









來自LinkedIn性能工程團隊的的工程師Toon Sripatanaskul和Zhengyu Cai在官方網站上披露了他們是如何通過Inception處理內部系統的日志,從而實現服務監控的。
早在2012年初,LinkedIn的性能工程團隊就嘗試構建一種工具,它可以對發生代碼變更后的服務進行有效性驗證。日志消息,特別是異常日志,可以很準確地反應服務的運行狀況。對于新部署的服務,通過檢查是否有新的異常日志出現就可以知道服務的健康狀況。那個時候,他們使用腳本把日志文件拷貝到其它機器上,然后通過正則表達式生成最終的日志報告。這種方式在剛開始的時候運作良好,但LinkedIn發展迅速,腳本工具不具備伸縮性,無法跟上公司的發展速度。
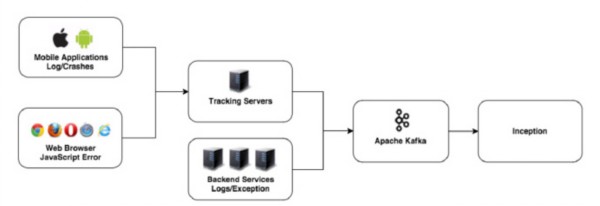
2012年底,他們構建了一個日志消息處理系統,叫作Inception(Linked In Ex ception的合體)。他們把各個數據中心產生的日志消息聚集到Kafka上,然后Inception通過Kafka客戶端處理這些消息,并把它們存放到如下幾個數據庫表中:
唯一性異常(What):異常日志消息的堆棧信息被抽取出來,并通過散列生成MD5串,這個串就是這個消息的簽名。這樣,他們就可以通過比較這個散列值快速地識別出新的異常,同時可以對異常進行去重。在計算散列值時,消息里的動態數據會被過濾掉,比如時間戳和代碼行數。這個表保存的是日志消息和它的散列值。 實例(Where):這個表保存的是發生異常的服務實例,包括主機名、服務名和代碼版本號。 時間序列(When):他們以分鐘時間為單位,并檢查在一分鐘內某種異常發生的次數。這個表同時還引用了上述兩個表的數據。把以上三個表的數據連接起來,他們就有足夠的信息來生成日志報表,包括唯一性日志消息以及它們的發生次數和發生地點。
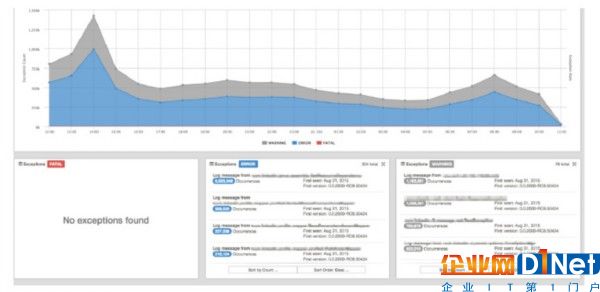
幾年來,為了適應LinkedIn迅速的發展,Inception的架構也在不斷演進。在經歷了幾次伸縮性問題之后,他們決定使用在Inception里使用Apache Samza來處理日志。Samza不僅處理速度快,而且高度可伸縮。Inception現在每秒可以處理110萬條日志消息。除此以外,Inception還支持多種數據源。
說到這里,不得不提一下,在日志分析技術領域,ELK(Elasticsearch、Logstash、Kibana)是另外一個值得一說的日志分析技術棧。ELK可以保存完整的日志信息,包括時間戳、實際發生次數和具體的堆棧信息。不過ELK會占用大量的存儲空間。對于LinkedIn來說,為了得到一個粗略的報表,可能因此需要耗費50T的存儲空間,而Inception只需要30G的空間,并且處理速度更快。這么說來,Inception似乎在這方面更勝一籌。
















 京公網安備 11010502049343號
京公網安備 11010502049343號