











據外媒報道,谷歌(微博)CEO桑達爾-皮查伊(Sundar Pichai)剛剛在2017年谷歌I/O大會上宣稱,該公司的語音識別技術現在的差錯率已降低到了4.9%。
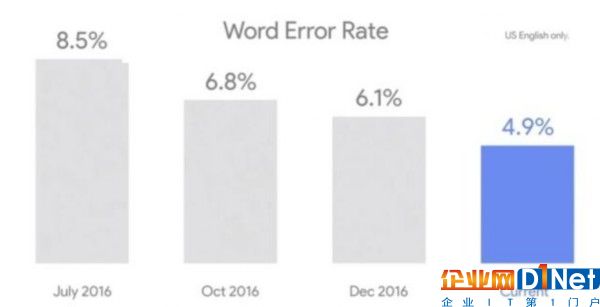
相對于以往來說,這是一個非常大的進步。在2013年,它的差錯率為23%;在2015年的I/O大會上,谷歌宣稱其語音識別技術的差錯率為8%。
谷歌利用深度學習技術來實現準確的圖像識別和語音識別。這種方法包括用大量數據來訓練名為“神經網絡”的系統,然后給該系統提供新的數據,讓它進行預測。
“我們在很多產品中都采用了語音輸入方式。”皮查伊說,“這是因為電腦越來越善于識別語音了。從去年以來,我們在這方面取得的進步非常驚人。我們在嘈雜環境中的語音識別技術正在不斷完善。因此,當你用手機或智能家居設備Google Home對谷歌講話時,我們就能夠正確地識別你的聲音。”
相對而言,微軟在2016年10月宣稱,它已取得了可與人類媲美的語音識別水平。它的差錯率當時為6.3%。但是,我們并不清楚這兩家公司是否采用了相同的衡量標準。
事實上,谷歌吹噓其語音識別技術的進步已有一段時間。今年初,該公司就宣稱,它的語音識別差錯率從2012年以來已減少了30%。這種技術進步的主要原因是什么呢?谷歌證實這是因為它使用神經網絡技術的緣故。
皮查伊還分享了開發Google Home的逸聞趣事,“當我們開發Google Home的時候,我們原計劃使用8個麥克風。但是,由于采用了基于神經波束賦形技術的神經網絡系統,我們最后只需要用兩個麥克風就達到了相同的效果。”

















 京公網安備 11010502049343號
京公網安備 11010502049343號