


目前,領(lǐng)英在全球有5億9000萬(wàn)用戶、3000萬(wàn)家公司、2000萬(wàn)個(gè)工作,這是領(lǐng)英的全球經(jīng)濟(jì)圖譜。領(lǐng)英致力于連接全球職場(chǎng)人士,并協(xié)助他們事半功倍,發(fā)揮所長(zhǎng)。我們希望連接全世界的同行,為他們提供更多的職業(yè)發(fā)展機(jī)會(huì)。
在中國(guó),我們有4400萬(wàn)用戶,領(lǐng)英中國(guó)的商業(yè)和各方面都發(fā)展得非常迅速。
人工智能——領(lǐng)英的“氧氣”
人工智能是領(lǐng)英所有用戶體驗(yàn)的DNA,它就像是領(lǐng)英的氧氣,是我們一切工作的驅(qū)動(dòng)力,我們將人工智能技術(shù)應(yīng)用到了領(lǐng)英所有的產(chǎn)品中。在恰當(dāng)?shù)臅r(shí)間、恰當(dāng)?shù)牡攸c(diǎn)給恰當(dāng)?shù)挠脩敉扑]恰當(dāng)?shù)膬?nèi)容,這是領(lǐng)英人工智能研發(fā)部門(mén)的使命。
我們很多產(chǎn)品都深入地應(yīng)用了人工智能,比如你所認(rèn)識(shí)的人、我們主頁(yè)上的內(nèi)容、職位推薦、搜索、為招聘專員和銷(xiāo)售專員專門(mén)定制的產(chǎn)品……
目前,每天領(lǐng)英平臺(tái)上被處理的數(shù)據(jù)達(dá)到了2PB的規(guī)模,領(lǐng)英的機(jī)器學(xué)習(xí)模型動(dòng)輒擁有上十億甚至上百億個(gè)參數(shù),每個(gè)星期都會(huì)有上百個(gè)AB在線測(cè)試在運(yùn)行,由此可見(jiàn),領(lǐng)英AI體量是非常龐大的。那么如何在這樣一個(gè)大規(guī)模的計(jì)算平臺(tái)上、在幾百毫秒延遲的范圍內(nèi),提升用戶的使用體驗(yàn)?zāi)?這是一個(gè)很大的挑戰(zhàn)。
領(lǐng)英的職位推薦系統(tǒng)
職位推薦是領(lǐng)英的主打產(chǎn)品。那么在這方面,我們是如何應(yīng)用人工智能來(lái)解決具體的技術(shù)問(wèn)題呢?
用戶在領(lǐng)英上傳個(gè)人簡(jiǎn)歷,平臺(tái)會(huì)推薦適合求職者的工作職位,但首先,領(lǐng)英需要了解你的背景,從哪個(gè)學(xué)校畢業(yè),在哪些公司工作過(guò),擁有哪些技能……根據(jù)以上,我們可以預(yù)測(cè)哪些工作可能比較適合求職者。領(lǐng)英做的第一步是建立知識(shí)圖譜和研發(fā)針對(duì)自然語(yǔ)言的標(biāo)準(zhǔn)化技術(shù)。我們針對(duì)每位用戶的簡(jiǎn)歷,使用基于深度學(xué)習(xí)模型的標(biāo)準(zhǔn)化技術(shù)來(lái)實(shí)現(xiàn)信息抓取,比如LSTM, CNN等等。對(duì)于工作職位,我們也做了同樣的事情。
六七年前,我們的職位推薦一開(kāi)始做的是做線性模型,比如說(shuō)求職者是一個(gè)軟件工程師,我們就會(huì)推薦一個(gè)軟件工程師的職位。但后來(lái)我們發(fā)現(xiàn),根據(jù)用戶簡(jiǎn)歷和工作職位的描述來(lái)做推薦,不一定能夠完全實(shí)現(xiàn)個(gè)性化,我們還希望根據(jù)用戶之前的職位申請(qǐng),為他推薦更多類似的職位,我們將其稱之為深度的個(gè)性化。我們因而研發(fā)了Generalized Linear Mixed Model(GLMix),針對(duì)每個(gè)用戶和每個(gè)職位建立一個(gè)單獨(dú)為他們服務(wù)的模型,這樣使得我們模型的參數(shù)量達(dá)到了上百億的規(guī)模。同時(shí)也成功地把職位申請(qǐng)的數(shù)量提高了30%。領(lǐng)英中國(guó)團(tuán)隊(duì)把這個(gè)模型用在中國(guó)的數(shù)據(jù)上,又將職位申請(qǐng)的數(shù)量額外提高了11%。
進(jìn)一步地,我們建立了一個(gè)Deep & Wide的模型,其中整合了深度學(xué)習(xí),樹(shù)狀結(jié)構(gòu)模型,以及GLMix,我們發(fā)現(xiàn)這個(gè)模型的效果非常好,也極大地提升了領(lǐng)英的用戶體驗(yàn)。為了實(shí)時(shí)更新上百億的模型參數(shù)以及在毫秒級(jí)別內(nèi)滿足用戶的職位推薦需求,領(lǐng)英搭建了大規(guī)模運(yùn)算平臺(tái)來(lái)實(shí)現(xiàn)人工智能模型的技術(shù)。這個(gè)平臺(tái)包括線下和線上兩個(gè)模塊:線下模塊自動(dòng)收集用戶的反饋、基于Spark自動(dòng)訓(xùn)練,之后把模型結(jié)果和參數(shù)上傳到線上。線上我們使用自己的實(shí)時(shí)數(shù)據(jù)傳輸和搜索引擎技術(shù)來(lái)實(shí)現(xiàn)低延遲的模型運(yùn)算。并且,領(lǐng)英專門(mén)研發(fā)了一個(gè)叫做Pro-ML的“人工智能自動(dòng)化”系統(tǒng),為所有工程團(tuán)隊(duì)集中管理特征和機(jī)器學(xué)習(xí)模型。這一系統(tǒng)為機(jī)器學(xué)習(xí)模型的整個(gè)開(kāi)發(fā)、培訓(xùn)、部署、測(cè)試提供單一化平臺(tái),已經(jīng)極大加快了領(lǐng)英開(kāi)發(fā)及上線新產(chǎn)品的速度。
我們?cè)诼毼煌扑]方面也遇到過(guò)一些有意思的問(wèn)題。下圖說(shuō)的是一個(gè)邊際收益遞減的例子,比如我是一個(gè)招聘專員,剛剛發(fā)布了一個(gè)工作到網(wǎng)上,那么我收到的第一份申請(qǐng)是最有價(jià)值的,因?yàn)槲抑耙粋€(gè)申請(qǐng)都沒(méi)有收到。但等到第100個(gè)人申請(qǐng)的時(shí)候,這個(gè)邊際價(jià)值就不一定比以前多了,因?yàn)?00到101和從0到1完全不是一回事。等到有上萬(wàn)個(gè)工作申請(qǐng)的時(shí)候,可能反饋就是,我們不小心收了1萬(wàn)份簡(jiǎn)歷,我們看不過(guò)來(lái),可能最后也就能看前100個(gè)。
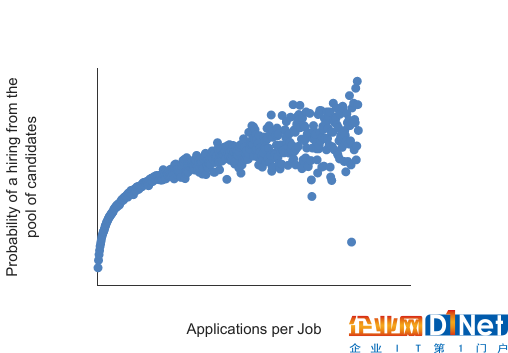
這時(shí)就體現(xiàn)了一個(gè)問(wèn)題,我們不應(yīng)只從求職者的角度去考慮問(wèn)題,也要考慮招聘者的思維。因?yàn)檎衅傅某晒β鼠w現(xiàn)了平臺(tái)的價(jià)值,如果現(xiàn)在這個(gè)平臺(tái)上面有幾千萬(wàn)個(gè)工作,可能1%的工作是Google,F(xiàn)acebook,百度,包括小米,京東這些最知名的公司,他們收的簡(jiǎn)歷數(shù)量非常大,但也有一些公司收集的簡(jiǎn)歷可能沒(méi)有那么多,或者完全沒(méi)有,那么這個(gè)平臺(tái)價(jià)值對(duì)他們就沒(méi)有體現(xiàn)出來(lái)。為什么沒(méi)有體現(xiàn)出來(lái)呢?因?yàn)槲覀冞@個(gè)平臺(tái)的目的是為了服務(wù)全世界所有的公司,是希望所有的人能夠找到他們合適的工作。并且,對(duì)于這些大公司來(lái)說(shuō),每個(gè)職位發(fā)出去,收到的上萬(wàn)個(gè)簡(jiǎn)歷中可能只能有時(shí)間看前100個(gè),這也是浪費(fèi)社會(huì)資源的一種表現(xiàn)。
所以在領(lǐng)英的平臺(tái)上做職位推薦,我們有幾點(diǎn)要注意:第一,我們要保證每個(gè)人都能找到適合的工作,第二,我們要保證每一份工作不會(huì)收到太多、或太少的申請(qǐng),我們要從整個(gè)產(chǎn)品的體驗(yàn)以及整個(gè)平臺(tái)的效率去考慮這個(gè)問(wèn)題。
在經(jīng)濟(jì)學(xué)上,這是一個(gè)市場(chǎng)效率優(yōu)化的問(wèn)題。這個(gè)市場(chǎng)有三方角色,第一方是找工作的,申請(qǐng)?jiān)蕉鄼C(jī)會(huì)相對(duì)來(lái)說(shuō)就會(huì)越大;第二方是招聘專員,他們希望每一個(gè)工作職位發(fā)出去,有足夠多的人申請(qǐng),但也不能太泛濫,最好是人選恰好就是想找的那一位;第三方就是領(lǐng)英這個(gè)平臺(tái),這個(gè)平臺(tái)想要通過(guò)這個(gè)職位推薦的市場(chǎng)得到收入。那么如何把這三方的利益綜合起來(lái)考慮,達(dá)到市場(chǎng)效率的最優(yōu)化,建立市場(chǎng)長(zhǎng)期發(fā)展的生態(tài),這本身就是一個(gè)很難的問(wèn)題,這也是我們這一兩年內(nèi)一直在做的事情。
我們?cè)?016年的KDD有一篇論文,談的就是如何平衡這三方需求。我們可以做到在不影響用戶體驗(yàn)的前提下,讓工作職位的申請(qǐng)數(shù)量更加均勻。如果用熵(entropy)來(lái)度量每個(gè)職位申請(qǐng)數(shù)量的均勻度的話,這個(gè)方法使得熵增加了12%。
領(lǐng)英在智能問(wèn)答領(lǐng)域的探索
智能問(wèn)答在領(lǐng)英有很多可能的應(yīng)用。比如剛才招聘這個(gè)案例,就可以做一個(gè)智能問(wèn)答系統(tǒng):求職者來(lái)讓我推薦工作,招聘方想了解適合某一職位在某一地區(qū)符合資格的人數(shù),這些都是很有價(jià)值的問(wèn)題,我們希望將來(lái)能夠有這樣一個(gè)智能問(wèn)答系統(tǒng),可以服務(wù)于領(lǐng)英平臺(tái)上的所有用戶。
原則上,智能問(wèn)答系統(tǒng)的開(kāi)發(fā)通常分為四步:第一,首先要做自然語(yǔ)言的處理;第二,對(duì)于對(duì)話實(shí)時(shí)信息的跟蹤;第三,根據(jù)現(xiàn)在已知的信息和對(duì)具體問(wèn)題的理解,能夠知道下一步要做什么;第四,根據(jù)下一步要做的,將它轉(zhuǎn)換成自然語(yǔ)言,給出一個(gè)回答。
在領(lǐng)英公司的內(nèi)部,每天會(huì)很多人來(lái)問(wèn)數(shù)據(jù)科學(xué)家關(guān)于領(lǐng)英數(shù)據(jù)的問(wèn)題,為了讓這一過(guò)程更加自動(dòng)化,同時(shí)減輕數(shù)據(jù)科學(xué)家們的負(fù)擔(dān),我們希望通過(guò)制造一個(gè)機(jī)器人來(lái)自動(dòng)回答這樣的問(wèn)題。我們給這個(gè)機(jī)器人取名叫做安娜(Analytics Bot)。
Ana現(xiàn)在的主要功能有兩個(gè),第一是回答關(guān)于某個(gè)具體數(shù)據(jù)指標(biāo)的定義。比如,領(lǐng)英內(nèi)部有一個(gè)數(shù)據(jù)指標(biāo)叫contributor,即每天主頁(yè)上有多少人分享,多少人評(píng)論等等,如果用戶問(wèn)contributor是什么,Ana就能夠給出回答。第二個(gè)功能是某個(gè)數(shù)據(jù)指標(biāo)在某幾個(gè)維度上的數(shù)值。比如領(lǐng)英主頁(yè)過(guò)去7天有多少中國(guó)用戶訪問(wèn),Ana就會(huì)把這個(gè)問(wèn)題自動(dòng)轉(zhuǎn)化為SQL的語(yǔ)句來(lái)查詢我們內(nèi)部的數(shù)據(jù)庫(kù),然后給出答案。






模招聘求職上的應(yīng)用")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)