










深度學習正在改變一切。正如電子和計算機改變了人類所有的經濟活動一樣,人工智能將重塑零售業、交通運輸業、制造業、醫藥、電信業、重工業……甚至數據科學本身。而且,像AlphaGo這種人工智能超越人類的領域及其應用在不斷增長。在Schibsted,Manuel Sánchez Hernández看到了深度學習所提供的機會,他們很高興為此而出力。
Manuel Sánchez Hernández在最近的NIPS 2016(Neural Information Processing Systems,神經信息處理系統)會議上,聽取了Andrew Ng分享的一些關于深度學習的想法。Manuel Sánchez Hernández做了一則筆記,經作者授權,InfoQ翻譯并整理本文,以饗讀者。
Manuel Sánchez Hernández是位于倫敦的Schibsted Product & Technology的數據科學家。
深度學習的第一大優勢是它的規模。Andrew總結如下圖:
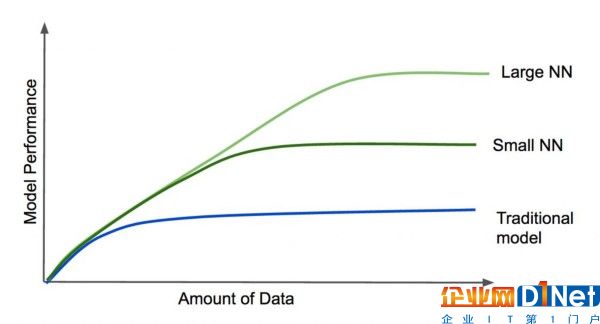
當數據量增加時,深度學習模型表現得更好。不僅如此,神經網絡越大,對于更大的數據集,會做得更好。不同于傳統的模型,一旦性能達到一定的水平,往模型里增加更多的數據或者改變算法的復雜度,并不能帶來性能的提升。
深度學習模型之所以如此強大的另一個原因是它們擁有端到端學習的能力。傳統模型通常需要顯著的特征工程。例如,一個模型能夠轉錄一個人可能需要做許多中間步驟輸入的聲音,找到音素,正確鏈接,為每個鏈接分配相應單詞。
深度學習模型通常不需要這樣的特征工程。你通過為模型展示大量實例進行端到端的訓練,該技術工作并不是被應用到轉換特征,而是進入模型的架構。數據科學家需要決定和嘗試他想要的神經元類型、層數以及如何連接它們等等。
構建模型的挑戰
深度學習模型有他們自己的挑戰。許多決策必須在其構建過程中進行。如果采取錯誤的路徑,將浪費大量的時間和金錢,那么數據科學家如何才能做出明智的決定?確定為了改善他們的模型下一步需要做什么?Andrew向我們展示了他用于開發模型的經典決策框架,但這次他將其擴展到其他有用的案例中。
讓我們從基礎開始:在一個分類任務(例如,從掃描做診斷),對于來源如下的錯誤,我們應該有一個好的想法。
人類專家訓練集交叉驗證(CV)集(也稱為開發或開發集)一旦我們有了這些錯誤,數據科學家可以遵循基本流程去發現模型模型構建中的有效決策。首先問你的訓練錯誤高嗎?如果是這樣,那么說明該模型不夠好;它可能需要更豐富(例如,更大的神經網絡)和不同的架構,或者需要更多的訓練。重復該過程直到偏差減小。
一旦訓練集錯誤減少,CV集的低錯誤率是必要的。否則,分歧高,意味著需要更多的數據,更多的正則化或新的模型架構。重復該過程,直到模型在訓練和CV集中表現良好。
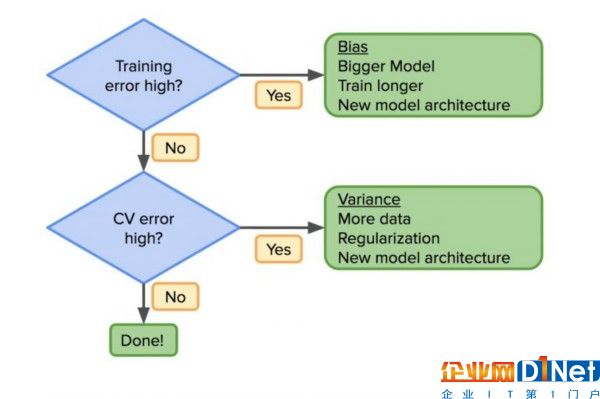
這些過程并沒有什么新事物。然而,深度學習已經在改變這個過程。如果你的模型不夠好,總有一個“出路”:增加你的數據或使你的模型更大。在傳統模型中,正則化用于調整這種權衡,或者產生新的特征——這點看著容易做著難。但是,自從有了深度學習之后,我們有了更好的工具,以減少這兩個錯誤。
改進人工數據集的偏差/分歧過程
事實上并沒有那么多大量的可用樣本,那么還有另一種方法是建立自己的訓練數據。一個很好的示例可以是語音識別系統的訓練,通過對同一個聲音添加噪聲可以創建人工訓練樣本。然而,這并不意味著訓練集將具有和實集相同的分布。對于這些情況下的偏差/分歧權衡需要不同的框架。
想象一下,對于語音識別模型,我們有50,000小時的生成數據,但只有100小時的真實數據。在這種情況下,生成的集將是訓練集,真正的集應分割成CV和測試集。否則,在CV和測試集之間將有不同的分布,一旦模型“完成”,將會注意到這些差異。問題由CV集指定,因此它應該盡可能接近實集。
在實踐中,Andrew建議將人工數據分為兩部分:訓練集及其一小部分,我們稱之為“訓練/CV集”。這樣,我們將估量以下錯誤:
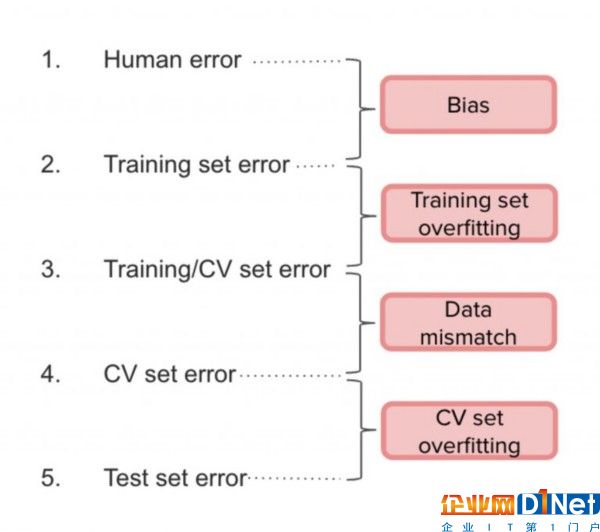
因此,(1)和(2)之間的區別是偏差,(2)和(3)之間的區別是分歧,(3)和(4)之間的區別是由于分布不匹配,(4)和(5)之間的區別是因為過度擬合。
考慮到以前的工作流程應該像這樣修改:
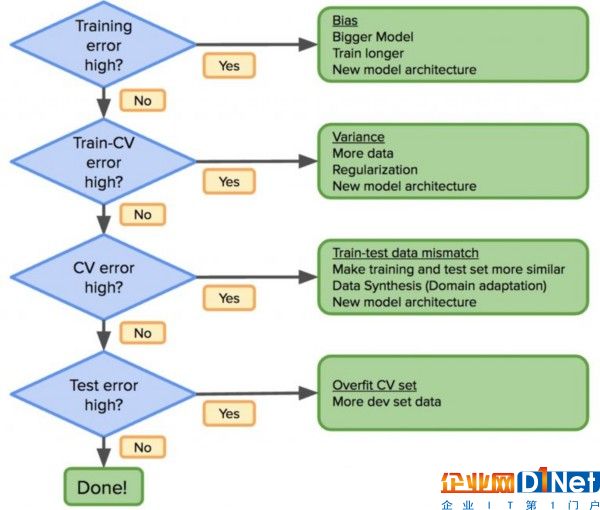
如果分布誤差高,修改訓練數據分布,使其盡可能類似于測試數據。對偏差/分歧的正確理解,能提高機器學習的效率。
人類水平的表現
了解人類的表現水平非常重要,因為這將指導決策。事實證明,一旦一個模型超越人類的表現,通常是很難改善的。因為我們越來越接近“完美的模型”,即沒有模型可以做得更好(“貝葉斯率”)。這不是傳統模型原有的問題——它的表現已經超越人類水平,但在深度學習領域這個問題變得越來越普遍了。
因此,當構建一個模型時,以人類專家組的表現誤差為參考將是“貝葉斯率”的代表。例如,如果一組醫生比一位專家醫生做得更好,則使用醫生組測量的誤差。
怎樣才能成為更好的數據科學家?
閱讀許多論文和復現別人的結果是成為一個更好的數據科學家的最佳和最可靠的路徑。這是Andrew已經從他的學生身上看到的模式,我對此也十分認同。
即使幾乎你做的全都是“苦活”:清潔數據、調整參數、調試、優化數據庫等,不要停止閱讀論文和驗證模型,在驗證別人模型的過程中,你將得到啟發。
閱讀英文原文: How is Deep Learning Changing Data Science Paradigms?

















 京公網安備 11010502049343號
京公網安備 11010502049343號