










隨著計算機(jī)的日益普及,各種應(yīng)用每天產(chǎn)生的數(shù)據(jù)量呈指數(shù)級增長。如何存儲這些數(shù)據(jù),有效處理分析這些數(shù)據(jù),并從中提取有價值的信息,是當(dāng)下迫切需要解決的問題。在過去的十年里,NoSQL在軟件工程師陣營里越來越受歡迎,其中最重要的實現(xiàn)是MapReduce ,Bigtable,Cassandra,MongoDB,等產(chǎn)品。 它主要用于解決SQL的可擴(kuò)展性問題。
然而今天SQL開始回歸。幾乎所有的云計算服務(wù)提供商都在提供備受青睞的關(guān)系型數(shù)據(jù)庫管理服務(wù):例如Amazon RDS,Google Cloud SQL,Azure 的PostgreSQL數(shù)據(jù)庫(Azure今年推出)。在亞馬遜看來,其PostgreSQL和MySQL兼容的數(shù)據(jù)庫產(chǎn)品Aurora一直是AWS歷史上增長最快的服務(wù)。Hadoop和Spark之上的SQL接口繼續(xù)迅猛發(fā)展。就在上個月,Kafka推出了SQL支持。
在這篇文章中,我們將研究SQL備受青睞的原因以及這對未來的數(shù)據(jù)社區(qū)工程和分析意味著什么。
第1部分:新希望的崛起
想要了解SQL為什么回歸,讓我們先了解他最初的設(shè)計初衷。
故事始于20世紀(jì)70年代初的IBM研究院,其中關(guān)系型數(shù)據(jù)庫誕生了。那時候,查詢語言依賴于復(fù)雜的數(shù)學(xué)邏輯和符號。Donald Chamberlin和Raymond Boyce兩位博士對關(guān)系型數(shù)據(jù)模型造詣頗深,看到查詢語言將成為其主要瓶頸。他們開始設(shè)計一種新的查詢語言(以他們自己的話來說):“ 用戶使用更容易,不需要再參加數(shù)學(xué)或計算機(jī)程序設(shè)計方面的正規(guī)培訓(xùn) ”。
回想在互聯(lián)網(wǎng)之前,在PC出現(xiàn)以前,當(dāng)程序設(shè)計語言C首次被引入世界時,兩名年輕的計算機(jī)科學(xué)家意識到,“計算機(jī)行業(yè)的成功很大程度上依賴于培養(yǎng)一種除了訓(xùn)練有素的計算機(jī)專家以外的用戶。“他們渴望一種與英文一樣容易閱讀的查詢語言,包括數(shù)據(jù)庫管理和操作。
結(jié)果是SQL在1974年首次被引入世界,成了關(guān)系型數(shù)據(jù)庫的最主要語言。在接下來的幾十年里,SQL被證明也是很受歡迎的。作為關(guān)系型數(shù)據(jù)庫,如System R,Ingres,DB2,Oracle,SQL Server,PostgreSQL,MySQL(等等)在軟件行業(yè)里的發(fā)展壯大,SQL也成為了與數(shù)據(jù)庫進(jìn)行交互的首選語言,成為了一個日益擁擠、競爭激烈的生態(tài)系統(tǒng)的通用語言。。
(不幸的是,Raymond Boyce從來沒有機(jī)會見證SQL的成功,他只做了一個早期的SQL演講,1個月后他便死于腦動脈瘤,當(dāng)時他只有26歲,留下了一個妻子和一個年輕的女兒。)
有一段時間,似乎SQL已經(jīng)成功地履行了它的使命。接著互聯(lián)網(wǎng)出現(xiàn)了。
第2部分:NoSQL反擊
雖然Chamberlin和Boyce正在開發(fā)SQL,但他們沒有意識到的是,加利福尼亞州的 另一批工程師正在開展另一個新興項目,該項目逐漸成熟后,明顯威脅到SQL的存在。該項目就是 ARPANET,誕生于1969年10月29日。
但是此前SQL發(fā)展一直很好,直到1989年,另一位工程師的出現(xiàn)并發(fā)明了萬維網(wǎng)。
互聯(lián)網(wǎng)和Web的蓬勃發(fā)展正在改變著我們的世界,但是對于數(shù)據(jù)社區(qū)來說,也是很讓人頭痛的:數(shù)據(jù)以大的量級和更快的速度爆炸式增長。
隨著互聯(lián)網(wǎng)的不斷發(fā)展和壯大,軟件社區(qū)發(fā)現(xiàn)當(dāng)時的關(guān)系數(shù)據(jù)庫無法應(yīng)對新的負(fù)載壓力,就好像一百萬個數(shù)據(jù)庫突然過載讓人抓狂一般。
然后兩家新的互聯(lián)網(wǎng)巨頭取得突破,并開發(fā)了自己的非關(guān)系型分布式系統(tǒng)來應(yīng)對這種新的數(shù)據(jù)沖擊:Google的MapReduce(2004年發(fā)布)和Bigtable(2006年發(fā)布)以及亞馬遜的Dynamo(2007年發(fā)布)。這些開創(chuàng)性論文導(dǎo)致出現(xiàn)了更多的非關(guān)系型數(shù)據(jù)庫,包括Hadoop(基于MapReduce論文,2006),Cassandra(Bigtable和Dynamo的深度解析,2008 )和MongoDB(2009))。因為這些都是從零開始大量編寫的新系統(tǒng),避開了SQL,導(dǎo)致了NoSQL運動的興起。
開發(fā)者社區(qū)的軟件工程師們逐漸地也接受了NoSQL,相較于SQL當(dāng)時的出現(xiàn),被越來越多的工程師所接受。這個原因非常容易理解:NoSQL是現(xiàn)在流行的;它承諾了規(guī)模和權(quán)力;這似乎是項目通往成功的捷徑。但后來問題出現(xiàn)了。
開發(fā)人員很快發(fā)現(xiàn),不用SQL的局限性。每個NoSQL數(shù)據(jù)庫都提供了自己獨特的查詢語言,這意味著:要學(xué)習(xí)更多的語言(并向同事教授); 將這些數(shù)據(jù)庫連接到應(yīng)用程序的難度增加,導(dǎo)致大量膠水代碼的出現(xiàn)(代碼之間有很強(qiáng)的耦合性);缺乏第三方生態(tài)系統(tǒng),要求企業(yè)必須開發(fā)自己的操作和可視化工具。
這些NoSQL語言是新的,也沒有完全開發(fā)。例如,關(guān)系型數(shù)據(jù)庫已經(jīng)運行很多年了,為SQL添加必要的功能(例如JOIN)也早都已經(jīng)完成了,NoSQL語言的不成熟意味著在應(yīng)用程序級別就會有更多的復(fù)雜性。缺乏JOIN也導(dǎo)致了非規(guī)范化,導(dǎo)致數(shù)據(jù)膨脹和僵化。
一些NoSQL數(shù)據(jù)庫添加了自己的“類SQL”的查詢語言,如Cassandra的CQL。但這往往使問題更糟。使用幾乎相同的界面,卻讓內(nèi)心更糾結(jié):工程師不知道什么是支持的,什么不是。
社區(qū)中的一些人在早期就看到了NoSQL的問題(例如,DeWitt和Stonebraker在2008年就看到了)。經(jīng)過時間的實戰(zhàn)檢驗,以及使用過程中的經(jīng)驗積累,越來越多的軟件開發(fā)人員也看到了這一點。
第3部分:回歸SQL
經(jīng)歷了黎明前的黑暗,軟件社區(qū)看到了曙光,那就是回歸SQL。
首先是Hadoop(之后的Spark)之上的SQL接口,引導(dǎo)業(yè)界興起了NoSQL ,NoSQL“不僅僅是SQL”。
然后,NewSQL的興起:新的可擴(kuò)展性數(shù)據(jù)庫,完全支持SQL。來自于麻省理工學(xué)院(MIT)和布朗大學(xué)(Brown)研究人員的H-Store (2008年發(fā)布)是第一個可擴(kuò)展OLTP數(shù)據(jù)庫之一。Google在發(fā)布的第一份Spanner論文(2012年發(fā)布)(其作者包括最初的MapReduce作者)中揭示這是基于 SQL 的查詢語言,可以將一份數(shù)據(jù)復(fù)制到全球范圍的多個數(shù)據(jù)中心,并保證數(shù)據(jù)的一致性,從而開創(chuàng)了可地理復(fù)制的SQL界面的數(shù)據(jù)庫,接著是CockroachDB(2014)這樣的先驅(qū)者。
與此同時,PostgreSQL社區(qū)開始復(fù)蘇,增加了JSON數(shù)據(jù)類型(2012),以及PostgreSQL 10 的新特性:對分區(qū)和復(fù)制更好的本地支持,JSON的全文搜索支持等(今年晚些時候發(fā)布)。其他像CitusDB(2016)和其他的公司(今年發(fā)布的TimescaleDB)發(fā)現(xiàn)了新的方法從而針對特定數(shù)據(jù)工作負(fù)載的擴(kuò)展PostgreSQL。
事實上,我們開發(fā)TimescaleDB的過程與業(yè)界的發(fā)展軌跡密切相關(guān)。早期的TimescaleDB內(nèi)部版本使用了我們自己的類sql查詢語言“ioQL”。是的,我們正是被困難驅(qū)動著:構(gòu)建我們自己的查詢語言才能更強(qiáng)大。但是,雖然看似簡單,但我們很快意識到,我們必須做更多的工作:例如,決定語法,構(gòu)建各種連接器,培訓(xùn)用戶等。我們還發(fā)現(xiàn)自己需要不斷地去查找合適的語法,去查詢那些已經(jīng)可以用SQL進(jìn)行查詢的內(nèi)容。
有一天,我們意識到建立自己的查詢語言是沒有意義的。關(guān)鍵還是要擁抱SQL。這是我們做出的最好的決策之一。同時也開啟了一個全新的世界。今天,即使我們的數(shù)據(jù)庫才問世5個月,但我們的用戶完全可以使用我們的產(chǎn)品,并獲得各種各樣支持:可視化工具(Tableau),通用ORM連接器,各種工具和備份選項,大量的在線教程和語法說明等。
---但是不要把我們的話放在心上,看看谷歌
Google已經(jīng)十多年來一直處于數(shù)據(jù)工程和基礎(chǔ)設(shè)施的領(lǐng)先地位。我們應(yīng)該密切關(guān)注他們正在做什么。
看看谷歌的第二大Spanner論文,僅在四個月前發(fā)布(Spanner:成為一個SQL系統(tǒng),2017年5月),你會發(fā)現(xiàn)它支持我們的發(fā)現(xiàn)成果。
例如,Google開始在Bigtable之上開發(fā),但是后來發(fā)現(xiàn)缺少SQL產(chǎn)生了一系列問題(在下面的所有引號中有強(qiáng)調(diào)):
“雖然這些系統(tǒng)提供了數(shù)據(jù)庫系統(tǒng)的一些優(yōu)勢,但它們?nèi)狈?yīng)用程序開發(fā)人員常常依賴的許多傳統(tǒng)數(shù)據(jù)庫功能。一個關(guān)鍵的例子是強(qiáng)大的查詢語言,這意味著開發(fā)人員必須編寫復(fù)雜的代碼來處理和聚合應(yīng)用程序中的數(shù)據(jù)。因此,我們決定將Spanner變成一個功能齊全的SQL系統(tǒng),其查詢執(zhí)行與Spanner的其他架構(gòu)功能(如強(qiáng)一致性和全局復(fù)制)緊密集成。
在本文的后面,他們進(jìn)一步了解從NoSQL轉(zhuǎn)換到SQL的理由:Spanner的原始API提供了為單個和交叉表的點查找和范圍掃描的NoSQL方法。雖然NoSQL方法提供了啟動Spanner的簡單路徑,并且在簡單的檢索方案中繼續(xù)有用, 但SQL在表達(dá)更復(fù)雜的數(shù)據(jù)訪問模式并將計算推送到數(shù)據(jù)方面提供了重要的附加價值。
本文還介紹了如何在Spanner上使用SQL并不會停止,哪怕某一個數(shù)據(jù)中心停止運轉(zhuǎn),仍然可用。但實際上擴(kuò)展到Google的其余部分,其中多個系統(tǒng)共享一個通用的SQL語言:
Spanner的SQL引擎與Google的其他幾個系統(tǒng)共享一個稱為“標(biāo)準(zhǔn)SQL”的常見SQL語言,包括內(nèi)部系統(tǒng),如F1和Dremel(以及其他)以及外部系統(tǒng),如BigQuery 。
對于Google用戶,這會降低跨系統(tǒng)的工作障礙。對Spanner數(shù)據(jù)庫編寫SQL的開發(fā)人員或數(shù)據(jù)分析師可以將他們對語言的理解轉(zhuǎn)移到Dremel,而不用擔(dān)心語法,NULL處理等方面的微妙差異。
這就是這種方法的成功奧秘。當(dāng)“潛在云客戶對SQL有濃厚興趣”時,Spanner已經(jīng)成為Google主要系統(tǒng)的根基(包括AdWords和Google Play) 。
考慮到Google最先啟動了NoSQL的運動,這是非常顯著的,它今天正在回歸SQL。(引起一些人反思:“ Google 10年前挺進(jìn)大數(shù)據(jù)市場就是個大忽悠嗎”?)
這對數(shù)據(jù)的未來意味著什么:SQL將變成窄腰
在計算機(jī)網(wǎng)絡(luò)中,有一個叫做“窄腰”的概念。
這個概念的出現(xiàn)解決了一個關(guān)鍵問題:在任何給定的網(wǎng)絡(luò)設(shè)備上,想象一個堆棧,底層硬件層和頂層軟件層。中間可能會存在各種網(wǎng)絡(luò)硬件;類似地,也存在各種軟件和應(yīng)用程序。需要一種方法來確保無論硬件如何,軟件仍然可以連接到網(wǎng)絡(luò); 無論軟件如何,網(wǎng)絡(luò)硬件都知道如何處理網(wǎng)絡(luò)請求。
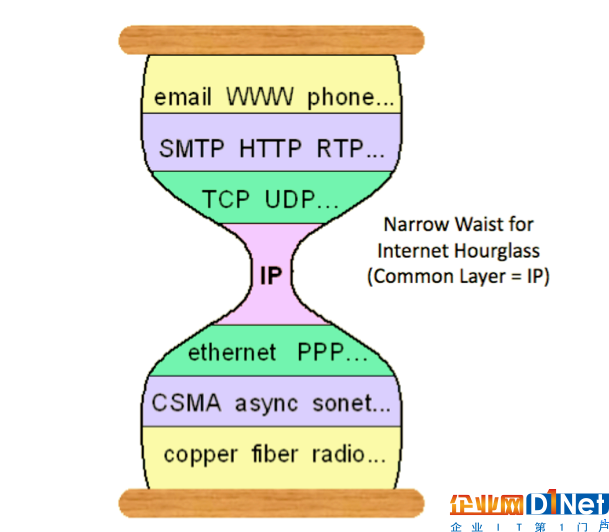
在網(wǎng)絡(luò)中,窄腰的角色由互聯(lián)網(wǎng)協(xié)議(IP)扮演,它是為局域網(wǎng)設(shè)計的底層聯(lián)網(wǎng)協(xié)議和更高級別的應(yīng)用程序和傳輸協(xié)議的公共接口。(這是一個很好的解釋。)而且(在一個廣泛的過度簡化)中,這個公共接口成為了計算機(jī)的通用語言,使網(wǎng)絡(luò)互連,設(shè)備進(jìn)行通信,而這個“網(wǎng)絡(luò)網(wǎng)絡(luò)”可以發(fā)展成為今天豐富多樣的互聯(lián)網(wǎng)。
我們認(rèn)為,這等同于SQL已成為數(shù)據(jù)分析的“窄腰。
我們生活在一個數(shù)據(jù)正在成為“世界上最寶貴資源”的時代(”
“經(jīng)濟(jì)學(xué)人”,2017年5月)。我們看到了Cambrian 的專業(yè)數(shù)據(jù)庫(OLAP,時間序列,文檔,圖表等),數(shù)據(jù)處理工具(Hadoop,Spark,F(xiàn)link),數(shù)據(jù)總線(Kafka,RabbitMQ)等的紅海。還有更多的應(yīng)用程序需要依賴這種數(shù)據(jù)基礎(chǔ)設(shè)施,無論是第三方數(shù)據(jù)可視化工具(Tableau,Grafana,PowerBI,Superset),Web框架(Rails,Django)還是定制的數(shù)據(jù)驅(qū)動應(yīng)用程序。
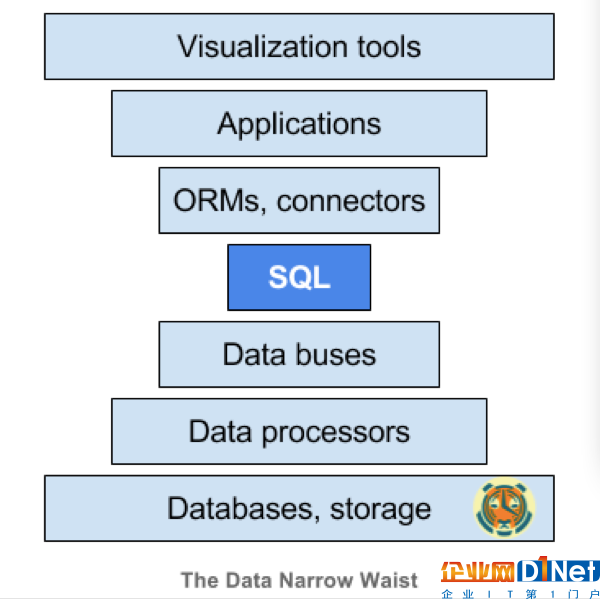
像網(wǎng)絡(luò)一樣,我們有一個復(fù)雜的堆棧,底層的基礎(chǔ)設(shè)施和頂部的應(yīng)用程序。通常,我們最終編寫了大量的膠水代碼,使此堆棧工作。但是膠水代碼可能很脆弱:需要維護(hù)和貼合。
我們需要的是一個公共接口,允許這個堆棧的各個部分相互通信。這個行業(yè)已經(jīng)標(biāo)準(zhǔn)化了。它能讓不同層級之間的通信阻礙降到最小。
這就是SQL的力量。和IP一樣,SQL也是一個公共接口。
但事實上,SQL 比 IP 復(fù)雜的多。因為數(shù)據(jù)還需要被人類分析。而且SQL創(chuàng)建者最初給它設(shè)定的目標(biāo)就是可讀性要高。
SQL完美嗎?不,但這是社區(qū)中的大多數(shù)人都已經(jīng)了解了這語言。雖然已經(jīng)有工程師在開發(fā)更和諧的語言界面,但這些系統(tǒng)最終會連接到哪里?還是SQL。
所以在堆棧的頂部還有一層。那一層就是我們。
SQL回歸
SQL已經(jīng)回來了。不僅僅是因為使用NoSQL工具編寫膠水代碼是惱人的。不僅僅是因為培訓(xùn)大家學(xué)習(xí)無數(shù)新的語言成本是巨大的,不只是因為統(tǒng)一標(biāo)準(zhǔn)的重要性。
而且也因為世界充滿了數(shù)據(jù)。它圍繞著我們,束縛著我們。首先,我們依靠我們的人類感官和感覺神經(jīng)系統(tǒng)來處理它。現(xiàn)在我們的軟件和硬件系統(tǒng)也越來越智能,可以幫助我們。隨著我們收集的數(shù)據(jù)越來越多,可以更好的讓我們了解這個世界,系統(tǒng)的復(fù)雜性,存儲,處理,分析和可視化的需求只會繼續(xù)增長。
我們生活在一個脆弱的世界和一百萬個不同界面的世界。或許我們可以繼續(xù)擁抱SQL。一切都遵循能量守恒定律。
感謝徐川對本文的審校。

















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號