


今天的數據基礎設施,無論是在本地還是在云中,通常都基于通用的體系結構,這些體系結構利用預先配置的計算和存儲資源分配來滿足各種應用程序的工作負載需求。隨著這些數據密集型應用程序在更大范圍內的擴展,一刀切的基礎設施在性能、容量和可伸縮性方面出現不足,難以滿足不同的應用程序需求。因此,需要一種更新、更靈活的資源分配方法來提高業務效率。
分解計算和存儲資源的需求現在是IT優先考慮的問題,這樣組織就可以節省資金并提高硬件資源的利用率。要通過優化應用程序部署來實現這些收益,關鍵的任務是使計算資源和存儲資源能夠彼此獨立地伸縮。通過抽象、配置和改進的flash SSD管理,需要在存儲節點本身上運行的專門軟件,以充分利用組成存儲資源池的高性能和網絡化非易失性內存Express (NVME™)-SSD。共享存儲資源還可以使用RESTful應用程序編程接口(API)連接到自動化容器編排框架。
存儲軟件現在可以使用網絡協議將存儲從計算節點分離出來,而fabric上的NVME (NVME- oF™)已迅速成為首選協議。它具有流線型、高性能和低延遲,使其成為構建更現代、更敏捷和更靈活的數據中心的有價值的組件。
行業的挑戰
現有數據中心通常將直接連接存儲(DAS)用于云部署,因為DAS成本低且簡單,是目前部署的最流行的存儲體系結構。將存儲作為DAS模型的一部分嵌入到服務器中還可以提高總體性能和數據訪問。然而,DAS的權衡是,CPU和存儲資源在環境中緊密地鎖在一起,限制了通常會導致存儲過量供應的容量和資源利用率,并增加了存儲開銷和總擁有成本(TCO)。
開發云基礎設施的數據中心架構師必須采取額外的設計步驟來克服DAS的許多限制,比如處理服務器中未充分利用的SSD和CPU,這些CPU需要更高的存儲性能或容量。為適應云基礎設施中的峰值工作負載而過度配置整個數據中心是昂貴的,并且限制了執行彈性伸縮的能力,或者在部署時,會導致資源利用率不足(峰值工作負載除外)。
云中的存儲分解
由于廣泛采用了兩項關鍵技術:
(1). 10/25/100千兆以太網(GbE)網絡連接和任何高性能網絡協議,解決IT資源分解的挑戰變得更容易了;
(2). 支持基于閃存的SSD在網絡上通信的NVME-oF規范,提供了幾乎相同的高性能、低延遲優勢,就像基于NVME的SSD是本地附加的,或者在某些工作負載下,提供了更好的性能。
NVME- oF旨在解決與DAS體系結構相關的低效問題,方法是將高性能NVME SSD資源從計算節點分離出來,并使它們作為網絡附加的共享資源跨網絡基礎設施可用。池提供了為數據中心內的每個服務器上的每個應用程序工作負載提供適當數量的存儲或計算的能力。當與自動化編制框架(如Kubernetes®和OpenStack®)集成時,在工作負載高峰期間,池從較低優先級的應用程序中借用計算資源。雖然這種方法類似于iSCSI等其他塊存儲技術,但是使用NVME-oF池閃存可以以更低的延遲訪問資源,供不同的主機共享。
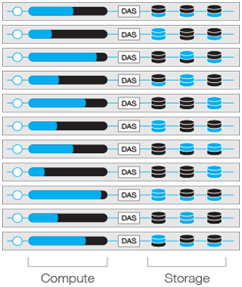
圖1展示了一個DAS體系結構,它使用更多的節點來獲得高計算能力和存儲容量,但是容易受到資源擱淺的影響
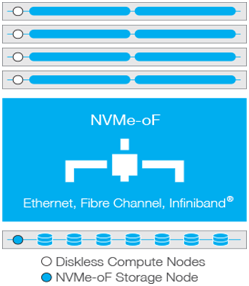
圖2表示了一個分解的體系結構,它在類似于das的性能下共享快速NVME存儲,節點更少,更容易管理,也更劃算
解集的好處
從基于DAS的存儲架構遷移到分解的,基于云的共享存儲模型(圖2)具有多種優勢,可顯著提高CPU和SSD利用率,從而無需過度構建或過度配置資源以滿足峰值應用程序工作負載需求。這種存儲資源與計算服務器的分離提供了廣泛的財務,運營和性能優勢,可以在遷移到云基礎架構時保持良好狀態。改進包括:
產能利用率
將存儲資源與服務器分離的能力允許為每個計算節點和每個工作負載應用正確的容量級別,從而減少了在每個服務器中過多提供存儲的需要。
服務器利用率
隨著時間的推移,不同的應用程序對計算的需求不同,昂貴的CPU資源可能會被擱淺。Disaggregation為使用更少的計算節點處理I/ o密集型應用程序分配低延遲flash提供了靈活性。分解和NVME-oF的組合通過提高CPU的總體利用率、在不過度配置的情況下最大化存儲容量,以及在需要時實現額外的計算節點來解決擱淺的資源問題。
延遲性能
通過NVME-oF進行分解,使延遲與直接連接的驅動器幾乎沒有區別,并將物理驅動器抽象到一個高性能池中,使flash能夠在工作負載實例之間共享。
網絡級機會
Disaggregation還允許創建更強大的web規模的云,在這些云中,可以在數據中心中使用大量的云計算資源,并根據跨特定無狀態、有狀態和批處理應用程序的需要或服務交付策略使用和轉移這些資源。
空間、動力和冷卻要求
通過分解,資源利用率將會飆升,從而減少對更多空間、電力或冷卻需求的需求,從而減少存儲開銷和TCO。
實時VM遷移,無需移動數據
在軟件定義的數據中心中,由于各種原因(負載平衡、維護等),虛擬機(VM)經常需要從一個物理服務器轉移到另一個物理服務器。在分解的體系結構中,當虛擬機遷移到其他位置時,數據可以保留在其受保護的位置。僅僅移動虛擬機就簡化了這個過程,并且降低了對數據的風險。
組織正在采用云架構,以幫助最大限度地提高數據中心內計算和存儲資源的靈活性、可伸縮性和利用率。基于DAS體系結構的傳統軟件定義存儲(SDS)云模型在共享方面不如分解方法有效,導致計算和存儲容量利用率較低,并降低了總體經濟性能。
當將NVME- oF協議添加到混合協議中時,通過將高性能NVME SSD從計算節點分離出來并使它們可以在網絡上共享,可以更好地處理與DAS體系結構相關的限制和低效。
最終的想法
下一代以性能為中心、對延遲敏感的應用程序現在已經成為當今云基礎設施規劃和運營的一部分,這要求IT組織重新考慮他們的數據中心存儲策略。這些策略正逐漸轉向共享基礎設施和云編排,以便為每個應用程序工作負載分配適當的存儲和性能。因此,云中的分解存儲正在成為首選的、成本高效的模型。這場運動的核心是對基于NVME的閃存和使基于云的分解成為現實的NVME框架的更高需求。
關于作者:Joel Dedrick是東芝的KumoScale™共享加速存儲軟件的副總裁兼總經理。作為一名執行技術專家,Dedrick先生擁有超過20年的經驗,將有前景的技術轉變為公共,私營和初創公司的領先產品。他的專業領域包括存儲,網絡,半導體和專用計算架構。 Dedrick擁有內布拉斯加大學電子工程學士學位,以及南方衛理公會大學電子工程碩士學位,主修數字信號處理(DSP)。








 京公網安備 11010502049343號
京公網安備 11010502049343號