每日人工復核知友們的舉報,針對可能存在不同處理意見的舉報,會根據規范與實際的應用場景多次復審。在這里,我們也非常感謝知友們的每一次舉報,感謝大家與我們一起并肩維護社區氛圍,我們也正是在知友們的舉報中逐漸形成統一的判斷標準。
全量內容的處理策略我們會對每天新產生的內容進行全量審核,每天可以實時攔截處理 3,000 條內容。在實際的操作過程中,我們發現全量內容有如下兩個特點使其不能跟舉報內容共用模型和策略:
不友善樣本和非不友善樣本分布非常不均衡;詞語分布和舉報內容有區別。比如,舉報內容中包含「SB、NC」之類的臟詞的基本屬于不友善類型;但是在全量內容中臟字、臟詞可能出現在影視作品討論、陳述自己的經歷等場景等非不友善內容中,例如:坑到你頭皮發麻。———《魯班智商二百五》由于數據不均衡、數據排查標注成本較高和上述數據的分布特點,全量內容模型要做到準確率 98% 以上非常困難,因此我們根據人工審核量,選擇一個適宜的閾值,在保證每天召回量的基礎上,維持召回內容的處理準確率到 80% 以上,并將召回的內容進行人工審核。
知乎社區不友善文本識別系統基本框架目前,不友善內容處理系統架構如下圖所示(以知友舉報內容識別識別系統為例,全量內容識別系統與其類似)
不友善內容處理系統框圖
我們在選擇模型時在小批量數據集上對比了 lstm 模型、svm 和樸素貝葉斯模型,lstm 模型表現最好,因此我們的模型優化工作主要集中在深度學習模型上。
詞向量將詞用「詞向量」表示是深度學習模型處理 NLP 問題的關鍵一步,我們的系統中使用 Google 提出的 word2vec 詞向量模型,訓練數據采用來自知乎社區 300 多萬條真實的提問、評論、回答數據,內容涉及娛樂、政治、新聞、科學等各個領域,詞向量維度采用 128 維,訓練模型窗口大小 5。
Word2vec 的原理和使用方法這里就不做過多介紹了,有興趣的可以閱讀文獻[1],Python 版本實現的可以參考 gensim官方文檔。
text-cnnTextCNN 是利用卷積神經網絡對文本進行分類的算法,2014 年由 Yoon Kim 提出(見參考[3])。 TextCNN 的結構比較簡單,其模型的結構如下圖:
ext-cnn 網絡結構
Embedding Layer——該層將輸入的自然語言編碼成 distributed representation,我們的模型該層使用 word2vec 預先訓練好的詞向量,同時該層設置為 trainable。
Convolution Layer——這一層主要是通過卷積,提取文本的 n-gram 特征,輸入文本通過 embedding layer 后,會轉變成一個二維矩陣,假設文本的長度為 |T|,詞向量的大小為 |d|,則該二維矩陣的大小為 |T|x|d|,接下的卷積工作就是對這一個 |T|x|d| 的二維矩陣進行的。卷積核的大小一般設為 n x |d|,n 是卷積核的長度,|d| 是卷積核的寬度(LP 中通常取詞向量的維度)。我們的模型中 n 取 [2,3,4,5]4 個值,每個值固定取 128 個 filter。
Max Pooling Layer——最大池化層,對卷積后得到的若干個一維向量取最大值,然后拼接在一塊,作為本層的輸出值。如果卷積核的 size=2,3,4,5 每個 size 有 128 個 filter,則經過卷積層后會得到 4×128 個一維的向量,再經過 max-pooling 之后,會得到 4×128 個 scalar 值,拼接在一塊,最終得到一個 512×1 的向量。max-pooling 層的意義在于對卷積提取的 n-gram 特征,提取激活程度最大的特征。
Fully-connected Layer——將 max-pooling layer 后再拼接一層,作為輸出結果。實際中為了提高網絡的學習能力,可以拼接多個全連接層。
Softmax——根據類別數目設定節點數,我們不友善文本識別項目是二分類問題,設置一個節點,激活函數選擇 sigmoid。
Bi-LSTMCNN 最大問題是固定 filter_size 的視野,無法建模更長的序列信息,自然語言處理中更常用的是 RNN,因為 RNN 能夠更好的表達上下文信息。在文本分類任務中,由于語句過長,會出現梯度消失或梯度爆炸的問題,基本的RNN網絡難于處理語言中的長程依賴問題,為了解決這個問題,人們提出了 LSTM 模型。我們在對比 LSTM 和 Bi-LSTM 效果后選擇了 Bi-LSTM,Bi-LSTM 從某種意義上可以理解為可以捕獲變長且雙向的「n-gram」信息。圖 3 是 Bi-LSTM 用于分類問題的網絡結構,黃色的節點分別是前向和后向RNN的輸出,示例中的是利用最后一個詞的結果直接接全連接層 softmax 輸出了。我們的實際使用的網絡結構在全聯接層之后加了一層 dropout 層,dropout 輸出接 sigmoid 二元分類層。RNN、LSTM、BI-LSTM 可以參考文獻[4]。
用于文本分類的雙向 LSTM 網絡結構
我們參考論文 A C-LSTM Neural Network for Text Classification 來實現 CNN-LSTM 文本分類模型,模型的網絡結構如下所示(該圖直接來自論文)
CNN-ISTM 網絡結構
效果舉報的內容
知友舉報內容不管是直接刪除還是直接忽略,都要求算法有較高的準確率(本文準確率沒有特別說明的情況下指 precision),經過對比不同模型的評測效果,目前線上選用模型和準確率、召回率如下:
全量內容
經過模型調優和對比不同模型的評測效果,目前線上使用的模型和準確率、召回率如下:
后續工作
我們會利用更多數據模型,嘗試更復雜定神經網絡并進行語義分析。通過分析實際操作中的 bad case 可以發現,有些文本帶有臟字、臟詞但并不屬于不友善類別,同時也存在一些很隱晦的不友善內容,主要有以下三類:
影視、社會熱點事件討論中,評價影視作品中的人物或者熱點事件當事人,例如:這個視頻難道不是貨車司機的錯,有時候又想去延安路龍翔橋附近斑馬線前停一天車,MDZZ 規定。陳述自己等經歷,例如:我當時竟然信了,覺得當時的自己就是 FJ 。詼諧詞語或反語,例如:你真聰明,連這都不會;有哪些人工 ZZ 發明。我們會繼續嘗試用深度學習做語義分析,對文本進行語義角色標注(見參考文獻[6]),抽取句子的施事者(Agent)、受事者(Patient)、客體及其對應的描述詞;通過語義相似度構建語義詞典;將語義信息融合到我們的不友善文本識別模型中。
參考文獻:
[1]https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf[2] https://radimrehurek.com/gensim/models/word2vec.html[3]https://arxiv.org/abs/1408.5882[4]https://blog.csdn.net/zzulp/article/details/79379960[5]https://arxiv.org/pdf/1511.08630.pdf[6] Chinese semantic role labeling with shallow parsing算法在社區氛圍的應用(三): 機器學習在答非所問識別上的運用跳繩的好處有哪些?可以鍛煉哪些肌肉?
A:心肺功能比之前有提高。
B:有助于提高身體的乳酸閾值。
C:有助于提高身體的協調性。
D:謝謝,我去買了跳繩。
請問,以上哪個答案是答非所問?
現在,瓦力可直接識別并處理該題中的答非所問內容。
我們鼓勵認真、專業的分享,期待每一次討論都能碰撞出更多有價值的信息,并希望每一個用心的回答都能夠得到好的展示,為他人帶來更多幫助。但是,我們也發現在社區中出現了答非所問類的內容,影響知友們獲取有價值內容的效率。
為了更好地識別答非所問類內容,我們采用了多種模型,包括傳統的機器學習模型和比較新的深度學習模型。通過前期對語料的分析,我們發現語言用詞、作者歷史行為、知友對內容的反饋信息等都具有比較明顯的區分度,因而我們嘗試使用特征工程和傳統機器學習方法實現了瓦力識別答非所問的第一版模型,并達到了一個相對不錯的效果。
Random Forest
隨機森林 (Random Forest) 是樹模型里兩個常用模型之一(另一個是 Gradient Boosting Decision Tree)。顧名思義,就是用隨機的機制建立一個森林,森林由多棵分類樹構成。當新樣本進入時,我們需要將樣本輸入到每棵樹中進行分類。打個形象的比喻,知乎森林召開議會,討論@劉看山
到底是狗還是北極狐(看山,我知道你是北極狐的,手動捂臉逃…),森林中的每棵樹都獨立發表了自己對這個問題的觀點,做出了自己的判斷。最終劉看山是狗還是北極狐,要依據投票情況來確定,獲得票數最多的類別就是這片森林對其的分類結果。如同圖一所示意境。
森林會議
樣本
通過訓練語料和業務數據,進行特征工程,提取出了以下三類特征:
回答和問題的文本特征:如二者的詞向量、詞向量相似度、關鍵詞相似度、話題相似度等;回答的統計特征:如回答的贊同、反對、評論、舉報等是用戶對其的交互特征;回答作者的統計特征:正向行為,如關注、回答、提問、評論、舉報等,負向行為,如回答被贊同、被反對、被感謝、被舉報等。同時,通過歷史積累、用戶標注、策略生成產生出了訓練樣本集,然后用以上特征類別表示出每條樣本。
分類樹
使用隨機有放回抽樣選取每棵樹的訓練樣本,隨機選取 m 個特征 (m < 總特征數) 進行無限分裂生長,成長為能獨立決策的樹。
投票決策
通過建好的多棵分類樹,對新的樣本進行決策投票,獲得最終的分類結果。
對于 Random Forest 的實現,有很多優秀開源的實現,在實際中我們封裝了 Spark 中的 Random Forest 完成了模型的迭代。最終取得了 Precision 97%,Recall 58% 左右的不錯結果。
細心的知友可能注意到了,我們的特征里有一類特征是與時間和回答的暴光有關的,即回答和作者的統計特征。為此我們在現有模型的基礎上分析了這類特征的時間累積效果,如圖二所示。從圖中可以看到,經過一天的統計特征累積,Precision 達到了 90%,但 Recall 只有 40%,可以說這一天時間對于 40% 的答非所問有了比較充分的特征積累以支撐對其的準確判斷。而隨時間的增加,基本上 Precision 和 Recall 都有提升。但并不是時間越長,提升越多。
最終我們結合產品應用層面和算法閾值,分別選出兩個時間點,一方面犧牲 Recall 快速識別處理一部分答非所問的回答,另一方面允許一定的處理延時,保證了大量的 Recall,大大凈化了回答區域的無關內容。
統計特征累積周期(天)對 Precision 和 Recall 的影響
傳統機器學習的一個核心內容就是特征工程,包括特征提取、特征選擇等。
特征提取:從原始數據出發構造出特征,通常包括業務和對語料的統計分析。特征選擇:從提取出的候選特征中挑選出有用的特征。但特征工程總是會耗費比較多的時間,而且在答非所問的識別中一些時間相關的特征,還延長了處理周期,不利于快速處理。而廣為流傳的深度學習,能自動對輸入的低階特征進行組合、變換,映射到高階的特征,這也促使我們轉向深度學習進行答非所問的識別。
深度學習興起于圖像識別,其過程可以引用圖三[1] 大致描繪,輸入特征,經隱藏層逐層抽象、組合,最后經輸出層得出識別結果。
深度學習示意
相較于圖片天然的像素表征,可以直接輸入到深度神經網絡里,文本需要進行向量化后方可作為網絡的輸入。關于「詞向量化」的精彩描述可以參考[2]。此處我們抽取了知乎社區 1000 多萬真實的文本信息,包括問題、回答、文章、評論等數據,利用 Facebook 開源的 FastText 訓練了 256 維的詞向量和字向量。對于 FastText 的原理和用法此處不作詳細闡述,感興趣的朋友可以參考[3]。
CNN 網絡 (Convolutional Neural Network)
我們模型的網絡結構基本上采用了 Severyn[4] 提出的網絡結構,但在一些細節上做了些改動,比如圖四中的 CNN-answer/question, 我們結合了 Wide & Deep[5] 的思想,以提取更為豐富的語義信息。
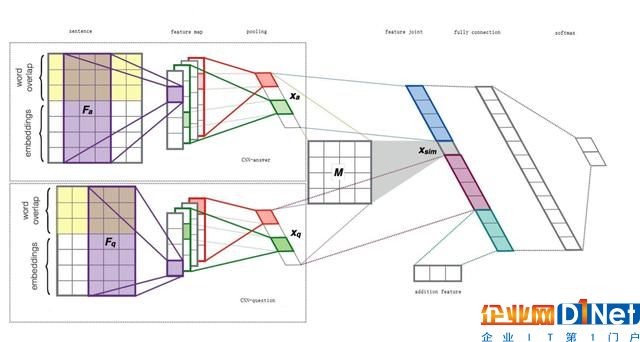
模型結構
Embedding Layer——該層利用預訓練好的 FastText 詞向量將原始詞序列表達成詞向量序列
Convolutional Layer——此層主要通過卷積操作,同時捕獲類似于 N-Gram 特征(但同 N-Gram 還是有差異的)。我們的模型選取了 [2, 3, 4, 5, 6] 5 個卷積核寬度,為每個卷積核配置了 64 個 filter
Pooling Layer——池化層,對經過卷積操作提取的特征進行 Sampling。此處我們采用了 K-Max-Average pooling,對卷積層提取的特征,選擇出激活程度 top-K 的特征值的平均值作為 pooling 的結果
Feature Join & Fully connected Layer——將前述幾層獲得的特征,以及額外信息進行融合,作為最終的特征輸出,以便于最后的決策判斷。實際上,我們在 Fully Connection 后面加了 3 層 Dense Layer,以提高網絡的表達能力。
Softmax——將最后的特征轉換成二分類決策概率。
最終訓練好該模型,在驗證集上達到了 Precision 78%, Recall 80% 的效果。Recall 雖有比較大的提升,但 Precision 并沒有前文描述的 Random Forest 的方法好。
效果
目前,答非所問幾個模型都上線到了知乎產品的諸多場景下,如反對、舉報、專項清理等。每天清理約 5000 條新產生的「答非所問」內容,以及此前現存的 115 萬條「答非所問」內容。
參考文獻:
[1] Breaking it down: A Q&A on machine learning[2] 詞向量和語言模型[3] FastText[4] Learning to rank short text pairs with convolutional deep neural networks[5] Wide & Deep Learning for Recommender Systems















 京公網安備 11010502049343號
京公網安備 11010502049343號