


![]()
UCloud分布式文件系統產品架構解析
UCloud存儲研發工程師鄧瑾首先就UCloud分布式文件系統產品架構進行了解析。
![]()
分布式文件系統簡介
鄧瑾表示,分布式文件系統從概念上來說,就是經典文件系統的一個延伸,通過一些分布式技術,包括現在公有云的規模,帶來了傳統文件系統所不能達到的功能和特性。分布式文件系統的經典能力,第一是Scale Out,這是分布式系統的經典特性也是其基本門檻,Scale Out能在文件系統上帶來線性或者近線性的容量和性能的提升。第二,通過分布式技術,依靠多副本、分布式協議、一致性協議,分布式系統可以提升單節點不能提供的高可用性和高可靠性,讓上層系統可以屏蔽硬件上的故障。第三,通過公有云廠商的規模效應,它能夠給應用層的用戶提供比較低的TCO。
鄧瑾接著回顧了比較經典的幾種系統,他表示,最早期的分布式文件系統是谷歌File System,以及基于GFS開發的一個開源的文件系統HDFS,它是一種面向高吞吐場景的文件系統,它還有一個特點,就是它是一種索引,并且有一些管控節點是中心化的。
第二類系統是淘寶的TFS或者是Facebook的Haystack,它們是小文件的場景,而且是一類存放圖片的對象存儲系統,一個圖片寫入之后就不會修改了。
第三類系統是GluesterFS和CephFS,它們的共同點是都是開源的,設計理念是基于去中心化的,基于動態算法來決定存儲系統的尋址,這也是大型系統比較流行的設計理念。
第四類是通用存儲系統,一類是以微軟Azure Blob Storage為代表的,包括阿里的盤古也是這套系統,它通過一個底層拓展性非常強的一個統一存儲的接口,來支撐上面不同的業務,微軟的Blob Storage都是靠這套系統來支撐的。
第五類是一些比較特定場景下的文件系統,它也是一種比較典型的設計理念,例如WAFL和PolarFS,它們都是為某些特定場景優化的,PolarFS是阿里云的一款底層的存儲系統,支持的就是PolarFS對底層系統的要求所具有的特定的一些特點。
鄧瑾還比較了對象存儲、KV和文件存儲三大類存儲系統,他表示,對象存儲在設計上其實是比較簡單的,它是一種immutable storage,寫一次后面再不會改,但是可以多次的讀,例如,S3,它天生基于面向Web的優勢,現在與CDN的結合,整個生態非常廣泛,應用也非常廣泛。但是對一些傳統的應用,它需要做改造,或者需要在客戶端上把這個API傳成對象存儲的API。對于傳統廠商,比如說醫院的設備,就不太愿意做這個改造,對象存儲可能有一些劣勢,但它的優勢是文件大小沒有上限。
KV的特點就是面向一些遞延式場景,因為它通常會用于一些緩存場景,KV系統有非常多的變種,因此在KV選擇上提供了非常高的靈活性。但是一般來說,KV系統存儲容量不會太大,因為它追求高效性。
文件存儲最大的優勢是有一套通用的文件API,現在能夠比較接近模擬API的是NFS接口。文件存儲規模可以很大,而在用單機文件系統的時候,到TB級或者百TB級就會遇到瓶頸,這個瓶頸不僅是容量上的,還有處理能力上的。分布式文件系統系統主要致力于解決消除這些瓶頸,提供一個高可用的服務。
![]()
UFS發展歷程
鄧瑾表示,UFS是一個UCloud在前年開始研發的一個完全自主研發,面向公有云設計的一款分布式文件系統,公有云產品有非常多的類型,因為一些特定需求,在公有云場景下,怎么把這些主機融入到分布式文件的訪問客戶端之內,都在UCloud文件系統設計的范疇之內。
從功能上來說,UFS現在支持V3和V4,2019年會支持Windows SMB系列,UFS的基本使命是給客戶提供高可用、高可靠的存儲服務。UCloud有一些比較典型的產品,這些產品與對象存儲、KV存儲有一些區別,它有四類場景,首先是容量型文件存儲類場景,即備份場景, 再就是數據分析類場景,像Hadoop數據分析平臺,廣電的渲染,在高性能的文件存儲上都可以得到應用。第三類就是數據共享。第四類對開發者比較有用,適用于實現Layer storage,上層做一個中間層,冗余可以丟到下層,如果文件系統可以提供高可用、高可靠數據服務的話,甚至可以把它當成一個選址服務,這是對開發人員比較大的支持。
鄧瑾表示,UFS的設計是利用開源軟件GlusterFS快速在公有云環境中進行產品原型驗證,然后從運營角度積累分布式文件產品在多租戶的公有云環境中的痛點和難點,進行自研產品的設計改進,同時吸收社區經驗,經過這樣的過程,UFS 1.0誕生了。
![]()
1.0整體架構
UFS 1.0首先是一個索引和數據分離的架構,它是對傳統文件系統一個最直接的延伸,它不采用中心節點存儲索引,而是直接把文件系統概念在分布式磁盤上模擬出來。另外,UFS 1.0的索引有一套索引管理系統,有著自定義的索引結構和語義,這將便于后續拓展非NFS協議。同時,它還具有獨立設計的存儲服務,并支持set管理、灰度等策略,還支持百萬級大目錄和TB級文件大小,也支持QoS,對多租戶場景下用戶的訪問也做了一些隔離。最后,相比GluserFS來說,UFS 1.0數據安全性較高。
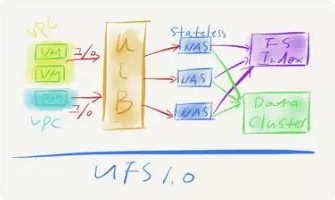
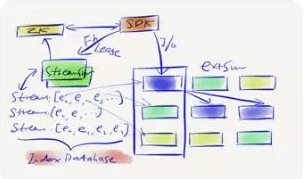
上圖是UFS 1.0的整體架構,它有一個管理平面和一個數據平面,在數據平面,左邊是用戶訪問入口,用戶在他自己的網絡專區,會有自己的很多主機,包括虛擬的云主機,物理云主機,托管云主機等等,都是通過VPC網絡來訪問接入服務,接入服務會通過UCloud的ULB負載均衡器,然后把流量導入接入服務,接入服務就是圖上的NAS。
它的特點非常明確,是一個無狀態的服務,包括NFS協議本身,這實際上是為了提升故障恢復的時候,客戶端的啟動不需要去記憶一些信息。對比單機文件系統,它也有兩類功能,一類是索引,包括尋址的功能,另一類就是數據訪問操作,UFS 1.0把這兩類東西抽象成兩個部分,紫色部分叫system index,包括目錄索引,文件索引兩部分。下面是數據集群,存儲文件的數據,在里面做一些多副本、高可靠、高可用的文件。
![]()
索引層
如下圖所示,在索引層主要就是模擬兩個概念,一個是目錄樹,傳統文件系統一個比較大的特點,就是它會有一段目錄樹,在下圖右邊有一個DIAdex,把整個目錄樹模擬下來。左邊比較簡單,它不會有層級結構,而是KV平臺的結構,它會把文件需要的一些屬性記錄下來,這里最關鍵的是它跟下層的數據層會存在同一個鏈接中,這里會記一個FH,叫做文件距離。
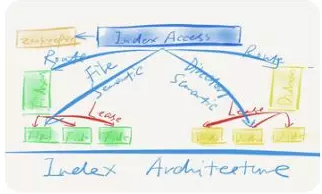
這里面比較重要的一點,是如果去做一個文件或者目錄索引,非常簡單,就是實現一個文件和目錄操作就可以了。但是它面臨的一個很大的問題,如何做到水平拓展?在多節點的操作上怎么保證原數據操作的一致性?因此,UFS 1.0會把它分成很多范圍,某個文件可能會在A節點上處理,某些文件在B節點上處理。因為在分布式系統當中,經常會遇到宕機,或者網絡導致的節點丟失,可能某個節點就沒法訪問了,這時候就需要維護一個租約,這個租約會定期續約,保證系統對這個節點的某個范圍,或者某個文件有處理權限,當失去這個租約的時候,必須把自己從集群當中踢掉,否則會出現兩個節點都對同一個文件進行操作,就會破壞后端文件系統的結構。
USF 1.0就是靠這一套系統來實現了之前一些單機文件系統不能提供的一些功能,包括處理能力的線性拓展,因為節點處理空間非常大,幾十萬甚至上百萬的節點對它進行調度,也可以依賴它來實現一個大文件和大目錄的支持,這主要還是模擬單機文件系統的概念,UFS 1.0會把一個大文件分成很多二級或者三級的一小段一小段的數據,存到這個索引中。
![]()
數據層
在數據層,一個文件存儲需要經過以下過程,首先,用戶從主機發一段數據到NAS接入層,UFS 1.0會把流失的數據,就是FH代表的文件,按4M進行切分,每4M生成一個獨立的IO請求發往存儲層,存儲層會做一個模擬,把這4M進行切分,切成64K。文件切分主要是考慮如果把一個大文件直接往存儲集群上落,磁盤空間可能會不足。因此,需要把它打散,打散有兩個好處,一是存儲會落在各個地方,IO比較平均,也不會有特別大的熱點。另外,這樣可以充分利用整個集群的容量。
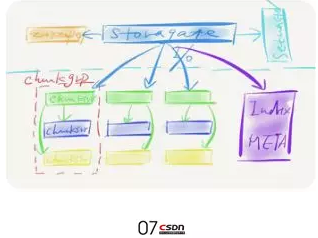
之后在存儲層,會把整個集群分成很多個,因為它本身有很多機器,每個機器上有很多磁盤,UFS 1.0把每塊磁盤分成很多個chunk,把空間分散之后,還會帶來一個好處,當發生某個chunk有熱點的時候,可以把它調到別的地方去,但如果chunk非常大,調度也沒有特別大的意義,所以要先做一個chunk切分,每個chunk有三個副本,這三個副本組成了chunk group。當一個IO請求進來的時候,這是一個最多4M的文件,會切成64K,每個64K會寫到某一個chunk group上,這64K就并發往這些chunk gourp上去寫。
下圖就是存儲層一個簡單的模型,右邊藍色的就是多集群灰度管理的系統,它可以暴露給前端業務,說明有多少集群可用。紫色的index是記錄4MB分片切成64K的一個對應關系,為什么要存這個呢?因為必須要知道這個64K是存在哪個chunk的,通過查詢它在哪個chunk,再去定位到真正的chunk所在的三個副本當中的任意一臺機器。
UFS 1.0的局限
鄧瑾介紹,UFS 1.0運營了一段時間后,發現這個存儲模型,因為支持NAS的一些隨機或者覆蓋寫引入小分片的概念,但這個分片太小了,導致存儲層那邊很難模擬一個超大文件。 然后就是底層的存儲,它是一個固定的64K,不管寫不寫滿64K,都要占用64K,這在規模很大的時候,會形成一定的空間浪費。第三是存儲層支持的文件尺度較小。第四就是對隨機寫的支持不夠,在做FIO,做4K這種寫的時候會發現延時會比較高。
![]()
UFS 2.0存儲架構
針對UFS 1.0的局限,UCloud進行了2.0架構的升級,主要對存儲層進行了優化,優化不僅僅針對NAS服務,而是進行了面向統一存儲場景的整體設計和優化,它支持超大文件,冗余機制也更靈活,同時,它通過與新硬件和軟件技術棧的結合來實現低延時高性能的場景。
![]()
Append-only模型
在底層的Stream layer,是真正的統一存儲的概念。每個存儲的文件,稱為Stream,每個Stream是永遠可以追加寫的,但是它分成了很多小分片,叫做Extent,UFS 2.0把這個Stream切成了一大段一大段很大的Extent,而且只有最后一個Extent是可以進行追加寫的,中間一旦寫完之后就再也不能改變。它帶來的好處,是這種模型非常簡單,不會擔心數據篡改或者曾經寫過的數據被覆蓋掉,或者沒有辦法回軌,因為Append-only可以很好模擬快照功能,有整個操作的歷史記錄。每個Extent被分配三個或者N個多副本,會滿足一定容災的要求,來保證副本的高可用。
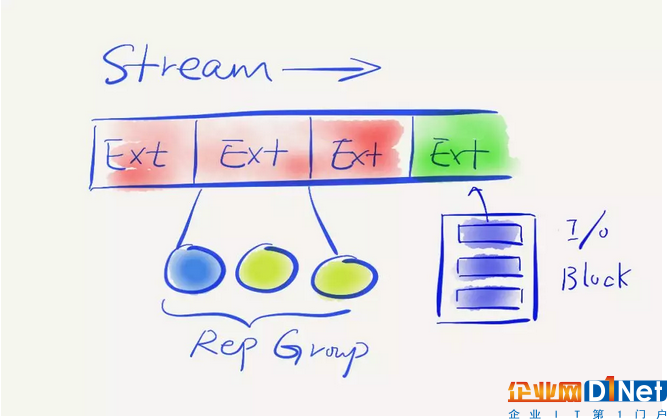
每個Extent是以文件的形式落在存儲介質上,文件可能會比較大,現在是4GB一個Extent。用戶在寫的時候是以Block為單位,往Extent上面追加,這個Block是不固定的,每次往里面追加寫之后,Extent覺得達到一定的量就可以關掉,再新開一個,這即是Append-only整個的模型。
![]()
數據層
Append-only模型里有幾個模塊,綠色的streamsvr,它管理Stream的功能,做Stream的創建,分配副本,副本所在的位置等。它會把原數據存儲在數據庫當中,Streamsvr會有一個master對外提供服務。Extentsvr做一些數據的持久化。
Extentsvr的存儲引擎設計有兩個功能,一是消除寫入毛刺,另一個是功能持久化一些還沒有落地的索引更新或者是更新操作。數據來了之后,會先落,然后更新,把它放在內存里,這個時候就可以返回成功了,業務側就可以收到,進行訪問。FileLayer的機器是高內存的,可以對數據進行緩存,它可以把整個熱點給打散,降低單節點訪問壓力以及數據讀取的毛刺。FileLayer還把整個底層Stream提供的存儲空間切分成很多個數據單元,以便于做負載均衡。
針對隨機寫,依然是利用底層的方式,把數據先追加下去,追加是追加在Date Uint(DU)提供的文件上,這樣就可以直接反饋給用戶這個隨機寫完成了,而不需要去讀老數據進行合并。帶來的開銷可以通過軟件方法去優化它。此外,針對沒有辦法結束對DU寫的問題,會對數據進行分片,每個分片的最小顆粒度是100GB,每個DU只有一個fserver進行處理,從而實現隨機寫邏輯。
![]()
分布式存儲中的數據分布算法
奧思數據創始人兼CTO李明宇則具體講解了分布式存儲中的數據分布算法,他的講解分為四部分:一致性哈希算法及其在實際應用中遇到的挑戰、典型的“存儲區塊鏈”中的數據分布算法、典型的企業級分布式存儲中的數據分布算法以及比較和總結。
![]()
一致性哈希算法及其在實際應用中遇到的挑戰
李明宇表示,常見的在分布式系統中的數據分布式算法,就是一致性哈希算法,一致性哈希算法在實際應用中會遇到很多挑戰,一方面是應用在云存儲或者企業級存儲里面的挑戰。另外就是在比較新的一些研究方向,比如說區塊鏈或者區塊鏈存儲等的方面,也會遇到一些挑戰。
![]()
哈希表及其在分布式系統中的問題
如果用一致性哈希做數據分布,經常會用到數據結構是哈希表,哈希表是把一個空間劃成N個區域,比方有一個字符串,假如這個字符串是一個文件名,根據這串字符串,會得到一個哈希。現在假如說有八個存儲位置,那么,這些數據會放在哪個存儲位置呢?哈希算法正是有著這樣的作用,因為哈希具有非常好的隨機性,因此,通過哈希算法對文件的文件名字符串進行哈希,就可以把這些數據均勻地分布到六個設備上。
但這種算法看起來很好,卻會帶來一個問題,因為在分布式存儲里面,隨著存儲的數據越來越多,系統可能就要擴充節點。而這時如果用哈希算法來算,很多數據都需要重新去分布。而當增加的節點越來越多時,幾乎所有的數據都要去移動,數據遷移的開銷是非常巨大的,系統將會無法承受。為了解決這個問題,有人發明了一種算法,將存儲平面圈起來,形成一個哈希圈,首尾相接,這樣就可以讓增加的數據更均勻的分布在設備上,而且不需要移動太多數據,比傳統的哈希表好很多。
![]()
但即使是這樣,如果需要增加一塊硬盤,還是要移動很多數據,為此,就引入了虛擬節點的概念,一塊盤不再對應一個位置,而是對應多個位置,這樣,從概率上,分布的均衡性就會好很多。此外,當有硬盤出現故障需要退出時,這種方法也會分散數據遷移的壓力,這就是一致性哈希算法。一致性哈希算法具有不需要查表或通信過程即可定位數據,計算復雜度不隨數據量增長而改變,效率高、均勻性好、增加/減少節點時數據遷移量小等優點,但在企業級IT和存儲區塊鏈場景,仍然面臨很大的挑戰。
企業存儲會用到一些方式,比方說多副本,如果隨機找幾個位置去分布,很可能會造成副本落在同一臺服務器上的情況,這種情況,企業級IT是無法容忍的。還有在存儲區塊鏈場景下,它需要用到全球的資源,讓大家自發參與進來,組成一個跨全球的大的分布式存儲系統,如果在這里面根本不知道有多少設備,也無法控制所有設備,如果來了一個存儲對象,算出了一個哈希值,就不會知道這個哈希值究竟會映射到哪個設備上,因為這個設備可能隨時出現,隨時退出,是全球參與者自發參與的,無法控制。所以幾乎不可能獲得一個全局視圖,而且一致性哈希環中的設備是隨時都會發生變化的,甚至沒有一刻是穩定的,這將帶來很大的問題。
![]()
典型“存儲區塊鏈”中的數據分布算法
那么,存儲區塊鏈剛才說的這種場景,應該怎么解決?在此之前,首先需要清楚存儲區塊鏈的概念,它是分布式存儲或者去中心存儲或者P2P的存儲加上區塊鏈,它的目的是通過區塊鏈的機制,通過token的機理,鼓勵大家貢獻存儲資源,一起組成一個大的存儲系統。存儲區塊鏈的代表項目有Sia,Storj,IPFS+filecoin。
但如果是全球用戶自發參與,就沒有去中心化的存儲系統的尋址和路由的問題,但因為參與者隨時可以加入和退出這個網絡,就需要解決這個問題,這在歷史上已經有一些代表算法,比方說Chord、Kademlia等等。
這些算法,實際上最根本的還是一致性哈希算法,Chord更難理解一些,如果有一個數據要存儲,這個數據文件名是K,數據相當于是V,整個P2P存儲網絡里面有一些節點,這些節點算出來的哈希值是14、21、32、42等,如果算出來哈希值是10,它比8大,比14小,它就應該順時針放到8和14之間的節點上,以此類推。在一個真正的P2P存儲網絡中,節點數量是眾多的,所以按照這樣順時針存,和一致性哈希沒有任何區別。現在問題是,在沒有任何節點知道到底有哪些節點參與到這個網絡中時到底應該怎么辦?Chord采用的方法是,既然沒辦法維護,就不維護,如果有一個數據,K就是其文件名,算出來的哈希值是54,那么,它先不管數據到底存在哪兒,首先和最近的一個節點比較哈希值,如果比臨近的大就繼續往下尋找,如果比自己的小,就存儲在該位置,并進行反饋。這樣,新加的節點并不需要其他節點知道,因為新加入的節點會向周圍的節點去廣播自己的存在,按道理說,總有概率說有些節點知道是新加入進來的,這樣找下去,總是能找出來。
![]()
Chord
但這樣的算法非常低效,一圈下來,延時很高。而降低這個延時有兩種辦法,一種辦法是多存幾份,降低延時的同時能提高可靠性,Chord中的一個最大的改進是Finger table,它不僅僅記錄自己的下一個節點,最臨近的節點,還記錄自己的2的i次方加1的那個位置,這個i的最大值就取決于Finger table用幾位來表示產生的索引,所以它能夠記錄最臨近的,最遠的,或者說是一半遠的,1/4遠的,等等的節點。這樣的話,如果要搜索一個數據,就沒有必要像剛才那樣挨個去找,可以直接進行跳轉,這樣就把計算復雜度降低了,這就是Chord算法。
![]()
Kademlia
在此基礎上還有另外一個算法,就是Kademlia,它跟Chord算法比起來有幾個不一樣的地方,首先計算距離的時候,并不是在用數值的大小去計算,而是用XOR計算,因此計算的復雜度就會降低。另外一方面,它設計了一個數據結構叫做K-桶,比如當前節點的id是0011,最近的節點是0010,所以它就用這種方式來表示距離,而在尋找的時候,其方法是與Chord算法是形同的。
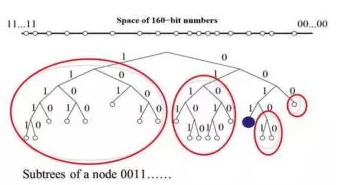
另外與Chord相比,它支持并行搜索,這樣就解決了沒有全球視圖的問題。因為不需要掌握全局到底有哪些節點參與的情況,每個節點都會周期性的向周圍發請求,如果有節點退出,就會被發現。如果有新節點加入,新加入的節點會往臨近節點廣播它的存在,所以也會被發現,節點之間互相可以聯系上。

典型的企業級存儲中的數據分布算法
具體到企業級存儲里面,這個問題變得更加復雜,關于企業級存儲中間典型的數據分布算法也有一些,比如像Dynamo里有Amazon,Ceph里有CRUSH的算法等等。這些算法都有一定的相似度,都是要對數據算哈希,對數據的K算哈希等等,然后再做映射關系。這些算法還引入了對數據中心物理拓撲的建模。比如Cluster Map,一個大的存儲集群,分幾個數據中心,每個數據中心下面可以再分zone,zone下面再分機柜,機柜下面再分節點等等,它會把這種拓撲結構給記錄下來。這樣的話,數據的分布就會根據Cluster Map分布到不同的故障域里面,這樣當一個故障域出現問題的時候,數據不會丟失,數據仍然可以訪問。這些算法中還有對節點劃分的權重,數據分布和容量/性能匹配,輔助擴容以及多種存儲策略選擇。
李明宇最后表示,歸根到底,各種算法的源頭都是一致性哈希,因為不同的需求,有不同的改進方向。企業級的更注重副本故障域的分布,對于P2P存儲更注重在節點隨時退出隨時加入的情況下,怎么樣保證數據能夠在有效時間內尋址。
![]()
云硬盤架構升級和性能提升
UCloud塊存儲研發工程師葉恒主要就云硬盤架構升級和性能提升進行了講解。
![]()
云硬盤架構升級目標
葉恒首先介紹了云硬盤架構的升級目標,第一,解決老架構不能充分使用后段硬件能力的弊端。第二,支持SSD云盤,提供QoS保證,可以用滿后端NVME物理盤的IOPS和帶寬性能,單個云盤可達2.4W IOPS。第三,充分降低熱點問題。第四,支持超大容量盤,一個云硬盤可以支持32T,甚至可以做到無限擴容。最后就是新架構上線之后,怎么樣讓老架構遷移到新架構。

IO路徑優化
而葉恒認為要達成這樣的目標,首先需要對IO路徑進行優化。下圖是新老架構的架構圖,主要是IO路徑上的,左邊是舊架構,VM、Qamu,云硬盤是掛在虛機里面的,通過虛機來到Qamu的驅動,然后轉化到Client,Client之后會將IO轉到后端的存儲集群上,分兩層,第一層是proxy,IO的接入層,然后再分到chunk,就是讀寫一塊磁盤,后端的chunk是一個副本的形式。
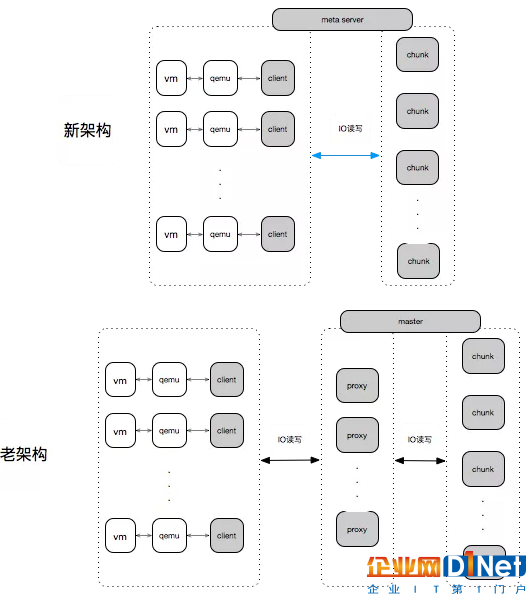
而在新架構中將IO的接入層去掉,直接將路由的功能做到client,直接連接到后端的存儲節點。這樣的話,在寫的時候,從client直接到chunk,因為三副本內容是完全一致的,讀只要讀主chunk就可以了。因此,讀路徑上就減少了一次網絡轉發,相比于老架構的話,由于軟件的升級,隨機測下來,寫延時也有所降低。
![]()
元數據優化
在老架構中,分片大小是1G,新架構中,支持了1M大小的分片。1G的分片最多只能發揮一塊物理磁盤的性能,對于普通硬盤,它后端的存儲介質是機械盤,性能有瓶頸。1M的分片會帶來很多好處,首先解決了熱點的問題,還可以充分發揮后端集群性能,因為1M的分片,如果客戶的寫在1G的范圍內,端能用到1024的分片,整個集群的性能就會全部發揮出來。
在數據組織方式方面,在老架構中,按索引的方式來組織元數據,申請一塊云盤時,所有元數據分配成功,并持久化到元數據模塊,掛載云盤時,將所有元數據load到內存中,后續IO訪問直接從內存獲取路由。這樣看起來似乎沒有什么問題,但在并發創建和掛載的情況下,如果有幾千個盤同時掛載,如果按1G的分片,300G的云盤,300條的元數據,按1M的分片,300G是30萬條,它同時創建100塊300G的云盤,需要分配3千萬條元數據,掛載也是一樣的,同時要從元數據模塊加載3千萬條數據,這對元數據模塊的設計難度是極大的,它會成為一個瓶頸。
因此在設計過程中,考慮過多種方案,方案一仍然保持帶索引的存儲方式,但在創建的時候不分配,把元數據延時分配,只有當云硬盤上某個分片上有讀寫的時候,才向元數據請求,這樣的IO延時分配,好像是能解決問題。但如果這個時候用戶開機了,幾千臺一起開機創建好了,想做個測試,或者開始用了,同時對這100塊300G的云盤做一個隨機的寫,隨機的寫會落到每個分片上去,這樣看,元數據模塊仍然是個瓶頸。
第二種方案,選用了一個一次性哈希,一個節點下線了,但是沒有機會去遷移或者分配到同一個故障率里面去,這時通過后端的chunk服務,按三個三個一組,組成一個所謂的PG,PG就是備份組,將這個備份組作為物理節點,因此,物理節點就不是一個存儲節點了,而是一組備份級。當這個組作為物理節點插到這個環上之后,會作為虛節點放大,放大三、四千倍,保證這個環大概在幾十萬左右,不能超過百萬,因為構建這個環需要時間,如果這個環太大,重啟時間就會過長。而且這三個chunk也不是隨便寫三個chunk,按照容災的策略,這三個chunk組成一個PG,分別在三個機架中,如果機架斷電,最多影響一個。
把這三個chunk組成一個PG作為物理節點插入到這個環上,然后一個節點放大成幾千個虛節點,用戶創建一塊盤,上面每個分片派來IO之后,用這個盤唯一的ID,加上這個分片,去做哈希,哈希之后落到中間,找到了PG之后,它里面包含了三條chunk的路由,將這個IO轉發到后端的主節點,由主節點去同步,主節點直接返回就可以了。
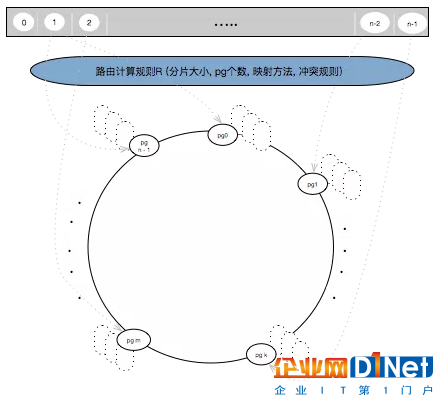
通過這個方案,以前動輒幾千萬的數據量,就是PG的個數,后端是chunk的一個路由,然后就是構建這個環的幾個參數,一個是映射的算法,一個是虛節點的放大倍數,以及沖突解決參數。這樣當云構建起來之后,向元數據模塊請求這幾個參數,最多是幾千條,之后再構建這個環,這個環構建好了之后,有IO過來的時候,只需查這個環。而當查第一次的時候,系統會把計算好的路由記住,最后就可以直接找過去,非常快。這樣的話就完全解決了上述問題,同時創造幾千個盤是完全沒有問題,同時讀寫也沒有問題,這時因為讀寫過程中不需要去分配,因為全是計算出來的。
![]()
線程模型設計
具體到軟件設計就是線程模型設計,我們知道HDD與NVME性能差別有幾百倍。原來的軟件設計用一個線程就可以,一個CPU用滿的話,一個核跑幾萬沒有問題。但現在的軟件沒辦法去發揮這種硬件的能力,所以需要改變線程的模型。
在新的架構中,在云端,采用了多線程的方式,每掛載一塊云盤的時候,會分配一個線程專門用于IO轉化,后端是線程池,main eventloop就是IO線程,當某一個分片查這個環,發現要跟后端的某個chunk通信,第一個連接分配到IO路徑1,循環派發,整個IO線程負責的連接就是均勻的。假如一個IO線程跑滿能跑5萬IOPS的話,現在跑130NVME,用它來管理線程30萬的NVME的話,六個這樣的線程就可以了,完全可以發揮硬件的性能。
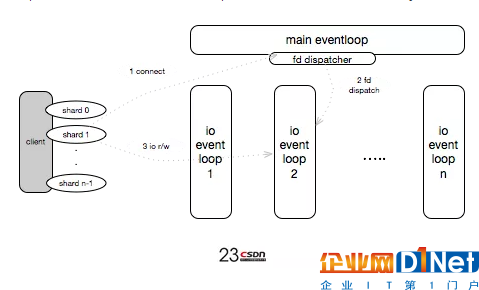
防過載策略
任何一個存儲系統,都有一個過載保護的功能,比如說掛載了幾千塊盤或者幾百塊盤,用戶同時測試,落在存儲的某一個硬盤上,并發有幾千NVME,如果不做過載保護,IO將會全部超時。在新架構中,對于普通的云硬盤,會限制物理盤上IO提交隊列的深度。
在實際代碼實現的時候,要考慮到權重,云硬盤的大小不一樣,大的云硬盤,用戶要多付費,更大的云硬盤,會獲得更多的發送機會。對于SSD云盤,傳統的單個線程會是瓶頸,難以支持幾十萬的IOPS以及1到2GB的帶寬。新架構會監控每個chunk的IO線程CPU的使用率,如果發現長時間CPU使用率都是95%或者100%,就會去通知這個chunk,斷開IO線程里面一部分連接,分配到其他線程,實現了負載均衡的效果,使得每個線程的壓力都是均勻的。
![]()
在線遷移
葉恒介紹,為了幫助用戶從老架構向新架構遷移,UCloud為用戶提供了一套在線遷移系統,在進行遷移時,首先要把下圖中上部的clond old斷掉,連上trons cilent,同時寫一份到新老架構,然后通過trocs模塊,當所有的存量數據都搬遷完成之后,這一次遷移就完成了。遷移完成之后,qemu就可以跟trons cilent斷開連接,連上一個新的cilent。這樣在遷移的過程中即使出現什么故障,重啟之后,老架構仍然可用,從而降低了遷移的風險。
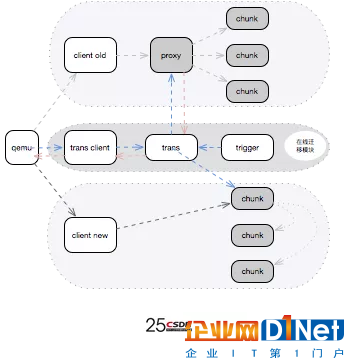
超高性能云盤
葉恒還介紹了UCloud正在研發的下一代超高性能的云盤,單個延時可以降低到100us,IOPS單盤可以突破百萬。而要達到百萬的IOPS的話,則需要用到用戶態、zero copy、polling mode,這幾個技術。用戶態就是把原來在內核態做的事情,比如網卡驅動,磁盤驅動,拿到用戶態來做,直接在用戶態操作設備。polling mode,是為了解決CPU與存儲硬件的性能差異,使用polling mode,將會大大提升性能。zero copy,是指原來數據發一個包,需要從這個態拷到那個態,但現在完全在用戶態操作硬件的話,就是零拷貝,可以直接發出去。
UCloud是全鏈路的改造,因此,client端用了VHOST,網絡端用RDMA,后端提交用SPDK。分別看一下這三個技術,在clinet端,原來數據從qume拷貝,現在數據直接VM,直接與clinet共享,這樣,只要做虛機的物理地址到后端物理地址映射,直接通過共享內存的方式就可以了。
在網絡通信部分,采用RDMA,DMA直接訪問內存,繞過CPU,從而降低CPU的使用率。RDMA直接訪問遠端的內存,這樣就實現了通信的作用。
在后端,直接是SPDK,SPDK直接從用戶態來操作固態硬盤,當掛一個盤到機器上,在內核里看不到,通過采用polling的方式,實現零拷貝,IO提交的延時非常低。
葉恒透露,在測試中,該高性能云盤,單盤IOPS突破了百萬。預計此款超高性能云盤將會在12月底推出公測版。

基于Cephfs的改進及優化
深信服科技存儲研發專家盧波最后一個登場,他就Cephfs的改進和優化進行了詳細的分析。

Ceph及CephFS的背景
盧波表示,Ceph是分層的架構,底層基于CRUSH,Ceph分布的策略是針對分級的哈希,跟一致性哈希有區別,它是區分故障域的,分了兩級,第一級是對象到PG的映射,就是根據對象進行一個哈希值,然后根據PG數舉模,最后得到這個數據對象分布在哪個PG上面。PG到Ceph底下,它的每一個存儲設備OSD,叫做對象存儲設備,PG到OSD之間,就是通過CRUSH算法來進行的路由。它的底層是基于RADOS,它是可靠,自動的分布式的一個對象存儲,具備的特性可以自修復,遷移,容錯,上層提供了對象存儲、塊存儲和文件系統訪問三種方式。CephFS支持多種協議,最早起源于2007年Sage Weil的博士論文研究,最開始Ceph針對的應用場景更多是針對高性能計算,需要高擴展性大容量的文件系統。
像Ceph這樣的分布式操作系統的出現,源于傳統單機文件系統的局限,第一是共享沒辦法在多個機器中提供應用訪問。第二就是單個文件系統容量是有限的。第三是性能,傳統的文件系統它可能沒辦法滿足應用非常高的讀寫性能要求,就只能在應用層面做拆分,同時讀寫多個文件系統。第四是可靠性,受限于單個機器的可靠性以及單個硬盤的可靠性,容易出現故障導致數據丟失。第五是可用性,受限于單個操作系統的可用性,故障或者重啟等運維操作會導致不可用。
而這些特點對于企業級的應用或者私有云來說,是無法接受的,在這種情況下,就出現了CephFS。CephFS最早是一個博士論文研究,它實現分布式的元數據管理以及可以支持EB級的數據規模,后續專門成立了一個公司來做CephFS的開發,在2014年被Redhat收購,2016年CephFS發布可用于生產環境的穩定版本發布了,目前主要應用還是單MDS。

CephFS的架構
CephFS的架構不只是CephFS,包括Ceph也在里面,第一個部分是客戶端,第二部分就是元數據。文件系統最核心的是數據,所有文件的訪問,首先離不開源數據的訪問,與塊存儲不一樣,塊存儲就是直接指定哪個硬盤的哪個位置,有了地址,就可以去讀取那個固定的數據。但Ceph的文件系統是有目錄結構和層級結構,要管理這樣的目錄結構,需要通過元數據來實現。
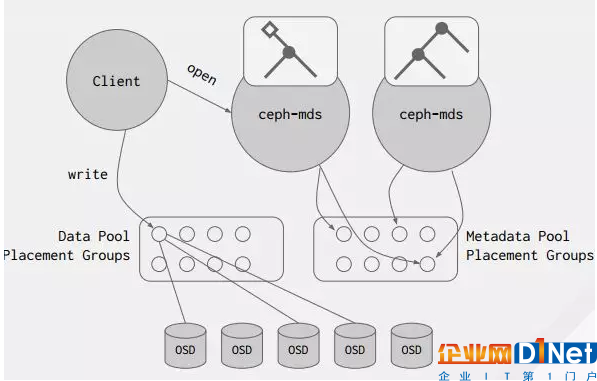
Ceph MDS也是元數據架構,可以理解為它是一個元數據的緩存,是一個元數據服務,本身并不存儲數據,它最終的數據是存在底下的RADOS的集群下面,MDS本身是不存儲數據的。當客戶端要寫一個文件,首先要打開這個文件,這個時候客戶端會跟MDS通信,去獲取它的距離,客戶端拿到之后,通過一個哈希,找到它位于哪個PG里面,直接通過計算的方式,不再需要去跟MDS交付,確定了哪個PG之后,再把數據發到對應的數據值上面去,并且它的元數據和數據是分開的,可以存在不同的存儲池中,這種設計也是分布式文件系統設計的跟傳統文件系統不一樣的地方。

MDS的作用
MDS作為元數據的緩存,同時控制元數據的并發處理,主要的作用有下面幾個:第一,要提供文件資源,要對客戶端以文件的方式,同時兼容POSIX的語義。第二,要提供一個文件系統命名空間,它要通過MDS能夠構建出分布式文件系統的一個目錄樹,一個層級結構。第三,要管理文件的元數據,比如inode、dentry這樣的文件元數據。第四,它需要持久化文件元數據,把元數據存儲到一個可靠的存儲設備上面去,在異常的情況下,保證這個數據是持久化的,可讀的,不會丟失數據。
MDS具有并發控制的流程,多個客戶端可以同時跟MDS通信,MDS通過一個鎖來處理這個請求,同時客戶端跟元數據交互的時候,除了獲取元數據信息之外,它還要知道客戶端是不是一個有效的客戶端,這個客戶端是不是能進行讀或者寫操作,以保證數據的一致性。
當MDS收到這樣的請求之后,會通過lock machine的模塊,去判斷這個請求是不是可以正向操作,以及去覆蓋剛才訪問的權限,最后會把這個請求返回給客戶端,然后會返回文件的元數據信息。
MDS是CephFS的一部分,另外CephFS還有三個點,MDS是實現元數據的分離,管理元數據,作為元數據的緩存,另外MDS是一個集群,可以有多個MDS,它是利用動態指數分區的技術,每一個MDS管理一部分的目錄,一個MDS可能負責一部分目錄層級,另外一個MDS負責另外一部分層級,這樣它可以做到很好的擴展性,它的性能也能得到提高,達到一個線性提升的目的。當然,現在還是單MDS的方式相對可靠一些,這是未來的方向。
![]()
Ceph的優化實踐
針對Ceph的問題,最直接和比較常見的想法,是縮短它的IO路徑,解決小IO的寫放大問題,第二,當前Ceph的IO路徑過長,延時高。第三,提升文件的元數據寫操作的性能。第四就是支持寫緩存的方式。第五,對讀也可以通過緩存進行加速。第六,Ceph最早出現是針對廉價的節點或者是服務器來設計的,但是現在的技術發展,有些在設計之初沒有考慮到,當然現在也在改進,這個優化也是能夠充分利用SSD或者新的網絡傳輸介質這樣的優點來提高它的性能。
在業界,在這方面優化的思路有幾種,OceanStor9000的緩存,是一個典型的分布式文件系統,它通過全局的緩存,來實現任意節點上的文件,它會對文件進行分條,任意節點收到數據訪問請求之后,都會從這個緩存里面去看,是不是這個緩存命中了,如果命中的話,這個時候直接返回客戶端。寫的話,首先直接也是寫到這個緩存里面,通過緩存的全局化,以后后臺緩存數據的全局化,去實現性能加速。緩存的一個目的除了縮短IO路徑,還有一個好處,是可以把小的IO合并,形成一個大的IO這樣一起寫下去。
Fusion storage的處理思路是一樣的,也是用到了EC,如果是大IO直接寫EC,大IO直接用硬盤的存儲能力。但是小IO,就會通過EC Cache,寫到Cache里面,這次IO結束了,就直接返回到客戶端。但后臺要保證這個Cache的數據最終持久化到HDD上面去,同時會進行IO的聚合。
Isilon是另外一個,這是NAS最早的一個產品,它里面緩存的分層分三層,第一是內存,第二層用到NVRAM的介質。第三層才是SSD。
Intel的思路是一樣的,因為它的IO路徑比較長,Intel提出了Hyper Converged Cache的思路,把這個開源了,這個思路是說,在客戶端就是由SSD來進行讀寫加速,它把后端的Ceph作為一個慢存儲來使用,在塊和RGW場景中,作為讀緩存沒有問題,如果要作為寫緩存,就涉及到冗余的問題,所以在它的設計里面,做寫緩存的時候,是用到了DRBD這樣的雙拷貝,寫到緩存里面的時候,會做一個多副本。
通過加了這樣的緩存之后,可以看到Datrium公司基于這樣的架構,做了一個緩存的實踐,給出了一個性能,可以看到對于IOPS提升是非常可觀的。這里有一個問題,多了一個緩存對于Ceph來講是很難受的,為什么?因為通過DRBD的方式,可靠性還是比較差的,對Ceph擴展性是打了折扣的。另外一個,這個緩存要實現數據的持久化,不可能是主備的方式,因為這樣也是會降低可靠性的,所以要實現這樣的緩存,是要實現分布式的一個管理邏輯。
![]()
盧波介紹說,針對這些問題,整體的思路跟前面幾種產品是一樣的,通過增加的塊存儲,來縮短IO路徑,進而提高小IO的性能。但是這個緩存底下是一個分布式的使用場景,所以這個緩存本身也是一個分布式的緩存,下面是此架構的架構圖。
![]()
這個架構與Ceph相比,只是在中間多了一個OCS的緩存服務,緩存是一個獨立的服務,從客戶端請求,也叫做CA,是NFS過來的請求,都會轉化到緩存服務上面來,在緩存服務里面,根據數據分布策略,就知道這一次操作到底要寫在哪一個緩存節點上面去,選到這個緩存節點之后,緩存節點實現多副本的數據分發,等多處副本完成之后,再返回給客戶端,這次操作完成,這是一個正常的寫入流程。
寫入之后,這個數據后臺是會定期根據水準高低,把緩存的數據直接放到底層的Read存儲上面去。一方面利用了緩存加速的性能,另外一方面,可以利用Read的全局化性以及它的擴展性。
讀流程也是一樣的,因為緩存對于小IO可以最大限度發揮空間的優勢,但是對于大IO,不需要經過緩存,直接寫到底層的Read上去。另外通過索引的方式,也可以知道具體寫到哪個緩存節點上去,大體流程就是這樣。而經過這樣改進之后,該系統的IOPS確實得到了提升。
![]()
Ceph未來展望
最后,盧波認為,CephFS最有殺傷力的一個東西,就是多MDS,即動態指數分區這樣一個技術,這方面在社區也會有一些深度的開發和討論,也在進行一些測試。下圖就是多MDS的技術原理,多個MDS去負責不同的目錄樹的元數據訪問,當客戶端來請求的時候,會去到不同的MDS,在這個MDS里面,它去實現元數據的管理以及數據間的訪問。這是多MDS性能的對比,明顯可以看到,當8個MDS并發測試的時候,其性能基本上是可以達到線性增長的。








 京公網安備 11010502049343號
京公網安備 11010502049343號