









馬特還是紐約乃至美國知名的技術趨勢“布道者”,他發起組織了2大新趨勢分享社區,一個圍繞大數據和人工智能,名為Data Driven NYC;另一個圍繞前沿技術和新興計算平臺,叫Hardwired NYC。
2018人工智能&大數據全景圖

全景圖涵蓋了大數據人工智能行業的基礎架構、開源框架、數據API、數據資源、跨基礎結構分析、工業應用、企業應用、分析工具等,涵蓋有1095家大數據公司被納入全景圖。
出現在全景圖的一些關鍵公司上市了,尤其是Cloudera、MongoDB Pivotal和Zuora。在撰寫本文時,其他的正在準備上市,比如Elastic。
2018年人工智能大數據發展趨勢
2018 年,是數據世界中激動人心但又復雜多變的一年。一方面,數據技術(大數據、數據科學、機器學習、人工智能)繼續發展,變得越來越高效,在世界各地企業也得到了廣泛的應用。到目前為止,2018 年企業界的關鍵主題之一是“數字化轉型”,這絕非偶然。這個詞語對有些人來說可能有點奇怪,他們會嘀咕:這難道不是過去 25 年來一直發生的事兒嗎?但它恰恰反映出一個事實:許多傳統的行業和企業現在正全力投入到真正的數據驅動之旅。另一方面,更廣泛的公眾群體已經意識到數據的缺陷。無論是通過關于人工智能風險的公開辯論、劍橋分析公司(Cambridge Analytica)丑聞、大規模的Equifax數據泄露、與gdp相關的隱私討論,還是有關中國政府監控活動日益增多的報道,數據世界已開始暴露出一些更陰暗、更可怕的隱患。
1)基礎設施和分析工具
從行業的角度來看,數據生態系統仍然像以往一樣令人興奮和充滿活力,擁有豐富的創新初創企業、成熟的“規模擴展”,以及許多積極的公共技術供應商。最重要的是,許多大大小小的客戶都在大規模地應用這些技術,并從他們的努力中獲得不可否認的價值。
隨著用更現代的數據產品替代舊的IT技術的循環繼續,大數據市場(基礎設施、分析)似乎正在快速地在早期的大多數買家中循環,并逐漸過渡到傳統采用曲線的晚期。
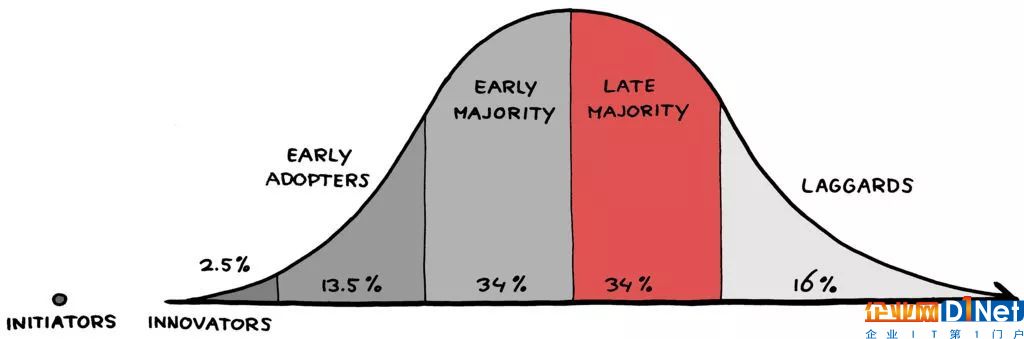
此外,數據世界繼續朝著云的方向發展。考慮到大型公共云服務提供商(AWS、Azure、谷歌云平臺、IBM)的增長速度,每個季度都能產生數十億美元的收入,這真是令人震驚。這一趨勢引發了對供應商鎖定的持續關注,這可能為提供多云解決方案的初創公司提供機會。然而,到目前為止,采用多云策略的公司仍然傾向于依賴一個供應商作為他們的主要提供者。
隨著他們的業務不斷發展,大型云提供商通過其平臺(如 Amazon Neptune、Google AutoML 等)提供一系列廣泛的大數據、數據工程和機器學習工具,通常都制定了激進的定價策略,因而相互競爭越來越激烈,這一切都是為了吸引更多的開發者,因為他們真正的商業模式是數據存儲。隨著此類工具的范圍和成熟度不斷提高,這對數據技術領域產生了重大影響,可以說,初創企業更難與之競爭,至少在廣闊的、橫向的機遇面前就是如此。每年在大型云供應商會議上發布的產品公告列表(如 AWS re:Invent)會給初創企業帶來巨大的沖擊波,因為他們將云供應商與數十家風投支持的初創企業直接競爭。看看公眾市場如何應對即將到來的 Elastic(一家開源軟件企業)IPO 將是一件有趣的事。
然而,只要初創企業有足夠的差異化,他們還是有很多機會的。在這個領域中,很多企業都在快速擴展,在生態系統的基礎設施和分析部分中有許多特別有趣、快速增長的部分,包括流 / 實時、數據管控和數據結構 / 虛擬化。人們對人工智能的興趣激增,也帶來了在人工智能芯片、GPU 數據庫、人工智能 DevOps 工具以及能夠在企業中部署數據科學和機器學習的平臺上的巨大機遇,以及大量資金。
2)機器學習和人工智能
在人工智能研究領域,這無疑是瘋狂的一年,從 AlphaZero 的威力到新技術發布的驚人速度——生成對抗網絡的新形式,替代型的遞歸神經網絡,Geoff Hinton 的新膠囊網絡。像 NIPS 這樣的人工智能會議已經吸引了 8000 人,每天都有成千上萬的學術論文提交。
與此同時,對 AGI 的追求仍然難以捉摸,這也許是值得謝天謝地的事兒。目前人們對人工智能的興奮和恐懼,大部分源于 2012 年以來令人印象深刻的深度學習表現,但在人工智能研究領域中,有一種情緒在人們中日益彌漫開來:“接下來怎么辦?”因為有些人質疑深度學習的基礎(反向傳播),而其他一些人希望能夠超越他們所認為的“蠻力”方法(大量數據、大量算力),或許更傾向于采用更多基于神經科學的方法。
在人工智能研究領域,許多人非但不擔心機器人主宰世界,反而擔心,該領域持續的過度炒作可能最終會讓人失望,并導致另一個人工智能核冬天的到來。
然而,在人工智能研究之外,我們正處于一波深度學習在現實世界中的部署和應用浪潮的開端,涉及不同行業的語音識別、圖像分類、對象識別和語言等各種問題。如果說生態系統的基礎設施和分析部分已經發展到后期的大多數,那么對于企業和垂直人工智能應用來說,我們仍然是非常早期的先驅者。
盡管人工智能初創市場可以說已經顯示出最終降溫的跡象,但以深度學習為基礎的初創企業在一兩年前開始暴增的情況依然在繼續。整體規模和估值的期望仍然很高,但 我們肯定已經經過了這樣一個階段:大型互聯網企業會為了人才而高價收購早期人工智能初創企業。 與其他一些利用這種炒作的企業相比,市場中也出現了一些“真正”的人工智能初創企業。在 2014~2016 年期間成立的一些人工智能初創企業正開始初具規模,許多企業在醫療、金融、“工業 4.0”和后臺辦公自動化等跨行業和垂直領域提供越來越有趣的產品。在未來的幾年里,深度學習將繼續為現實世界的應用帶來巨大的價值,而專注于垂直方向的人工智能初創企業將面臨許多巨大的機遇。
這種持續的爆炸在很大程度上是一個全球現象,加拿大、法國、德國、英國和以色列都特別活躍。然而,中國在人工智能方面似乎處在一個完全不同的水平,有報道稱,政府主導的數據匯集規模令人難以置信(跨越了互聯網企業和市政當局),面部識別和人工智能芯片等領域的迅速發展,以及為初創企業提供數輪巨額融資:根據 CB Insights 的數據,中國僅占全球人工智能交易份額的 9%,但 2017 年在全球人工智能資金的比例接近 48%,高于 2016 年的 11%(見下面的一些例子)。
同樣,數據隱私(以及所有權和安全性)問題也正成為全球關注的主要問題。在互聯網發展的早期,數據隱私是為了保護我們在網上所做的事情,這是我們活動中相對較小的一部分。相應地,只有一小部分人真正在乎數據隱私的問題。隨著我們個人和職業生活的方方面面都通過越來越多的聯網設備連接到互聯網上,利害關系正在發生變化。人工智能能夠在大量數據集中發現異常、預測結果和識別人臉,這使數據隱私問題變得更加復雜。
另一個獨立但相關的問題是,這些數據中有很多都屬于大型互聯網企業 (GAFA) 所有。有些企業,比如 Facebook,已經被證明不是完美的管理者。盡管如此,這些數據為他們在生產更強大人工智能的競爭中提供了不公平的優勢。
針對這些問題,一個新興的主題是把區塊鏈看作是對抗人工智能風險的一種可能的方式,同時也是在 GAFA 之外的企業生產更為出色的人工智能的另一種方式。加密經濟被視為一種激勵個人提供個人數據的方式,也是機器學習工程師通過匿名處理這些數據建立模型的一種方式。這一切仍處于試驗階段,但一些早期的市場和網絡正在出現。
















 京公網安備 11010502049343號
京公網安備 11010502049343號