









2017年,許多的人工智能算法得到了實踐和應用。名博Hack Noon作者 Brian Muhia 認為想要玩轉人工智能,不僅要擁有必要的數學背景知識,還需要擁有實際的人工智能項目經驗。
因此,Muhia參加了一個叫AI Grant的人工智能比賽,并在去年9月,申請了 fast.ai 網站上杰里米·霍華德(Jeremy Howard)教授的“實用深度學習”(Practical Deep Learning for Coders,第二版)的第一部分。
僅用了7周多,Muhia 就學會了如何使用8種人工智能技術來進行工程實踐,并進行了歸納整理。
對于每一種實踐方法,Muhia 都用了簡短的 fastai 代碼來概述總體思想,并指出該技術是否普遍適用,例如:對于圖像識別和分類,自然語言處理,對結構化數據或協同過濾進行建模),或者對于某種特定的深度學習的數據類型。
原作者注:在這篇博文中,圖像識別技術使用的數據集來自于Kaggle上的兩個競賽。
Dogs vs. Cats: Kernels Edition, Dog Breed Identification
鏈接:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/
Planet: Understanding the Amazon from Space
鏈接:https://www.kaggle.com/c/planet-understanding-the-amazon-from-space
文中提到的所有實踐方法都是通過 Jupyter Notebook 這個高效接口來完成的,PyTorch 本身和 fastai 深度學習庫均支持 Jupyter Notebook。
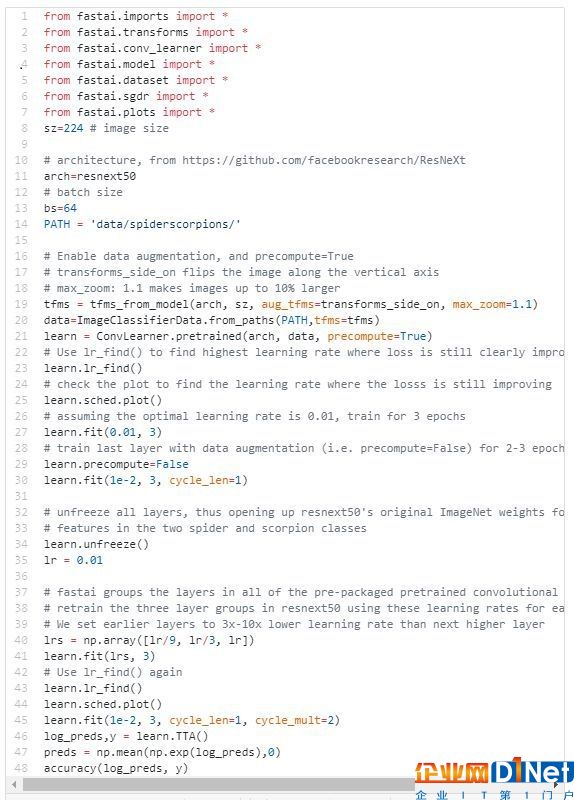
Muhia 設計了一個類似于狗與貓競賽的分類任務,即分類蜘蛛與蝎子圖片(Spiders vs. Scorpions)。通過在谷歌上搜索“蜘蛛”和“沙漠蝎子”,作者從Google Images上下載了約1500張圖片,然后作者從中去除了非jpg圖像和不完整的圖像。剩下大約815張圖片用作任務分類的數據。
訓練集中每個類 [spiders,scorpions] 有290張圖片,在測試/驗證集中有118張蜘蛛圖片和117張蝎子圖片。通過一系列訓練后,作者采用的模型擁有高達95%的分類準確率。
?
如何構建任意類別(world-class)的圖像分類器
▌八大深度學習最佳實踐
1. 通過微調的VGG-16和ResNext50模型來完成遷移學習(用于計算機視覺和圖像分類)
通常,對于圖像分類任務,采用神經網絡架構效果普遍較好,針對具體問題,你可以通過微調效果較好的神經網絡,來大幅改善分類器的性能。。
50層的卷積神經網絡-殘差網絡 ResNext50 就是一個不錯的選擇。該網絡使用了 ImageNet 數據集上的1000種類別進行了預訓練,效果表現非常好。它可以將圖像數據中的特征進行提取并多次利用。
當我們想要用它來解決實際問題時,我們只需替換掉最后的輸出層,即用一個二維的輸出層替換原來 ImageNet 任務中的1000維輸出層。這兩個輸出類別存在于上面代碼片段中的PATH文件夾中。
對于蜘蛛與蝎子分類任務的挑戰,我認為以下幾點需要注意:

請注意,訓練集文件夾的兩個內容本身就是文件夾,每個文件夾包含了290張圖像。
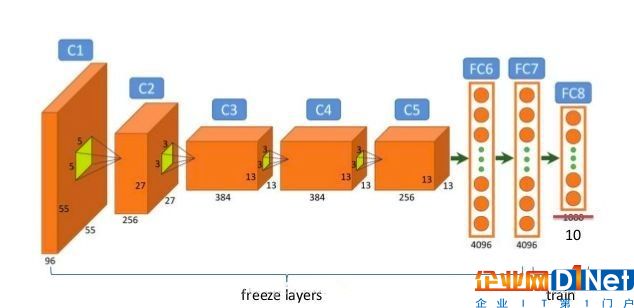
下圖顯示了一個微調過程的示例圖,它將最終層輸出從1000維調成了10維:
??
2. 周期性學習率(通常適用)
學習率應該是訓練深層神經網絡最重要的超參數。一種普遍的做法是:在一個非自適應設置中(即不使用 Adam、AdaDelta 或它們變體的算法),由深度學習工程師/研究員進行多組并行實驗,每組實驗在學習率上有微小的差異。這種做法對數據和參與人員的要求都極高,經驗的缺失或者數據集龐大且易出錯都可能使整個過程消耗更多的時間。
然而,在2015年,美國海軍研究實驗室的Leslie N. Smith發現了一種自動搜索最有學習率的方法,即從極小值開始,在網絡中運行一些小批量( mini-batch )數據,調整學習率的同時觀察損失值的變化,直到損失值開始降低。
這里有兩個fast.ai的學生解釋周期性學習速率方法的博客。
http://teleported.in/posts/cyclic-learning-rate/ https://techb
https://techburst.io/improving-the-way-we-work-with-learning-rate-5e99554f163b
在fastai中,你只需在學習的對象上運行lr_find()函數,學習率退火算法就能發揮效用。同時,sched.plot()函數可以用來確定與最優學習速率相一致的點。
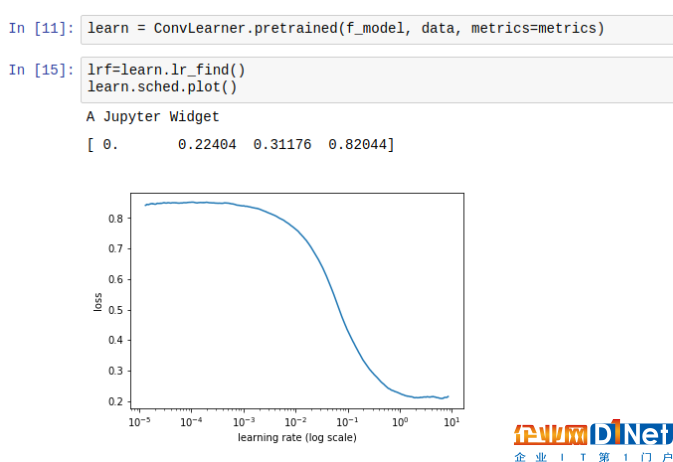
0.1似乎是一個不錯的學習率
下面論文中的數據表明:0.1的學習率表現更好,能達到最高的準確性,并且在衰減速度上比原始的學習率和指數級的學習率快了兩倍。
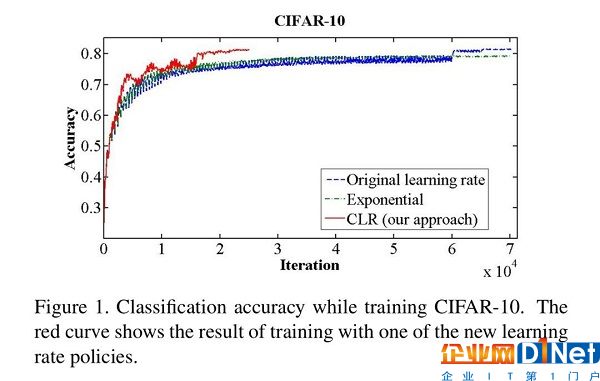
Smith (2017) “Cyclical learning rates for training neural networks.”
3. 可重啟的隨即梯度下降
??
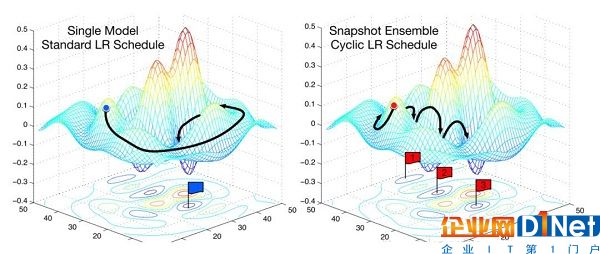
SGD vs. snapshot ensembles (Huang et al., 2017)
另一種加速隨機梯度下降的方法是,隨著訓練的進行,逐漸降低學習的速率。這種方法有助于觀察學習速率的變化與損失值的改善是否一致。當模型的參數接近最佳權重時,你需要采取更小的移動步長,因為如果步長過大,你可能會跳過損失值表面的最佳區域。
如果學習率和損失值之間的關系不穩定,即如果學習率中一個微小的變化就導致損失值的巨大變化。這就表明,當前的最優點還不在一個穩定的區域(如上面的圖2所示)。應對策略則是周期性地提高學習率。
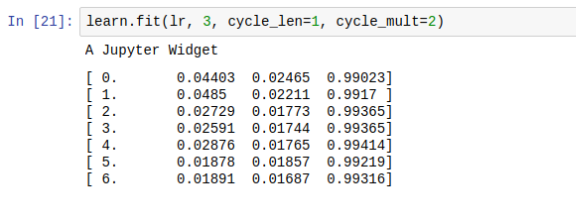
這里的“周期”是指提高學習率的次數。在 fastai 中,可以使用 cycle_len 和 cycle_mult 參數來設置 learner.fit。
在上面的圖2中,學習速率被重置了3次。在使用正常的學習速率時間表時,通常需要更長的時間才能找到最佳的損失。在這種情況下,開發人員會等待所有的時間點完成后,再嘗試不同的學習速率。
??
4. 數據增強(計算機視覺和圖像分類任務 —現在的方法)
數據增強可以用來增加現有的訓練和測試數據量。對于圖像問題,則取決于數據集中具有對稱性質的圖像數量。
一個例子是蜘蛛與蝎子圖片分類的挑戰。 在這個數據集中,許多圖片進行了垂直變換后,里面的動物仍能正常顯示。 這就是所謂的 transforms_side_on。
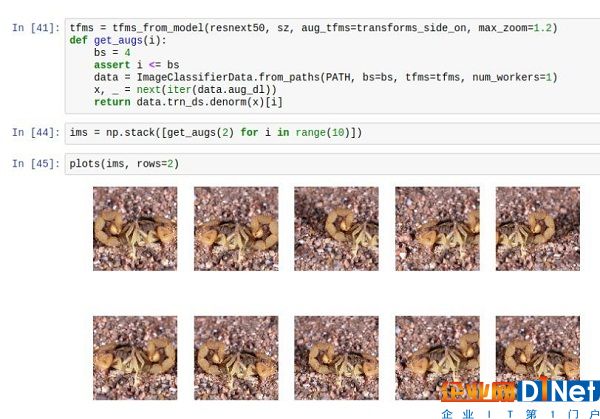
從上到下,注意圖片不同角度的縮放和反射
5. 測試時間進行數據增強(計算機視覺和圖像分類任務 —現在的方法)
我們也可以在推理時間(或測試時間)中使用數據增強。在推理預測的時候,你可以使用測試集中的單個圖像來完成數據增強。但是,如果訪問的測試集中的每個圖像都能隨機生成幾個增量圖片,則該過程會變得更加魯棒。在fastai中,我在預測時使用了每個測試圖像的4個隨機增量,并將各個預測的平均值用作該圖像的預測。
6. 用預訓練的循環神經網絡替換詞向量(word vectors)
這是一種不使用詞向量就可以獲得任意類別的情感分析框架方法。它的原理是,將需要分析的整個訓練數據進行集中,并從中構建一個深層的循環神經網絡語言模型。當訓練的模型精度增高時,就將此時模型的編碼器保存,并使用從編碼器中獲得的嵌入來構建情感分析模型。
用循環神經網絡要優于單詞向量獲得的嵌入矩陣,它可以比單詞向量更好地追蹤長距離的依賴性。
7. 時間反向傳播(BPTT)(用于NLP)
深度循環神經網絡的隱藏狀態往往會隨著反向傳播的訓練時間變得越來越臃腫,也變得難以處理。
例如,在處理字符的循環神經網絡時,如果你有一百萬個字符,那么你就需要建立一百萬個隱藏狀態向量以及他們對應的歷史信息。為了訓練神經網絡,我們還需要對每個字符執行相同數量級的鏈式計算法則。這將消耗巨大的內存和計算資源。
所以,為了降低內存需求,我們設置了最大的反向傳播距離。由于循環神經網絡中的每個循環相當于一個時間步長,所以限制反向傳播并保持隱藏狀態的歷史層數的任務被稱為時間反向傳播。雖然這個數字的值決定了模型計算的時間和內存要求,但它同時提高了模型處理長句或動作序列的能力。
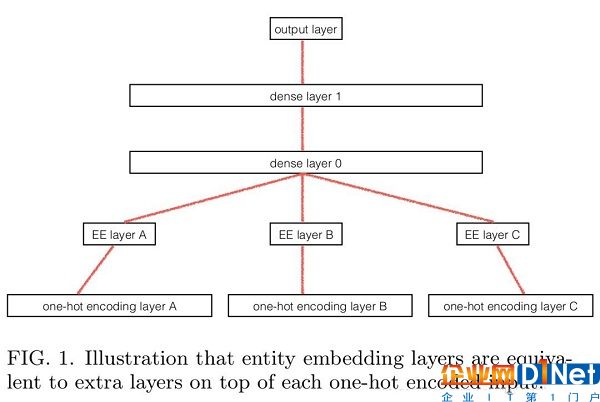
8. 分類變量實體向量化。 (用于結構化數據和NLP)
當對結構化的數據集進行深度學習時,該方法能將包含連續數據的列,例如在線商店中的價格信息,和分類數據的列,例如,日期和接送地點等,以此進行區分。然后,這些分類列的單熱 (one-hot) 編碼過程會被轉換為指向神經網絡全連接層的查找表。因此,神經網絡模型就有機會繞過列的分類性質,去了解那些被忽略的分類變量/列的信息。
這種方法可以用來學習多年的數據集的周期性規律,例如一周中的哪一天銷售量最大,公眾假期之前和之后發生了什么事。
這樣做的最終結果是能產生一個非常有效的方法,它能幫助協同過濾和預測產品的最優定價。這也是目前所有擁有表格數據的公司進行標準數據分析和預測的方法。
▌結語
這一年來,深度學習進步斐然。大批研究人員和從業人員的努力,使得數據集和CPU越來越完善,開源的深度學習框架和工具也越來越多。
目前,我們還沒有創造出通用人工智能,但是我們已經可以將深度學習運用到不同的領域了。不過,我更期待人工智能在于教育和醫學領域的運用,尤其是復興生物技術。因為,這會創造出更多的可能性。
















 京公網安備 11010502049343號
京公網安備 11010502049343號