










雷鋒網AI科技評論按:信息爆炸時代,如何在浩瀚如海的網絡中找到自己的需求?谷歌研究團隊推出了 Coarse Discourse 數據集,可以將一段文字中“廢話”剔除,精準識別用戶所需要的目標信息。作為一名雷鋒網(公眾號:雷鋒網)編輯,信息搜集和分類是日常工作中極為耗時的一件事。谷歌推出的新方法能否解決這一問題?
每一天,社區中的活躍者都在發送和分享他們的意見,經驗,建議以及來社交,其中大部分是自由表達,沒有太多的約束。這些網上討論的往往是許多重要的主題下的關鍵信息資源,如養育,健身,旅游等等。不過,這些討論中往往還夾雜著亂七八糟的分歧,幽默,爭論和鋪墊,要求讀者在尋找他們要的信息之前先過濾內容。信息檢索領域正在積極探索可以讓用戶能夠更有效地找到,瀏覽內容的方式,在論壇討論缺乏共享的數據集可以幫助更好地理解這些討論。
在這個空間中為了幫助研究人員,谷歌發布了 Coarse Discourse dataset,是最大的有注釋的數據集。 Coarse Discourse dataset包含超過10萬條人可在線討論的公開注解,這些是從reddit.com網站中的130個社區,超過9000個主題中隨機抽取的。
為了創建這個數據集,我們通過一小部分的論壇線程開發了論壇注解的話語分類系統。通俗的說就是閱讀每一個評論,并判斷評論在討論中扮演什么角色。我們用眾包的人工編輯再重復和修正這種練習來驗證話語類型分類的重現性,包括:公告,問題,答案,協議,分歧,闡述和幽默。從這個數據,超過10萬條的評論由眾包編輯單獨注釋其話語類型和關系。連同眾包編輯的原注釋,我們還提供標注任務指南,供編輯們使用幫助他們從其他論壇收集數據和對任務進一步細化。
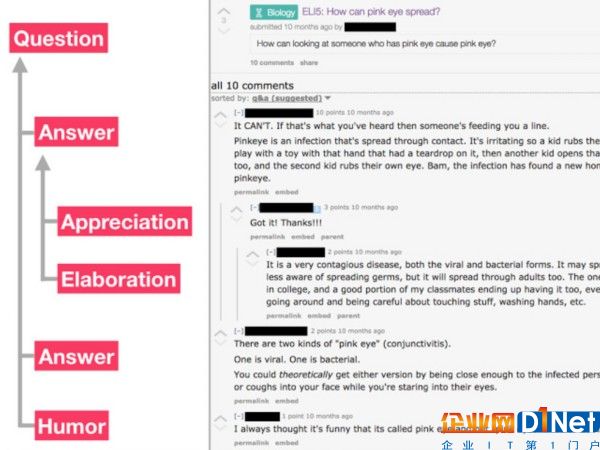
圖中為用話語類型和關系來注釋的示例線程。早期的研究結果表明,問和答模式在大多數社區是一個突出的運用,有的社區會話更集中,來回的相互作用。
論文摘要
在這項工作中,我們提出了一種新的方法將在線討論中的評論分類成一些粗糙語料,是為了在一定規模上更好理解討論這個目標的實現。為了促進這項研究,我們設計了一個粗糙語料的分類,旨在圍繞一般在線討論,并允許工作人員簡單注釋。使用我們的語料庫,我們演示了如何分析話語行為,可以描述不同類型的討論,包括話語序列,如問答配對,分歧鏈,以及不同的社區中的表現。
最后,我們進行實驗,使用我們的語料庫預測話語行為,發現結構化預測模型,如在條件隨機場合下可以實現F1得分75%。我們還演示了如何擴大話語行為,從單一的問和答到更豐富的類別。可以提高Q&A抽取的召回性能。
實驗結論
使用了一種新的話語行為的分類,我們推出一個從Reddit上數千個社區采樣,最大的人工標注的數據集的討論,在每個線程上的每個評論根據話語行為和關系注釋。從我們的數據集,我們觀察到常見的話語序列模式,包括問答和參數,并使用這些信號來表征社區。最后,我們用結構化CRF模型進行了分類的話語行為實驗,實現了75% F1得分。此外,我們演示了如何使用我們的9個話語行為在只標簽了問題和答案的模型,整體提高Q&A抽取的召回性能。
對于機器學習和自然語言處理的研究人員試圖描述在線討論的性質,我們希望這個數據集是一個有用的資源。可以訪問我們的GitHub庫下載數據。更多細節,請查看論文 ICWSM,“Characterizing Online Discussion Using Coarse Discourse Sequences.”
via Google;雷鋒網整理編譯

















 京公網安備 11010502049343號
京公網安備 11010502049343號