









Google在Tensorflow的Github代碼庫中,發布了多個用在移動電話上的高效預訓練計算機視覺模型。
這幾個模型間的差別在于模型的參數、單圖像處理的計算能力以及預測的準確性,開發人員可從中做出選取。從計算量上看,最小的模型具有14個百萬次MAC(乘加運算,Multiply-Accumulates ),最大的模型則具有569個百萬次MAC。要預測一個圖像的類別,一個模型所需的計算量越大,所需使用移動設備的電量也越多。開發人員可以根據特定的應用,在準確性和所耗費電池電量間進行權衡。模型的性能及資源占用情況發布在Google博客上,如下圖所示。
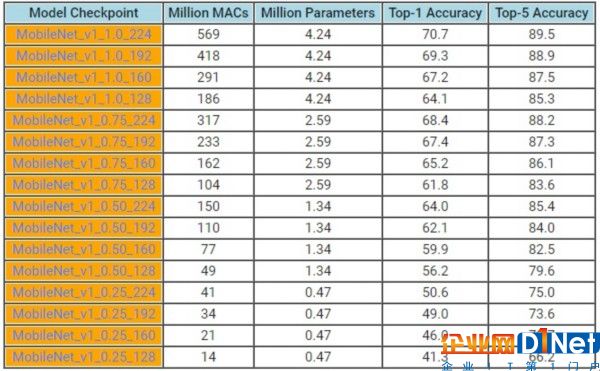
在智能電話上處理圖像的性能,要優于將圖像上傳到在線處理服務(例如,Cloud API)。這也意味著數據完全不必離開智能手機,確保了了用戶的隱私。這些模型是開源的,開發人員可直接下載,或是微調模型以適合自身的特定需求。
盡管這些發布的模型使用了更少的計算量,但是大多數模型所做出預測的準確性還是可與其它神經網絡的表現相媲美的。在今年早先預發表的一篇研究論文中,闡述了MobileNets更為高效的原因。
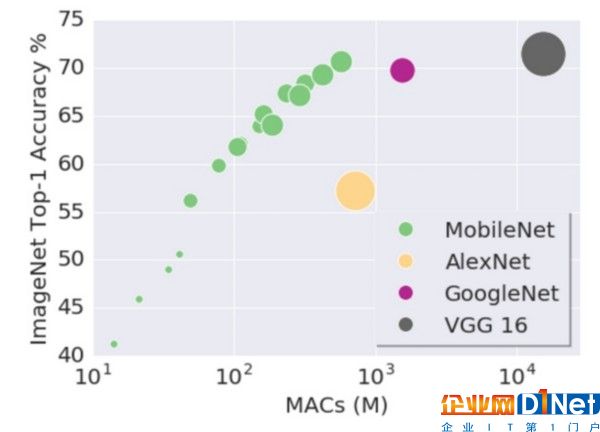
論文在LSVRC數據集上驗證了模型的準確性。LSVRC數據集是一個大規模的圖像識別數據集。MobileNet對每個圖像給出五個標簽預測結果,并使用“Top-1 Accuracy”和“Top-5 Accuracy”指標衡量了預測結果的準確性。“Top-1 Accuracy”表示預測結果中可能性最大的一個標簽的確是圖像真實標簽的比例,“Top-5 Accuracy”表示預測結果中可能性最大的五個標簽中包含了圖像真實標簽的比例。
有意著手去運用這些模型的開發人員,可以訪問Tensorflow Mobile的主頁。Tensorflow-Slim圖像分類庫的更多信息,提供于Github上。
查看英文原文: Google Released MobileNets: Efficient Pre-Trained Tensorflow Computer Vision Models
















 京公網安備 11010502049343號
京公網安備 11010502049343號