









深度神經網絡就像遠方地平線上的海嘯
鑒于深度神經網絡(DNN)的算法和應用還在不斷演變之中,所以目前我們還不清楚深度神經網絡最終會帶來怎樣的變化。但是迄今為止,深度神經網絡在翻譯文本、識別圖像和語言方面取得的成功,讓人們清楚地意識到,深度神經網絡將重塑計算機設計,當半導體設計和制造方面發生著同樣深刻顛覆的同時,這些變化逐漸開始帶來影響。
為訓練深度神經網絡量身定制的第一批商用芯片將于今年上市。由于訓練新的神經網絡模型可能需要幾周或幾個月的時間,因此這些芯片可能是迄今為止制造出的最大、也是最昂貴的商用芯片。
今年,該行業可能會看到來自初創公司Graphcore的一款微處理器芯片,沒有采用DRAM,而是來自競爭對手Cerebras Systems的晶圓級集成。英特爾收購的2.5-D Nervana芯片已經在制作樣品,其他十幾款處理器也正在開發中。同時,ARM和西部數據等芯片公司也正在研究芯片核心,以加速深度神經網絡的推理部分。
加州大學伯克利分校名譽教授David Patterson表示:“我認為(2018年)將有一場即將上演的派對。我們會看到許多公司正在評估的一些想法。”
這個趨勢非常重要,Patterson和聯合作者John Hennessey在關于計算機開創性文本的最新版本中撰寫了一個新的篇章,于上個月發表。作者對內部設計提供了深入的見解,例如Patterson撰寫的關于Google TensorFlow Processor(TPU)部分,以及最新Apple和Google智能手機芯片中的Microsoft Catapult FPGA和推理塊。
“這是計算機架構和封裝的復興。明年我們會看到比過去十年更有趣的計算機,” Patterson說。
深度神經網絡的興起,在過去幾年里把風投的資金帶回到了半導體領域。 EE Times最近公布的Silicon 60本榜單中,有7家致力于某種形式的神經網絡芯片,其中2家公司鮮為人知:Cambricon Technologies(中國北京)和Mythic Inc.(美國德克薩斯州奧斯汀)。
“我們看到擁有新架構的初創公司正在激增。我自己也在關注著15-20家公司......過去10到15年,我們還沒有看到哪一個細分領域有15家這么多的芯片公司出現。”企業家Chris Rowen這樣表示,他離開了Cadence Design Systems,成立了一家名為Cognite Ventures的公司,專注于神經網絡軟件。
“在高端服務器訓練方面,Nvidia是一個很難對付的競爭對手,因為它有很難撼動的軟件地位,而且涉足智能手機市場那你肯定是瘋了,因為你必須要擅長很多方面,但是在高端和低端智能手機市場你可能還有一些機會。”Rowen表示。
市場分析公司The Linley Group負責人Linley Gwennap表示,Nvidia最新的GPU(Volta)做得非常出色,Nvidia對其進行了調整,可對深度神經網絡做速度訓練。“但我當然不認為這是最好的設計,”Gwennap說。
Gwennap表示,Graphcore(英國布里斯托爾)和Cerebras(美國加州洛斯阿爾托)是訓練芯片領域值得關注的兩家初創公司,因為這兩家公司籌集的資金最多,而且似乎擁有最好的團隊。由Google前芯片設計師創立的初創公司Groq聲稱,它將在2018年推出一款推理芯片,在總體操作和每秒推論方面都會以4倍的優勢擊敗競爭對手。
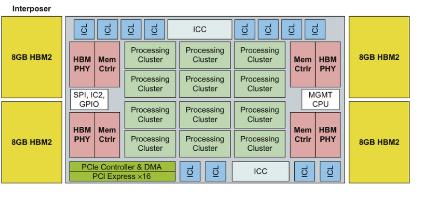
英特爾的Nervana是一個大型的線性代數加速器,位于4個8-Gb HBM2內存堆棧旁的硅中介層上。來源:Hennessy和Patterson,“計算機體系結構:一種定量方法”
英特爾代號為“Lake Crest”的Nervana(上圖)是最受關注的定制設計之一。它執行16位矩陣操作,數據共享指令集中提供的單個5位指數。
與Nvidia Volta一樣,Lake Crest邏輯器件位于4個HBM2高帶寬內存堆棧旁邊的TSMC CoWoS(襯底上芯片上芯片)中介層上。這些芯片被設計成網狀,提供5到10倍于Volta的性能。
雖然去年微軟在深度神經網絡上使用了FPGA,但Patterson仍然對這種方法持懷疑態度。 “你為[FPGA的]靈活性付出了很多代價;編程真的很難,”他說。
Gwennap在去年年底的一項分析中指出,DSP也將發揮作用。Cadence、Ceva和Synopsys都提供面向神經網絡的DSP內核,他說。
加速器缺乏共同的基準
這些芯片即將到來時,架構師們卻還不確定如何評估這些芯片。
Patterson回憶說,就像RISC處理器的早期,“每個公司都會說,'你不要相信別人的基準,但是你可以相信我的',這可不太好。”
那個時候,RISC廠商們在SPEC基準測試中進行合作。現在,深度神經網絡加速器需要自己定義的測試套件,涵蓋各種數據類型的訓練和推理,以及獨立芯片和集群芯片。
聽到這個呼吁,Transaction Processing Performance Council(TPC)在12月12日宣布成立了一個工作組來定義機器學習的硬件和軟件基準。TCP是由20多個頂級服務器和軟件制造商組成的團體。TPC-AI委員會主席Raghu Nambiar表示,這么做的目標是創建各種測試,并且這些測試不關乎加速器是CPU還是GPU。但是,這個團隊的成員名單和時間框架還在不斷變化之中。
百度在2016年9月發布了一個基于其深度學習工作負載的開放源代碼基準測試工具,使用32位浮點數學做訓練任務。百度在6月份更新了DeepBench以涵蓋推理工作和16位數學的使用。
由哈佛大學研究人員發表的Fathom套件中,定義了8個人工智能工作負載,支持整數和浮點數據。Patterson表示:“這是一個開始,但是要獲得一個讓人感覺舒適的、全面的基準測試套件還需要更多的工作。”
“如果我們致力于打造一個很好的基準,那么所有用在這個工程上的錢都是物有所值的。”
除了基準之外,工程師還需要追蹤仍在演變的神經網絡算法,以確保他們的設計不會被淘汰。
高通公司下一代核心研發總監Karam Chatha表示:“軟件總是在變化的,但是你需要盡早把硬件拿出來,因為它會影響軟件——這種關系總是存在的。目前,這家移動芯片廠商正在Snapdragon片上系統的DSP和GPU內核上運行神經網絡工作,但一些觀察家預計,高通將為機器學習定制一個新的模塊,作為2019年的7納米Snapdragon SoC的一個組成部分。
高通公司展示了一個自定義深度神經網絡加速器的研究范例,但是現在高通在通用的DSP和GPU核心上使用軟件。來源:高通
Patterson表示:“市場會決定哪些芯片最好。這是很殘酷的,但這正是設計計算的興奮點所在。”
早期的玩家已經抓住了這個偶然的機會。
例如,Facebook最近證明,通過大幅增加打包到所謂批量大小的功能數量,將訓練時間從一天縮短到一個小時。對于試圖在本地SRAM中運行所有操作的Graphcore來說,這可能是個壞消息,因為這消除了外部DRAM訪問的延遲,同時也限制了內存占用。
“他們是為小批量設計的,但幾個月前的軟件結果表明,你需要一個大批量。這說明了事情變的話的有多么快,”Patterson說。
另一方面,Rex Computing認為他們正處于一個有利的位置。該初創公司的SoC最初是為高性能服務器設計的,使用了一種新穎的暫存器內存。聯合創始人Thomas Sohmers說,Rex的方法消除了在虛擬頁面表中緩存數據的需求,這是GPU使用的一種技術,增加了延遲。
因此他說,Rex芯片比現在的GPU要好得多,特別是在處理流行的矩陣/矢量運算神經網絡時。Rex公司計劃6月份推出256核的SoC,預計能提供256Gflops/W。
與此同時,研究人員正在嘗試從32位到單浮點和整數數學的方方面面,以找到最有效的方法來計算神經網絡結果。有一點似乎是他們認同的,最好不要在精確度之間來回切換。
人工智能算法還處于初期階段
深度神經網絡是幾十年來人工智能領域一直進行的相對較小分支的工作。從2012年左右開始,包括Facebook公司的Yann LeCun在內的很多研究人員開始使用特定種類的深度神經網絡來識別圖像,并最終以比人類更高的準確度得到令人驚嘆的結果。深度學習技術吸引了研究界,研究界迅速發表了不少該領域的論文,以尋求新的突破。
現在深度神經網絡為Amazon Alexa、谷歌翻譯、Facebook面部識別等商用服務提供動力。網絡巨頭們和他們的全球競爭對手,正在尋找殺手級應用的過程中競相將這些技術應用于盡可能多的服務中。
微軟每年都會舉辦兩個主題是人工智能的內部員工大會,最近一次規模達到5000人,前SPARC處理器架構師Marc Tremblay表示,他現在負責微軟在定制人工智能芯片和系統方面的工作。
有專家坦言,他們并不完全理解為什么現有的算法獲得了這么好的效果。關于遞歸(RNN)和卷積(CNN)神經網絡等類型的深度神經網絡相對有效性引發了各種辯論,同時,新的模式仍在開發之中。
AMD公司研究員Allen Rush在最近一次關于人工智能的研討會上表示:“各種算法非常有可能在未來五年內會發生變化。我們打賭,像矩陣乘法這樣的最底層的原語將是不可改變的。”
這就是Google在TPU上投入的賭注,最新版本的TPU是針對訓練和推理任務的,它本質上是一個大的乘法累加單元,運行和保存線性代數例程的結果。預計Nervana和Graphcore芯片也將效仿這一做法。
哈佛大學前大腦研究員、Nervana共同創始人、現任英特爾Nervana集團首席技術官Amir Khosrowshahi表示,目前在深度神經網絡方面取得的成功,正在主導著更廣泛的人工智能領域。他在IEEE研討會上表示:“由于深度學習如此成功,所以在這之下事情發展得很順利。大家都在做深度神經網絡,這是一場悲劇......不要以為現在發生的事情,一年以后還會存在。”
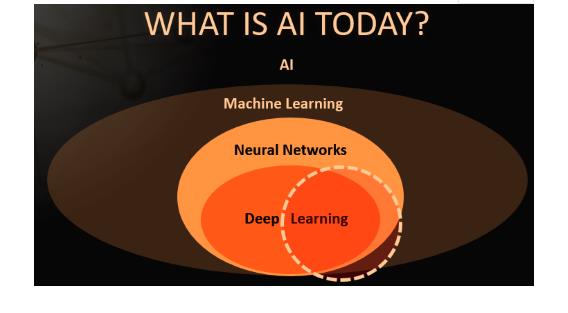
今天深度神經網絡得到了如此多的關注,但這僅代表了更為廣泛的人工智能領域的很小一部分。(來源:英特爾)
盡管深度神經網絡可以比人類更精確地識別圖像,但“如今的數據科學家被迫花費不可接受的時間對數據進行預處理,對模型和參數進行迭代,并且等待訓練的融合......每一步都要花費太多人力,或者太過于計算密集型了,”Khosrowshahi說。
總的來說,“人工智能的難題仍然很難解決,”他補充說。“最好的研究人員可以用一個機器人打開一扇門,但要拿起杯子,可能比贏過Alpha Go(深度神經網絡贏得的早期勝利之一)還難。”
在這種環境下,Facebook和Google等網絡巨頭都發布大型數據集,以吸引更多的人從事諸如對新應用領域或者視頻等數據類型進行識別的前沿問題。
先鋒者們拓展了應用前沿
隨著算法的發展,研究人員也在推動深度學習的應用前沿。
Google正在系統地將深度神經網絡運用于從自動字幕照片混合到讀取MRI掃描以及監測工廠車間質量控制等方方面面的問題。谷歌人工智能研發負責人Jia Li在IEEE研討會上表示:“人工智能不是單一的技術或產品。我們從理解一個領域開始,然后收集數據,找到算法,并提出解決方案。每一個新問題我們都需要一個不同的模型。”
的確,深度神經網絡正在被用于幾乎所有領域,包括設計和制造芯片。英特爾列舉了超過40種可能的用途,從面向消費者的網上購物助手,到華爾街自動交易程序。
現在在Target公司擔任數據科學家的一位IBM前研究人員對應用領域給予了更加清醒的認識。大部分零售商的數據都是關系型數據,而不是最適合神經網絡的非結構化數據。Shirish Tatikonda在一次大會后的簡短采訪中表示,Target公司的業務問題中只有大約10%適用于深度神經網絡。盡管如此,該公司正在積極開拓這一領域,其系統中約有10%是面向訓練神經網絡模型的GPU服務器。
為了擴展這樣大規模的努力,谷歌的研究人員正在探索他們所謂的AutoML,其想法是使用神經網絡自動生成模型,而不需要數據科學家手動調整這些模型。
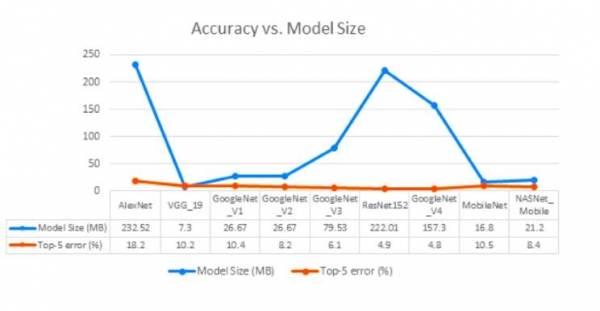
盡管最近很多公司試圖減少內存占用量,但深度神經網絡模型在尺寸上仍然差別很大。來源:高通
機器人技術先驅Rodney Brooks擔心,預期可能會失控。他在最近的一次談話中說:“深度學習是好的,但它正在成為人們用來打擊一切的工具。”
對Patterson而言,他仍然很樂觀。他說,雖然廣泛的人工智能領域沒有兌現過去的承諾,但在機器翻譯等領域的成功是真實存在的。“可能所有低處的果實都摘下來了,所以沒有什么更令人興奮的事情,但是你幾乎每個星期都會看到有進展......所以我認為我們會發現更多的用途。”
首先是努力實現軟件融合
在早期的瘋狂和分裂之中,即使是軟件融合方面所做的事情也是很分散的。百度人工智能研究團隊進行了一項調查,發現11項措施來彌補那些爭著管理神經網絡的各種軟件框架之間存在的差距。
最有希望的是Open Neural Network Exchange(ONNX),這是一個由Facebook和微軟發起的開源項目,最近Amazon也加入其中。該項目小組在12月份發布了ONNX格式的第一個版本,旨在將用把十幾個有競爭關系的軟件框架所創建的神經網絡模型轉譯為圖形化呈現。
芯片制造商可以將他們的硬件瞄準這些圖形。對于那些負擔不起為支持這些不同模型框架——例如Amazon的MxNet、Google的TensorFlow、Facebook的Caffe2以及微軟的CNTK——單獨編寫軟件的初創公司來說,這是一個好消息。
30多家主流芯片提供商組隊在12月20日發布了他們的首選項——Neural Network Exchange Format(NNEF),目標是為芯片制造商提供一種替代方案,來創建自己的內部格式,就像英特爾在Nervana Graph和Nvidia TensorRT那樣。
百度在各種各樣的格式中發現了ISAAC、NNVM、Poplar和XLA。百度硅谷人工智能實驗室高級研究員Greg Diamos表示:“現在去預測是否會出現一個成功的實施,可能還為時尚早,但我們正在走上一條更好的道路,其中一條最終取得勝利。”
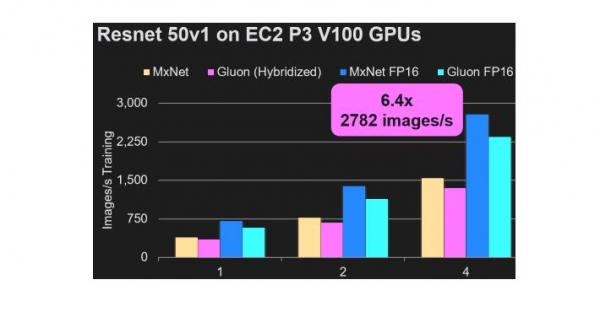
在這些人工智能框架中,Amazon宣稱自己的MxNet框架和新出現的Gluon API提供了最高的效率。(來源:Amazon)
此外,谷歌已經開始致力于開發軟件來自動化精簡深度神經網絡模型,這樣這些模型就可以運行在從智能手機物聯網(IoT)節點的方方面面。如果成功的話,可以將50Mb的模型降低到500Kb。
谷歌也已經在探索在手持設備上做有限的模型訓練,調整模型的頂層,或者基于白天收集的數據在夜間進行處理。像SqueezeNet和MobileNet等,也展示了更簡單的成像模型路徑,且同樣精確。
負責Google TensorFlow Lite工作的Pete Warden表示:“我們看到有很多人在各種各樣的產品中使用機器學習,每次操作降低1皮焦,這是我每天熬夜在做的事情。”
展望未來
當專家認真看待人工智能未來的時候,他們會看到一些有趣的可能性。
今天我們使用基于手動調整模型的監督式學習。谷歌的Warden就是預見未來會出現半監督方法的研究人員之一,他認為未來手機等客戶端設備可以進行自主學習,最終目標是無監督式學習——計算機自學,而不需要工程師們的幫助。
在這條道路上,研究人員正在尋找方法來自動標記數據,因為這些數據是由手機或物聯網節點等設備收集的。
西部數據公司首席數據科學家Janet George表示:“谷歌稱,現在在這個中間階段我們需要大量的計算,可一旦事情被自動標記,你只需要索引新的增量內容,這更像是人類如何處理數據的方式。”
無監督式學習打開了一扇通向加速機器智能時代的大門,有些人認為這是數字化的必殺技。另一些人則擔心技術可能會在沒有人為干預的情況下以災難性的方式失控。谷歌公司TPU項目負責人Norm Jouppi說:這讓我感到害怕。
同時,從事半導體工作的學者對未來的人工智能芯片的發展由他們自己的長遠愿景。
英特爾、Graphcore和Nvidia“已經在制造全掩膜版芯片,下一步就是3D技術,”Patterson說。“當摩爾定律如火如荼時,由于擔心可靠性和成本問題人們可能會退縮。現在摩爾定律正在結束,我們將看到很多這方面的實驗。”
最終是創造出新型的晶體管,可以在邏輯和內存層進行片上堆疊。
Notre Dame電氣工程教授Suman Datta很看好負電容鐵電晶體管作為此類芯片的基礎。他在最近召開的一次關于所謂單體3D結構的會議上談到了該市場的格局。這樣的設計應用并推進了3-D NAND閃存在片上芯片堆棧方面所取得的進展。
來自伯克利、麻省理工學院和斯坦福大學的團隊將在2月份的國際固態電路會議上,展示一個類似的具有遠見的架構。該芯片(下圖)將電阻RAM(ReRAM)結構堆疊在一個由碳納米管制成的邏輯上的相同模片上。
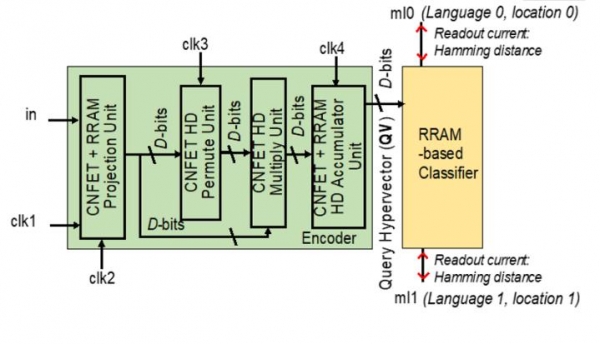
來自伯克利、麻省理工學院和斯坦福大學的研究人員將在ISSCC上發布報告,關于一種使用碳納米管、ReRAM和圖形作為計算元件的新型加速器。(來源:加州大學伯克利分校)
該設備從深度神經網絡獲得靈感,被編程為具有類似的模式而不是使用計算機一直在使用的確定數字。伯克利教授Jan Rabaey說,這個所謂的高維計算使用了幾萬維的向量作為計算元素。Rabaey為該報告做出了貢獻,同時也是英特爾人工智能顧問委員會的成員。
Rabaey說,這種芯片可以從樣例中進行學習,與傳統系統相比操作要少得多。測試芯片將很快出爐,使用振蕩器陣列作為與相關存儲器陣列中的ReRAM單元配對的模擬邏輯。
Rabaey在IEEE人工智能研討會上表示:“我夢想著可以隨身攜帶的引擎,當場就能給我提供指導......我的目標是推動以小于100毫伏的功耗運行[人工智能]。我們需要重新思考如何做計算。我們正在從基于算法的系統轉向基于數據的系統。”
















 京公網安備 11010502049343號
京公網安備 11010502049343號