









今天的人們使用智能手機拍攝的照片數量激增,這對傳統的照片分類方式造成了不小的挑戰。我們每個人整理自己手機中存儲的海量照片尚且如此困難,對我們來說,要為所有人的照片定義一種更有序的分類方式無疑更是困難重重。
每天,人們會將數十億張照片分享到Facebook,想想你自己向下滾屏查找幾天前發布的照片有多麻煩,如果要找幾個月甚至幾年前的照片呢?為了幫大家更容易找到自己的照片,Facebook照片搜索團隊使用機器學習技術深入了解照片內容,改善照片的搜索和獲取過程。
我們的照片搜索功能基于一種名為Unicorn的內存和閃存索引系統構建,這種系統在設計上可以順利搜索百億至萬億級別的用戶和其他實體。這套誕生于幾年前的系統還驅動著能夠理解社交圖譜的Graph Search功能,以每天數十億筆查詢的強大能力為Facebook的多個組件提供著支撐。
Graph Search的誕生是為了能根據不同社交圖譜之間的關系獲取相關對象,例如“所有住在舊金山的好友”。該功能的效果很不錯,但如果要將查詢約束在相關子集范圍內,并按照相關性對結果進行排序或計分,進而提供最相關的結果,這種操作中該功能的效果很一般。為了繼續完善這種技術,照片搜索團隊使用深度神經網絡,通過照片中的可視內容和可查找文字改善了圖片搜索結果的準確性。
關于照片,搜索功能需要了解些什么
雖然Imagenet Challenge等競賽中,圖片識別技術的演示已經獲得了非常低的錯誤率,但以Facebook的規模來說,理解照片內容是個很難達成的目標。好在相關應用領域的研究已經為我們提供了最先進的深度學習技術,足以在大范圍內處理數十億張照片,從中提取出可搜索的語義學含義。我們會使用一種名為圖片理解引擎的分布式實時系統,分析處理發布到Facebook且公開展示的每張照片。
圖片理解引擎是一種深度神經網絡,其中包含數百萬種可學習參數。該引擎以先進的深度殘差網絡(Deep Residual Network)為基礎,使用上千萬張帶標注照片進行了訓練,可自動預測一系列概念,包括場景、物體、動物、景點、著裝等。我們可以提前訓練模型并將有用的信息存起來,進而以低延遲響應回應用戶查詢。
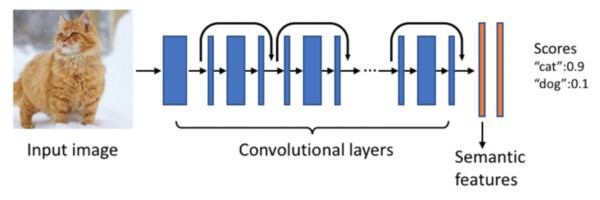
這個圖片理解引擎為語義特征生成的高維浮點向量需要進行索引和搜索,但以Facebook的規模來說,這是一種非常繁重的計算密集型任務。通過使用迭代量化和局部敏感哈希技術,該功能可進一步壓縮出數量更少,但依然足以代表大部分語義的“位”。這些緊湊的“位”信息將直接嵌入照片中,借此可直接對照片進行評級、檢索、去重等操作。搜索查詢過程中,可通過嵌入的信息調整結果的展示順序。這種技術與文檔搜索和檢索過程中使用的技術極為類似。Unicorn最初誕生時包含適用于深度神經網絡層的多種不同算法,這些算法都是針對大規模圖片集的搜索開發而來的。Unicorn可以用對象標簽和嵌入語義創建搜索查詢所需的索引。目前我們正在開發該技術的新版本,希望能將這種緊湊嵌入的信息用于低延遲檢索。
在建模過程中使用標簽和嵌入物
考慮到Facebook的規模以及用戶對快速響應查詢的預期,我們無法對整個照片庫使用過于復雜的評級模型。因此為標簽和嵌入物使用了一種相關性模型,該模型可估算相關性并以極低的延遲提供查詢結果。
概念相關性
這個相關性是通過豐富的查詢,以及使用相似性函數對比概念集得出的照片概念信號進行評估的。例如,與照片查詢中所用的“中央公園”概念直接相關的查詢概念,可將與這一話題有關的照片放在首位,并從結果中隱藏所有“離題”的照片。
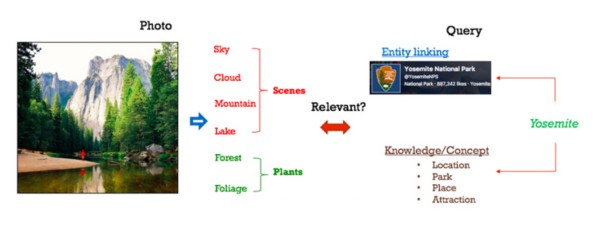
嵌入物相關性
通常來說,直接衡量查詢與結果之間的概念關聯性,這種做法不足以準確地預測相關性。我們創建的相關性模型會使用多模態學習(Multimodal learning)技術了解查詢和圖片之間的聯合嵌入關系。
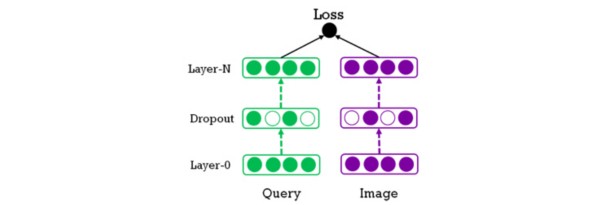
該模型的輸入端為查詢的嵌入向量和照片結果,而訓練目的在于將分類損失降至最低。每個向量將放在一起訓練和處理,這一過程會使用多層次的深度神經網絡生成一個二進制信號,結果為正意味著匹配,結果為負意味著不匹配。查詢和照片的輸入向量分別由各自的網絡生成,每個網絡可能包含不同數量的層。這種網絡可以通過嵌入層的參數進行訓練并調優。
嵌入評級損失
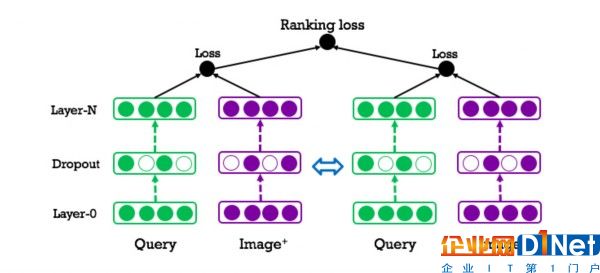
上文介紹的這種確定查詢和照片之間相關性的方法可以用公式表示為一種分類問題。然而評級的主要目標在于確定照片搜索結果中一系列照片的最佳排序。因此我們在分類公式的基礎上使用評級損失(Ranking loss)進行訓練,同時為同一個查詢生成相關和不相關結果對。
如下圖所示,模型右側部分是左側部分的深層復制(Deep copy),也就是說,他們共享了相同的網絡結構和參數。在訓練過程中,我們會將查詢與兩種結果分別放入模型的左側和右側組件中。對于每個查詢,相符圖片的評級會高于不相符圖片。這種訓練方式大幅改善了評級質量。
將對查詢的理解應用給照片搜索
Unicorn的照片語料以及圖片理解引擎所應用的嵌入物均是可搜索的。如果應用于嵌入物的查詢語義生成了更高概率的相關性,除了用于獲取照片的索引,查詢與檢索之間的其他位圖會被打斷。理解查詢語義過程中所使用的重要信號包括:
查詢意圖(Query intents)建議了需要檢索哪類場景的照片。例如一個意在檢索動物照片的查詢需要展示以動物為主題的照片。
語法分析(Syntactic analysis)幫助我們理解查詢語句的語法構造、詞類詞性、句法關系,以及語義。搜索查詢通常無法識別書面語的語法,而這方面現有的解析程序效果并不好。因此我們使用了最先進的技術,對語言標記器(Speech tagger)中神經網絡部分進行有關搜索查詢的訓練。
實體鏈接(Entity linking)幫助我們找出有關特定概念的照片,通常會將結果以頁面的形式呈現,例如不同的地點或電視節目。
重寫查詢知識以提取由查詢的語義詮釋提供的概念。概念不僅可以擴展查詢的含義,而且可以彌補查詢和結果之間不同詞匯造成的差異。
查詢嵌入物,這是一種用于代表查詢本身的連續向量空間。該技術可在對詞匯進行word2vec向量呈現的基礎上通過遷移學習(Transfer learning)進行學習,借此將類似的查詢映射至就近點。
領域和查詢重寫
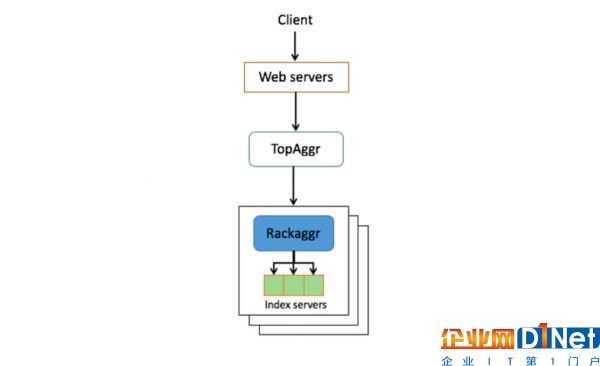
當某人輸入查詢按下搜索鍵,會生成一個請求并發送到我們的服務器。該請求首先到達Web層,在這里會收集有關該查詢的不同上下文信息。隨后查詢以及相關上下文會被發送至一個頂級聚合器層,在這里查詢會被重寫為一個s-表達式,隨后描述該如何從索引服務器獲取一系列文檔。
根據查詢意圖,會由一個觸發器機制使用神經網絡模型決定相關聯的領域(Vertical),例如新聞、照片,或視頻,這是為了盡可能避免針對相關性較低的領域執行不必要的處理任務。舉例來說,如果某人查詢“有趣的貓咪”,那么這個意圖很明顯更希望看到照片領域的結果,此時我們會從搜索結果中排除掉新聞這個領域。
如果查詢“萬圣節”,此時將同時觸發有關公開照片及好友的萬圣節變裝照片的意圖,此時將同時搜索公開和社交圈照片兩個領域,進而可同時返回搜索者的好友所分享的照片,以及評級為相關的所有公開照片。此時需要進行兩個獨立的請求,因為社交照片是高度個性化的,需要進行單獨的檢索和計分。為了保護照片隱私,我們會對搜索結果應用Facebook整個系統都在使用的隱私控制機制。下圖演示了一個上端為“社交”,下端為“公開”的模塊。
第一階段評級
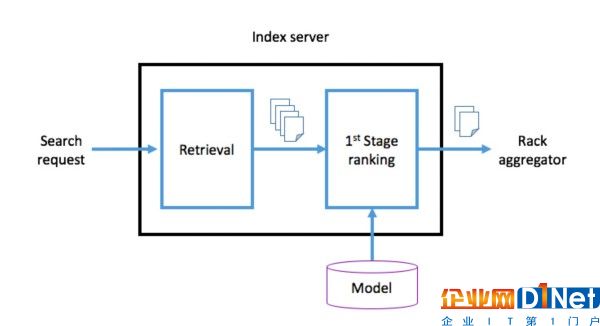
當索引服務器根據s-表達式獲取到所需文檔后,會交給經過機器學習訓練的第一階段評級器處理。隨后分數最高,Top M文檔會被發送至Rack aggregator層,借此對所獲得的全部文檔進行一定程度的合并,隨后將Top N結果返回至頂級聚合器層。第一階段評級的主要目的是確保返回至Rack aggregator的文檔與查詢依然保持一定的相關性。例如,在查詢“狗”時,包含狗的照片無疑會比不包含狗的照片獲得更高評級。為了能以毫秒級的速度提供相關照片,我們還對整個復雜的檢索和評級階段的延遲進行了優化。
第二階段的二次評級
評級后的文檔返回頂級聚合器后,會進行另一輪的信號計算、去重和評級。信號描述了整個結果分布情況的計算結果,借此可發現不符的結果。隨后會使用圖片指紋對視覺方面類似的文檔進行去重。隨后會通過深度神經網絡進行計分和評級,借此生成最終的照片排序結果。評級之后的照片集(也叫做“模塊”)會被發送到結果頁面的UI中顯示出來。
針對照片搜索優化相關性評級
對查詢與照片,以及照片與查詢之間的相關性進行評估,這是照片搜索團隊所面臨最核心的問題,并且已經遠遠超出了基于文本的查詢重寫和匹配技術范疇。為此我們需要進一步全面理解查詢、照片作者、照片附帶貼文,以及照片中的可視內容。先進的相關性模型通常需要包含頂尖的評級、自然語言處理,以及計算機視覺等技術,借此才能提供相關性更高的搜索結果,為我們塑造一種新穎的圖片分類系統,在大規模范圍內更快速提供相關性更高的搜索結果。
閱讀英文原文:Under the hood: Photo Search
感謝郭蕾對本文的審校。
















 京公網安備 11010502049343號
京公網安備 11010502049343號