



All in one & One for all
作為云計算的基石產品,云主機的核心特性決定了云上其它能力的拓展,也直接關乎于用戶的使用體驗。用戶選擇云計算的出發點在于:簡單性,速度和經濟性。但是由于互聯網與IT服務的場景多樣化,業內大多數廠商都是分別推出適應不同場景的云主機類型,但也因此帶給了用戶運維和采購的復雜度。
什么是“All in one”呢?“快杰”將自己定義為“簡單”的產品。簡單不僅意味著使用方便,還意味著多項軟硬件技術的融合,以此為用戶提供超高的產品性能。也就是說,當你面對各種業務場景下CPU、網絡、存儲的不同性能需求時,無需考慮太多因素,“快杰”均可滿足。
這是“快杰”的一組數據:全面搭載Intel最新一代Cascade Lake處理器,配備25G基礎網絡并采用全新的網絡增強2.0方案,支持RDMA-SSD云盤,網絡性能最高可達1000萬PPS,存儲性能最高可達120萬IOPS。
在產品上線之初,我們對“快杰”進行了跑分測試,測試結果顯示,同等規格的配置下,“快杰”的性能明顯優于市場上同類型的云主機產品。舉個例子,在同樣8核16G的配置下,“快杰”的網絡性能較友商高出3倍多,存儲性能有著近4倍的差異。
但是在這樣的高配下,“快杰”的價格提升卻不超過20%,部分配置機型的價格與普通機型價格基本持平或略有下降,云盤價格僅為市場同類產品的60%或者更低。“快杰”云主機用“One for all”的價格紅利將所有技術又通通回饋給了用戶。
“羅馬不是一天建成的”,不論是All in one 還是 One for all,在這些數據的背后,都離不開UCloud在技術上的持續探索和積累。接下來,我們就來聊聊“快杰”背后的技術進階之路。
一、 網絡增強2.0:4倍性能提升+3倍時延下降
網絡通道是嚴重制約云主機性能的瓶頸之一,在這里,值得一提的便是“快杰”在25G智能網卡網絡增強能力方面做出的技術突破。
? 硬件級別的網卡加速
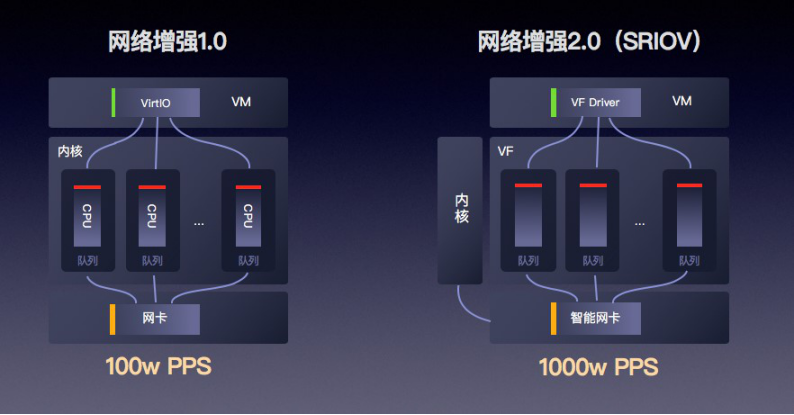
基于云主機網絡性能提升的需求,25G網絡逐漸成為趨勢。但是由于傳統軟件Virtual Switch方案的性能瓶頸:當物理網卡接收報文后,是按照轉發邏輯發送給VHost線程,VHost再傳遞給虛擬機,因此VHost的處理能力就成為了影響虛擬機網絡性能的關鍵。
在調研了業界主流的智能網卡方案之后,我們最終采用了基于Tc Flower Offload的OpenvSwitch開源方案,為“快杰”提供了硬件級別的網卡加速。虛擬機網卡可直接卸載到硬件,繞過宿主機內核,實現虛擬機到網卡的直接數據訪問。相較于傳統方案,新的智能網卡方案在整個Switch的轉發性能為小包24Mpps,單VF的接收性能達15Mpps,使得網卡整體性能提升10倍以上,應用在云主機上,使得“快杰”的網絡能力提升至少4倍,時延降低3倍。
? 技術難點突破:虛擬機的熱遷移
在該方案落地之時,我們遇到了一個技術難題:虛擬機的熱遷移。因為各個廠商的SmartNIC都是基于VF passthrough的方案,而VF的不可遷移性為虛擬機遷移帶來了困難,在此將我們的解決方案分享給大家。
我們發現,用戶不需要手工設置bonding操作或者制作特定的鏡像,可以妥善的解決用戶介入的問題。受此啟發,我們采用了 VF+standby Virtio-net的方式進行虛擬機的遷移。具體遷移過程為:
1、創建虛擬機自帶Virtio-net網卡,隨后在Host上選擇一個VF 作為一個Hostdev的網卡,設置和Virtio-net網卡一樣的MAC地址,attach到虛擬機里面,這樣虛擬機就會對Virtio-net和VF網卡自動形成類似bonding的功能,此時,在Host上對于虛擬機就有兩個網絡Data Plane;
2、Virtio-net backend的tap device在虛擬機啟動時自動加入到Host的OpenvSwitch bridge上,當虛擬機網卡進行切換的時候datapath也需要進行切換。VF attach到虛擬機后,在OpenvSwitch bridge上將VF_repr置換掉tap device;
除此以外,UCloud針對25G智能網卡的其他技術創新可查看:https://mp.weixin.qq.com/s/FUWklPXcRJXWdrWpsQHzrg
二、RDMA-SSD云盤:提供120萬IOPS存儲能力
在云盤優化方面,我們主要從IO接入層性能優化、RDMA網絡加速及后端存儲節點提升三方面來完成RDMA-SSD云盤的技術實現,最終為“快杰”提供120萬IOPS的存儲能力。
? 基于SPDK的IO接入層性能優化
如下圖,為傳統的OEMU Virtio方案示意,在第3步時, QEMU里的驅動層通過Gate監聽的Unix domain socket的轉發IO請求時,存在額外的拷貝開銷,因此成為IO接入層的性能瓶頸。
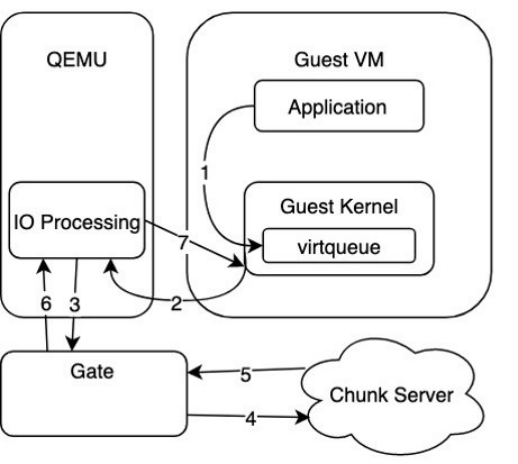
圖:QEMU Virtio方案示意
針對該問題,UCloud使用了SPDK VHost來優化虛擬化IO路徑。
(1)SPDK VHost:實現轉發IO請求的零拷貝開銷
SPDK(Storage Performance Development Kit )提供了一組用于編寫高性能、可伸縮、用戶態存儲應用程序的工具和庫,基本組成分為用戶態、輪詢、異步、無鎖 NVMe 驅動,提供了從用戶空間應用程序直接訪問SSD的零拷貝、高度并行的訪問。
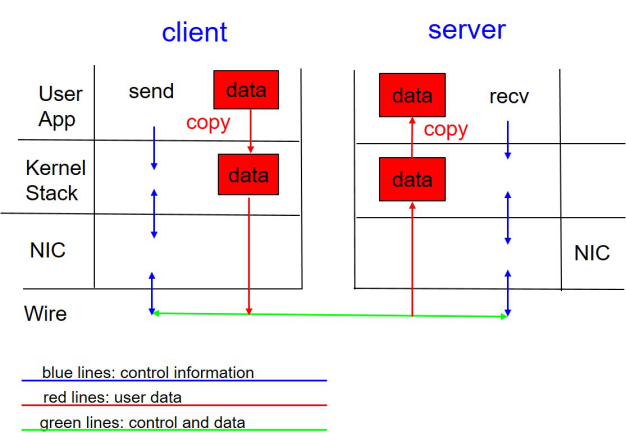
圖:SPDK VHost方案
如上圖,在應用SPDK VHost方案后,IO路徑流程如下:1、提交IO到virtqueue;2、輪詢virtqueue,處理新到來的IO;3-4、后端存儲集群處理來自Gate的IO請求;5、通過irqfd通知Guest IO完成。
最終SPDK VHost通過共享大頁內存的方式使得IO請求可以在兩者之間快速傳遞這個過程中不需要做內存拷貝,完全是指針的傳遞,因此極大提升了IO路徑的性能。
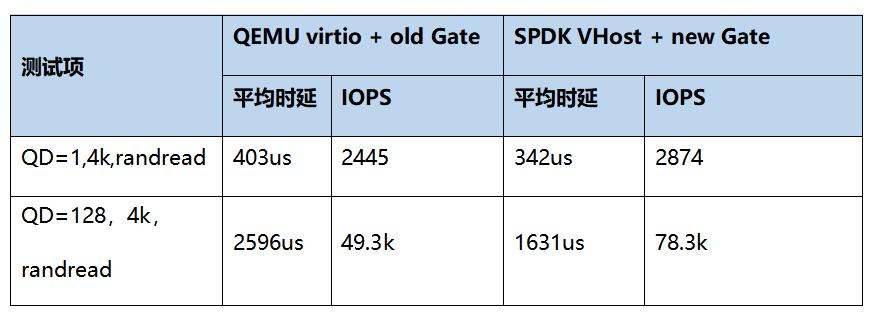
如下表,我們對新老Gate的性能做了測試對比。可以看到,在應用SPDK VHost以后,時延和IOPS得到了顯著優化,時延降低61us,IOPS提升58%。
(2)開源技術難點攻破:SPDK熱升級
在我們使用SPDK時,發現SPDK缺少一項重要功能——熱升級。我們無法100%保證SPDK進程不會crash掉,一旦后端SPDK重啟或者crash,前端QEMU里IO就會卡住,即使SPDK重啟后也無法恢復。
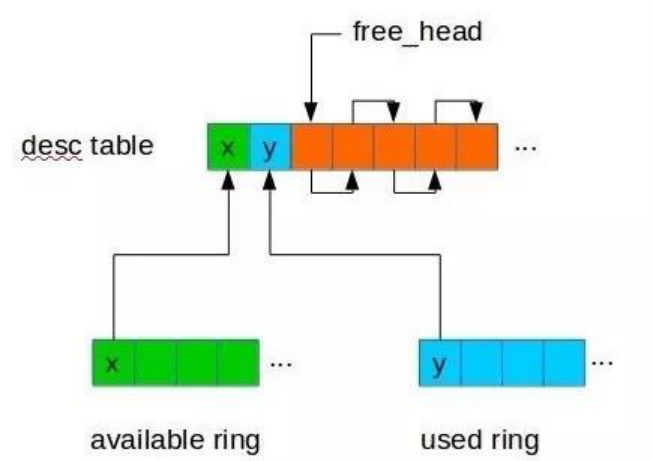
圖:virtio vring機制示意
通過深入研究virtio vring的機制,我們發現在SPDK正常退出時,會保證所有的IO都已經處理完成并返回了才退出,也就是所在的virtio vring中是干凈的。而在意外crash時是不能做這個保證的,意外crash時virtio vring中還有部分IO是沒有被處理的,所以在SPDK恢復后需要掃描virtio vring將未處理的請求下發下去。
針對該問題,我們在QEMU中針對每個virtio vring申請一塊共享內存,在初始化時發送給SPDK,SPDK在處理IO時會在該內存中記錄每個virtio vring請求的狀態,并在意外crash恢復后能利用該信息找出需要重新下發的請求,實現SPDK的熱遷移。具體可查看https://mp.weixin.qq.com/s/UBRJhN58VQwDCHYZyDP02w了解。
2、RDMA網絡加速
(1)TCP瓶頸
在解決了IO路徑優化問題后,我們繼續尋找提高云盤IO讀寫性能的關鍵點。在協議層面,我們發現使用TCP協議存在以下問題:
? TCP收發數據存在網卡中斷開銷,以及內核態到用戶態的拷貝開銷;
? TCP是基于流式傳輸的,因此通常網絡框架(libevent)會使用一個緩沖區暫存數據,等到數據達到可處理的長度才從緩沖區移除,同樣地,發包過程為了簡化TCP緩沖區滿引起的異常,網絡框架也會有一個發送緩沖區,那么這里就會產生二次拷貝。
圖:TCP協議原理示意
針對這個問題,我們用RDMA協議來代替TCP協議,來達到提升IOPS和時延的能力。
(2)RDMA代替TCP
RDMA(Remote Direct Memory Access)技術全稱遠程直接數據存取,是為了解決網絡傳輸中服務器端數據處理的延遲而產生的。
使用RDMA代替TCP的優點如下:
? RDMA數據面是bypass kernel的,數據在傳輸過程中由網卡做DMA,不存在數據拷貝問題。
? RDMA收發包過程是沒有上下文切換的,發送時將數據post_send投遞到SQ上,然后通知網卡進行發送,發送完成在CQ產生一個CQE;接受過程有一些差異,RDMA需要提前post_recv一些buffer,網卡收包時直接寫入buffer,并在CQ中產生一個CQE。
? RDMA為消息式傳輸,即假設發送方發送一個長度為4K的包,接收方假如收到了,那么這個包的長度就是4K,不存在只收到一部分的情況。RDMA提供的這種能力可以簡化收包流程,不需要像TCP一樣去判斷數據是否收全了,也就不存在TCP所需的緩沖區了。
? RDMA的協議棧由網卡實現,數據面Offload到網卡上,解放了CPU,同時帶來了更好的時延和吞吐。
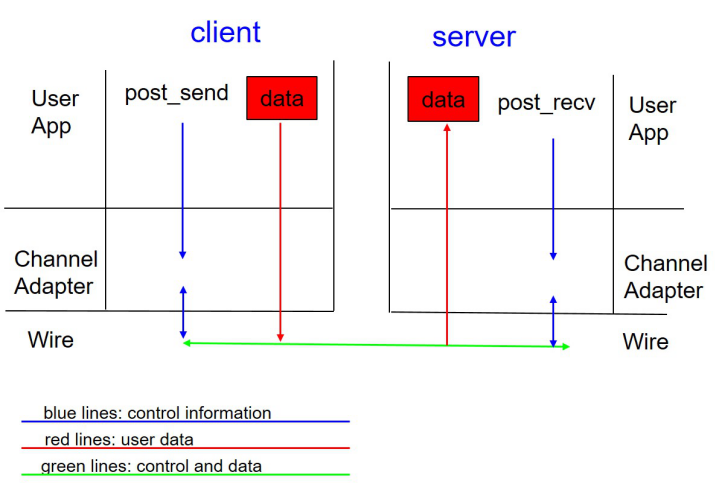
圖:RDMA協議原理示意
3、后端存儲節點IO Path加速
除了在IO路徑接入與傳輸協議方面做了改進之外,UCloud還針對云硬盤后端存儲節點進行了優化。
對于原有的Libaio with Kernel Driver,我們采用了SPDK NVMe Driver進行了替代,下圖為Fio對比測試兩者的單核性能情況,可以看到應用SPDK NVMe Driver后性能有了較大的提升。
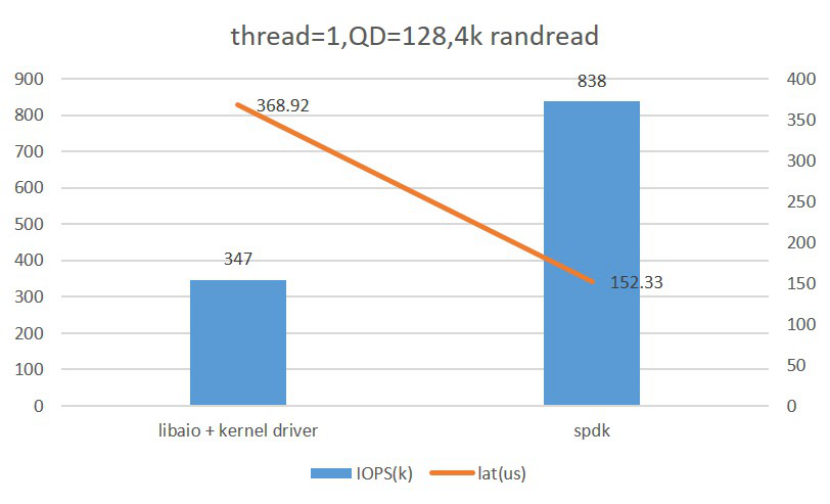
圖:Libaio with Kernel Drive & SPDK NVMe Driver單核性能比較
此外,SPDK NVMe Driver使用輪詢模式,可以配合RDMA發揮出后端存儲的最佳性能。
綜上,我們實現了云盤的全面優化:使用SPDK VHost代替QEMU,實現虛機到存儲客戶端的數據零拷貝;使用高性能RDMA作為后端存儲的通信協議,實現收發包卸載到硬件,使得RSSD云盤的延遲降低到0.1毫秒,體驗幾乎和本地盤一致;存儲引擎由SPDK代替libaio,高并發下依然可以保持較低的時延。再配合全25G的底層物理網絡,使RDMA-SSD云盤的隨機讀寫性能達到最佳,實現120萬IOPS。
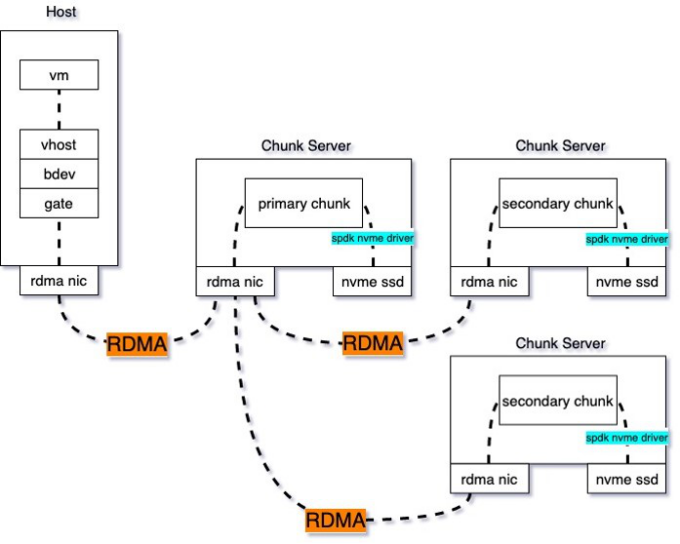
圖:RDMA-SSD云硬盤原理圖
三、內核調優:產品綜合性能提升10%
提起云主機,更多的會想到計算、存儲、網絡,甚少有人關注內核。然而,內核構建是一個云主機的核心工作,它負責管理系統的進程、內存、設備驅動程序、文件和網絡系統等,對云主機性能和穩定性至關重要。
未優化之前,我們對云主機中特定業務場景進行了基準性能測試。在測試過程中,利用perf、systemtap、eBPF等多種動態跟蹤技術,在Host內核、KVM和Guest內核等不同觀測層級上,對影響性能的因素進行了指令級別的分析。
在此基礎上,我們針對性的進行了內核增強和優化工作。
? CPU增強&漏洞修復
我們在QEMU和KVM中添加了Intel 新一代Cascade Lake虛擬CPU的支持,相比上一代Skylake,增加了clflushopt、pku、axv512vnni等指令集,在特定場景下性能表現更加出色。此外,針對CPU漏洞方面,我們利用硬件解決了Meltdown,MDS,L1TF等漏洞,同時針對Spectre_v2補丁添加了代價更小的Enhanced IBRS增強修復機制,在虛擬化層面對漏洞進行了修復。
最后,我們將硬件修復能力賦予”快杰”,使得云主機可以避免Guest內核在軟件層面修復安全漏洞,消除這方面引起的性能開銷和業務指標下降。
? CPU對內存讀寫能力的優化
針對CPU對內存讀寫能力的優化,我們主要從兩方面來實現。
首先我們基于硬件內存虛擬化(Intel EPT),添加了定制化大頁內存的支持,從而避免了之前內存虛擬化中存在的管理器/分配器開銷、換頁延遲等,極大減少了頁表大小和TLB miss,同時保證云主機內存與其他云主機、系統軟件間相互隔離,避免影響。
其次,我們增強了NUMA親和性的使用。眾所周知,跨節點訪問內存的延遲遠遠大于本地訪問所產生的,針對該問題,我們通過合理的資源隔離和分配,使云主機的VCPU和內存綁定在同一個節點。此外,對于大型云主機可能存在單個節點資源不夠的情況,我們將云主機分配在兩個節點,把節點的拓撲結構暴露給Guest內核,這樣云主機可以更方便的利用NUMA特性對關鍵業務進行調度管理。
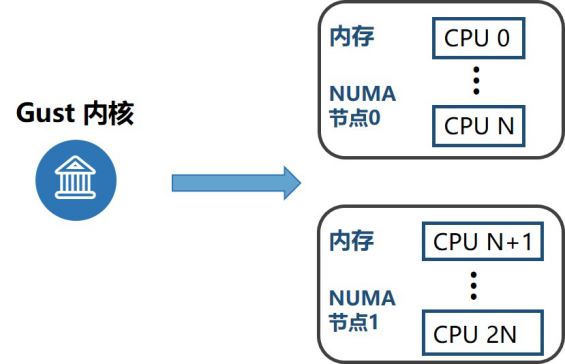
圖:NUMA親和性的使用
? Host內核&KVM優化
結合性能分析數據,我們對Host內核和KVM也進行了大量的優化。
在VCPU調度方面,我們發現CFS調度器會在臨界區內使用時間復雜度為O(n)的算法,導致調度器開銷過高、Guest計算時間減少及調度延遲增大,我們在CFS中修復了這一問題。
此外,在Host/Guest上下文切換過程中,我們發現某些寄存器的上下文維護代碼會引入一定開銷,因此在保證寄存器上下文切換正確性的同時,我們也去掉了這些維護代碼引起的開銷。
在云主機運行過程中,會產生大量的核間中斷(IPI),每次IPI都會引起VMExit事件。我們在虛擬化層引入了兩個新的特性:KVM-PV-IPI和KVM-PV-TLB-Flush。通過KVM提供的Send-IPI Hypercall,云主機內核可以應用PV-IPI操作消除大量VMExit,從而實現減少IPI開銷的目的。在云主機更新TLB的時候,作為發起者VCPU會等待其它VCPU完成TLB Shootdown,云主機內核通過PV-TLB-Flush極大減少等待和喚醒其它VCPU的開銷。
以上是一些比較重要的優化工作,其它內核、KVM、QEMU功能增強和穩定性提升等內容不再贅述。總體評估下來,通過內核調優,可幫助”快杰”實現10%以上的綜合能力提升。
四、三大應用場景分析
基于強大的性能,“快杰”能夠輕松滿足高并發網絡集群、高性能數據庫、海量數據應用的使用場景。我們分別選取了Nginx集群、TiDB、ClickHouse數據庫三個應用場景,下面來看一下”快杰”的表現:
? 場景1::搭建Nginx集群,突破網絡限制
愛普新媒是一家從事廣告DSP(Demand-Side Platform,需求方平臺)業務的公司,由于業務需求,愛普新媒對于網絡集群的高并發要求非常高。最終,愛普新媒選擇使用“快杰”搭建Nginx集群,作為API網關對其終端客戶提供服務。
Nginx是一款輕量級HTTP反向代理Web服務器,根據Nginx官網的數據,Nginx支持了世界上大約25%最繁忙的網站,包括Dropbox,Netflix,Wordpress.com等。其特點是并發能力強,而“快杰”進一步提升了其并發能力。
“快杰”突破了云主機之前的網絡限制,如下圖,“快杰”的應用使得愛普新媒原有集群內主機可以大幅度減少,并且在相同服務能力下,成本減半。
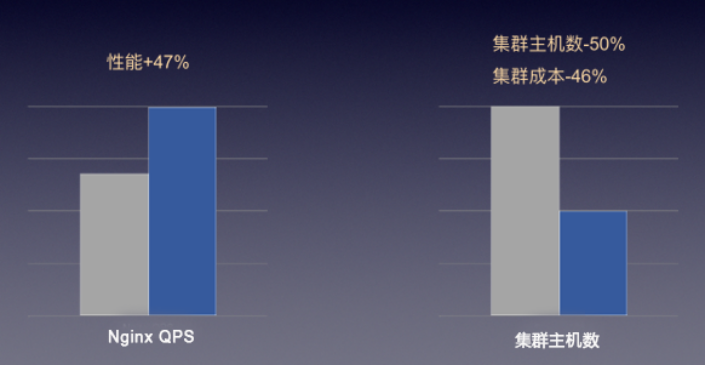
圖:“快杰”在高并發網絡集群場景中的表現
? 場景2: 搭建TiDB,突破IO性能瓶頸
PingCAP的TiDB是一款流行的開源分布式關系型數據庫,為大數據時代的高并發實時寫入、實時查詢、實時統計分析等需求而設計,對IO性能的要求無疑非常高。通常,TiDB要求底層使用NVMe SSD本地磁盤支撐其性能,但快杰云主機通過RSSD云盤即可滿足TiDB的高要求,其性能得到PingCAP工程師的實測認可。
目前,已有不少UCloud客戶使用快杰云主機搭建TiDB,突破了之前的數據庫性能瓶頸。
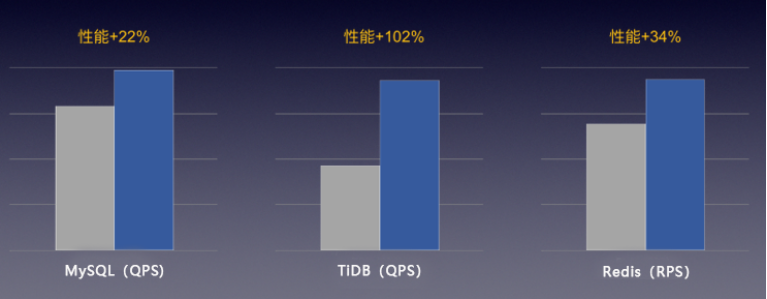
圖:“快杰”在高性能數據庫場景中的表現
除了TiDB,“快杰”實測能有效提升各類數據庫的性能表現20%以上。
? 場景3: 搭建ClickHouse,2倍提升數據吞吐量
TT語音是一款專門為手游玩家服務的語音開黑工具,由于業務要求需將APP埋點數據收集到大數據集群中分析。TT語音采用“快杰”搭建ClickHouse數據庫作為整個大數據集群的核心,對比之前,每日增量達到8億條記錄。
除了ClickHouse場景,“快杰”還可以對大數據生態進行全方位的優化,如下圖,數據吞吐提升高達2倍,助力企業大數據業務發展。

圖:“快杰”在大數據應用場景中的表現
結語
基于“軟硬件協同設計”的理念,“快杰”在網絡增強2.0、RSSD云盤優化、內核調優等方面做到了技術的大幅進階,為用戶帶來了突破性的云主機性能提升。在“快杰”的技術進階路上,技術的更迭與升級可以用語言描述出來,但是技術實現的背后卻代表了UCloud為用戶創造核心價值的堅持與追求。








 京公網安備 11010502049343號
京公網安備 11010502049343號