









不知讀者們是否還記得 Google 公司的“張量處理器”(Tensor Processing Unit)?作為一款由該公司設計的定制版“特定用途集成電路”(ASIC),其旨在為機器學習的推力階段提供加速。Google 早期表示,與傳統 CPU 或 GPU 相比,該 TPU 可將此類任務的“每瓦特性能”提升十個數量級。不過自 2015 年推出以來,該公司現又在一篇研究分析報告中給出了最新的性能數據。
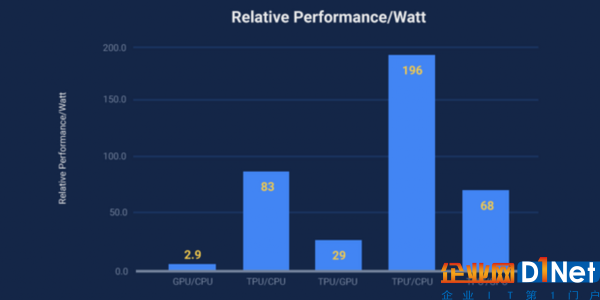
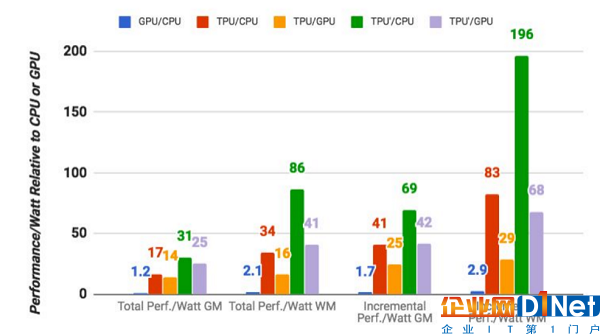
謙虛點說,Google 將每瓦特性能提升了 10x 。但與傳統解決方案相比(根據場景的不同),其數據提升在 30~80x 之間。
原始速度(RAW Speed)方面,Google 亦表示其 TPU(較標準硬件)提速幅度在 15~30x 左右。

運行在 TPU 上的軟件,是基于 Google TensorFlow 的機器學習框架,且部分性能提升得益于這方面的優化。研究報告作者表示,未來還有進一步優化的空間。
其實早在 6 年前,Google 就已經預見到了 TPU 之類的芯片需求。該公司在許多項目中運用了其機器學習算法,包括圖像搜索、Photos、Cloud Vision、以及谷歌翻譯。
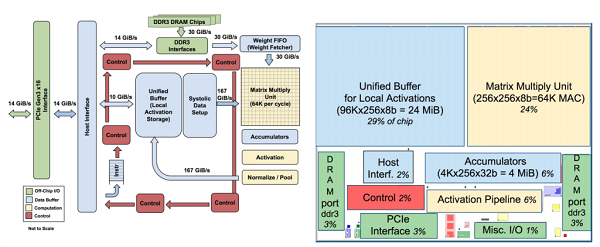
機器學習的本質是密集計算,比如 Google 工程師舉出的這個例子 —— 如果人們每天用三分鐘的語音搜索,但運行沒有 TPU 加持的語音識別人物的話,該公司將需要建造兩倍多的數據中心。
















 京公網安備 11010502049343號
京公網安備 11010502049343號