









作為國內(nèi)最優(yōu)秀的AI芯片公司,深鑒科技被以3億美元的價(jià)格賣給FPGA巨頭賽靈思。過去兩年,深鑒科技是國內(nèi)AI芯片領(lǐng)域冉冉升起的一顆明星。這家2016年3月成立的初創(chuàng)公司目前已完成三輪融資,投資方包括金沙江創(chuàng)投、螞蟻金服、三星風(fēng)投、賽靈思、聯(lián)發(fā)科等知名機(jī)構(gòu)和公司。
據(jù)媒體報(bào)道,其估值遠(yuǎn)超過10億美金。如今以3億美元賣出,并且據(jù)稱核心團(tuán)隊(duì)要鎖定4年內(nèi)不得離開賽靈思。難道深鑒科技被賤賣?當(dāng)然沒有!這是因?yàn)橹袊嬲齼?yōu)秀的企業(yè)太少,而追逐的資本太多,優(yōu)秀企業(yè)的估值已經(jīng)到了完全沒有理性的地步。如果這些企業(yè)在美國,估值會(huì)萎縮數(shù)倍以上。
FPGA已經(jīng)不是FPGA,更接近于ASIC
不是短期盈利無望,而是長期盈利無望,賣身給FPGA廠家肯定是最明智的選擇。在大部分人眼里,F(xiàn)PGA缺乏技術(shù)含量,純粹靠專利建立起護(hù)城河,F(xiàn)PGA只是個(gè)軀殼,算法才是靈魂。
是深鑒讓FPGA獲得靈魂。果真如此的話,那估值就不是3億美元。實(shí)際上聲稱有能力做機(jī)器學(xué)習(xí)算法的公司據(jù)說超過3000家,而大規(guī)模生產(chǎn)FPGA的獨(dú)立廠家全球僅Xilinx一家。
算法應(yīng)該說像人的視覺系統(tǒng),F(xiàn)PGA則是人的大腦和軀殼。現(xiàn)在的FPGA早已不是當(dāng)年的簡單地把寄存器和LUT整合在一起的白紙了,而是越來越像ASIC,或者說SoC。現(xiàn)在的FPGA都包含了復(fù)雜的接口資源,收發(fā)器資源,存儲(chǔ)器資源,有些則直接加入了多個(gè)ARM內(nèi)核。單純的FPGA幾乎不存在了。
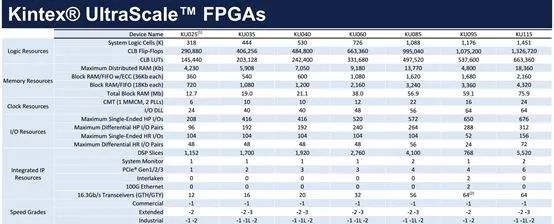
以深度學(xué)習(xí)、高性能運(yùn)算、圖形科學(xué)領(lǐng)域最常見的Kintex FPGA來看,國內(nèi)百度、騰訊、阿里都采用了KU115做計(jì)算加速。這款FPGA集成了大量資源,包括各種片上存儲(chǔ)器,Xilinx的FPGA中主要有分布式RAM 和 Block RAM 兩種存儲(chǔ)器。
用分布式RAM 時(shí)其實(shí)要用到其所在的SliceM,所以要占用其中的邏輯資源;而Block RAM 是單純的存儲(chǔ)資源,但是要一塊一塊的用,不像分布式RAM 想要多少bit都可以。頂級(jí)的Virtex系列FPGA更繼承了高達(dá)8GB的HBM高寬帶內(nèi)存。時(shí)鐘方面,有MMCM/PLL。
MMCM:混合模式時(shí)鐘管理器,用于在與給定輸入時(shí)鐘有設(shè)定的相位和頻率關(guān)系的情況下,生成不同的時(shí)鐘信號(hào)。PLL:鎖相環(huán),主要用于頻率綜合,使用一個(gè)PLL可以從一個(gè)輸入時(shí)鐘信號(hào)生成多個(gè)時(shí)鐘信號(hào)。這些主要用在收發(fā)器領(lǐng)域。
KU115里還包含5520個(gè)DSP,能夠大幅度提高圖像和視頻類任務(wù)的處理速度,這是類似GPU的并行運(yùn)算架構(gòu),可以說這片F(xiàn)PGA還包含一個(gè)小GPU。這個(gè)DSP可以對應(yīng)乘法累加器、乘加器或單步/n步計(jì)數(shù)器。
級(jí)聯(lián)多個(gè)DSP48E邏輯片可執(zhí)行復(fù)雜的功能。例如,不使用額外的FPGA架構(gòu)資源的情況下實(shí)現(xiàn)復(fù)雜乘法器或n階FIR濾波器。對某些如FFT運(yùn)算,速度大大提升。Virtex系列頂配有12288個(gè)DSP,性能達(dá)21897GMAC/s。

Xilinx的Soc+FPGA系列產(chǎn)品則完全可以叫SoC了,其不僅包含多個(gè)ARM CPU內(nèi)核,還有針對安全領(lǐng)域的R5內(nèi)核,還有Mali 400這樣的GPU,最夸張的是RFSoC把射頻的ADC/DAC也集成了,還有SD-FEC。
目前集成電路設(shè)計(jì)基本上都是用IP核搭積木的形式。IP核分為行為(Behavior)、結(jié)構(gòu)(Structure)和物理(Physical)三級(jí)不同程度的設(shè)計(jì),對應(yīng)描述功能行為的不同分為三類,即軟核(Soft IP Core)、完成結(jié)構(gòu)描述的固核(Firm IP Core)和基于物理描述并經(jīng)過工藝驗(yàn)證的硬核(Hard IP Core)。軟核就是我們熟悉的RTL代碼;固核就是指網(wǎng)表;而硬核就是指指經(jīng)過驗(yàn)證的設(shè)計(jì)版圖。ARM還是以軟核為主的。
IP軟核(Soft IP Core):通常是用硬件描述語言(hardware Description Language,HDL)文本形式提交給用戶,它經(jīng)過RTL級(jí)設(shè)計(jì)優(yōu)化和功能驗(yàn)證,但其中不含有任何具體的物理信息。
據(jù)此,用戶可以綜合出正確的門電路級(jí)設(shè)計(jì)網(wǎng)表,并可以進(jìn)行后續(xù)的結(jié)構(gòu)設(shè)計(jì),具有很大的靈活性,借助于EDA綜合工具可以很容易地與其他外部邏輯電路合成一體,根據(jù)各種不同半導(dǎo)體工藝,設(shè)計(jì)成具有不同性能的器件。
其主要缺點(diǎn)是缺乏對時(shí)序、面積和功耗的預(yù)見性。而且IP軟核以源代碼的形式提供的,IP知識(shí)產(chǎn)權(quán)不易保護(hù)。
IP硬核(Hard IP Core)是基于半導(dǎo)體工藝的物理設(shè)計(jì),已有固定的拓?fù)洳季趾途唧w工藝,并已經(jīng)過工藝驗(yàn)證,具有可保證的性能。其提供給用戶的形式是電路物理結(jié)構(gòu)掩模版圖和全套工藝文件。由于無需提供寄存器轉(zhuǎn)移級(jí)文件,因而更易于實(shí)現(xiàn)IP保護(hù)。其缺點(diǎn)是靈活性和可移植性差。
IP固核(Firm IP Core)的設(shè)計(jì)程度則是介于軟核和硬核之間,除了完成軟核所的設(shè)計(jì)外,還完成了門級(jí)電路綜合和時(shí)序仿真等設(shè)計(jì)環(huán)節(jié)。一般以門級(jí)電路網(wǎng)表的形式提供給用戶。
深鑒只是做了最上層的基于PC的應(yīng)用算法,要想讓算法在嵌入式系統(tǒng)中流暢運(yùn)行,還需要大量的工作,而這正是Xilinx做的。這就好像圖像識(shí)別算法,基于PC的幾百家都不止,但要一直到車內(nèi)的ARM系統(tǒng)上,表現(xiàn)會(huì)大大折扣,完全不具備實(shí)時(shí)性,也就無法應(yīng)用。
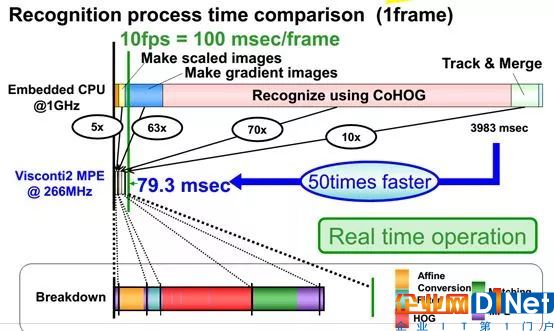
上圖是一個(gè)典型的行人識(shí)別算法HOG+SVM所需要時(shí)間的對比,硬核只需要79.3毫秒,軟核需要3983毫秒,所以純軟核的設(shè)計(jì)要么用極簡單的算法,要么用英偉達(dá)貴到飛起的芯片,即便如此,也不能和硬核比。
所以單純的算法公司,特別是復(fù)雜視覺處理算法公司如果不能將算法用芯片來承載,那就不可能成功。當(dāng)然,融資還是能成功的,畢竟還有很多投資者不是真正懂技術(shù)。















 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)