


4月14日,騰訊云正式發布新一代HCC(High-Performance Computing Cluster)高性能計算集群。該集群采用騰訊云星星海自研服務器,搭載英偉達最新代次H800 GPU,服務器之間采用業界最高的3.2T超高互聯帶寬,為大模型訓練、自動駕駛、科學計算等提供高性能、高帶寬和低延遲的集群算力。
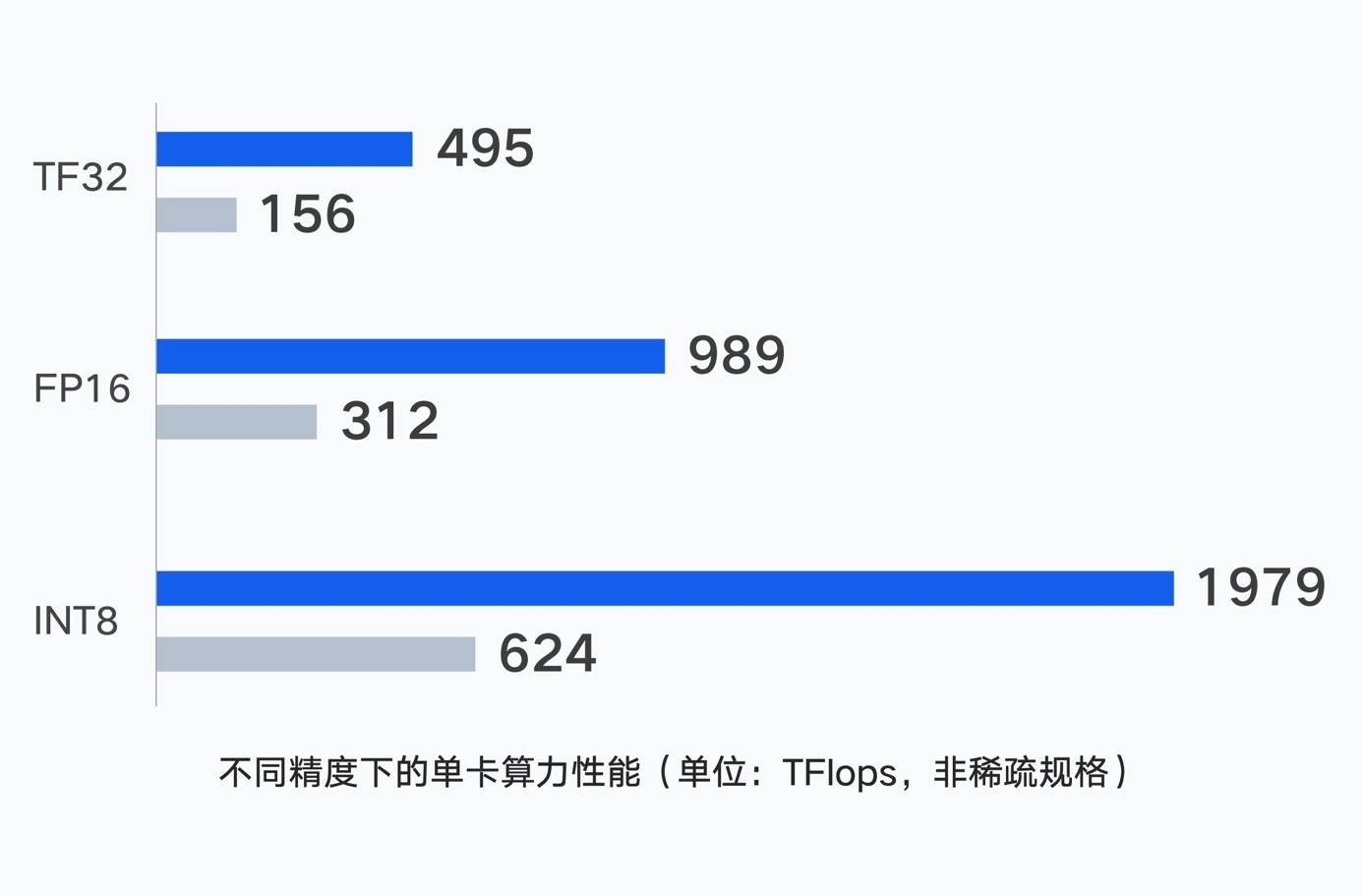
實測顯示,騰訊云新一代集群的算力性能較前代提升高達3倍,是國內性能最強的大模型計算集群。
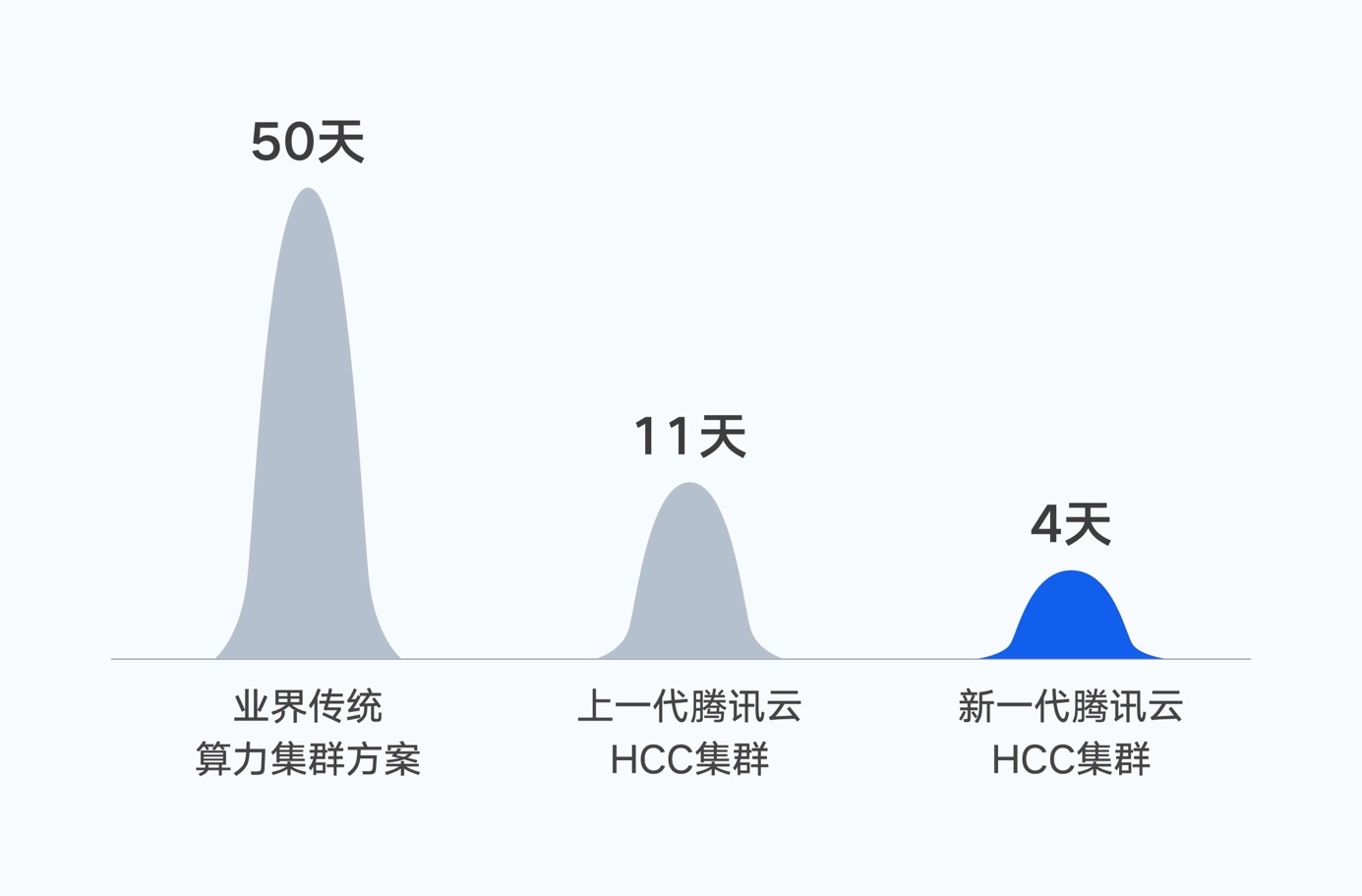
2022年10月,騰訊完成首個萬億參數的AI大模型——混元NLP大模型訓練。在同等數據集下,將訓練時間由50天縮短到11天。如果基于新一代集群,訓練時間將進一步縮短至4天。
大模型進入萬億參數時代,單體服務器算力有限,需要將大量服務器通過高性能網絡相連,打造大規模算力集群。通過對處理器、網絡架構和存儲性能的全面優化,騰訊云攻克了大集群場景下的算力損耗問題,能為大模型訓練提供高性能、高帶寬、低延遲的智算能力支撐。
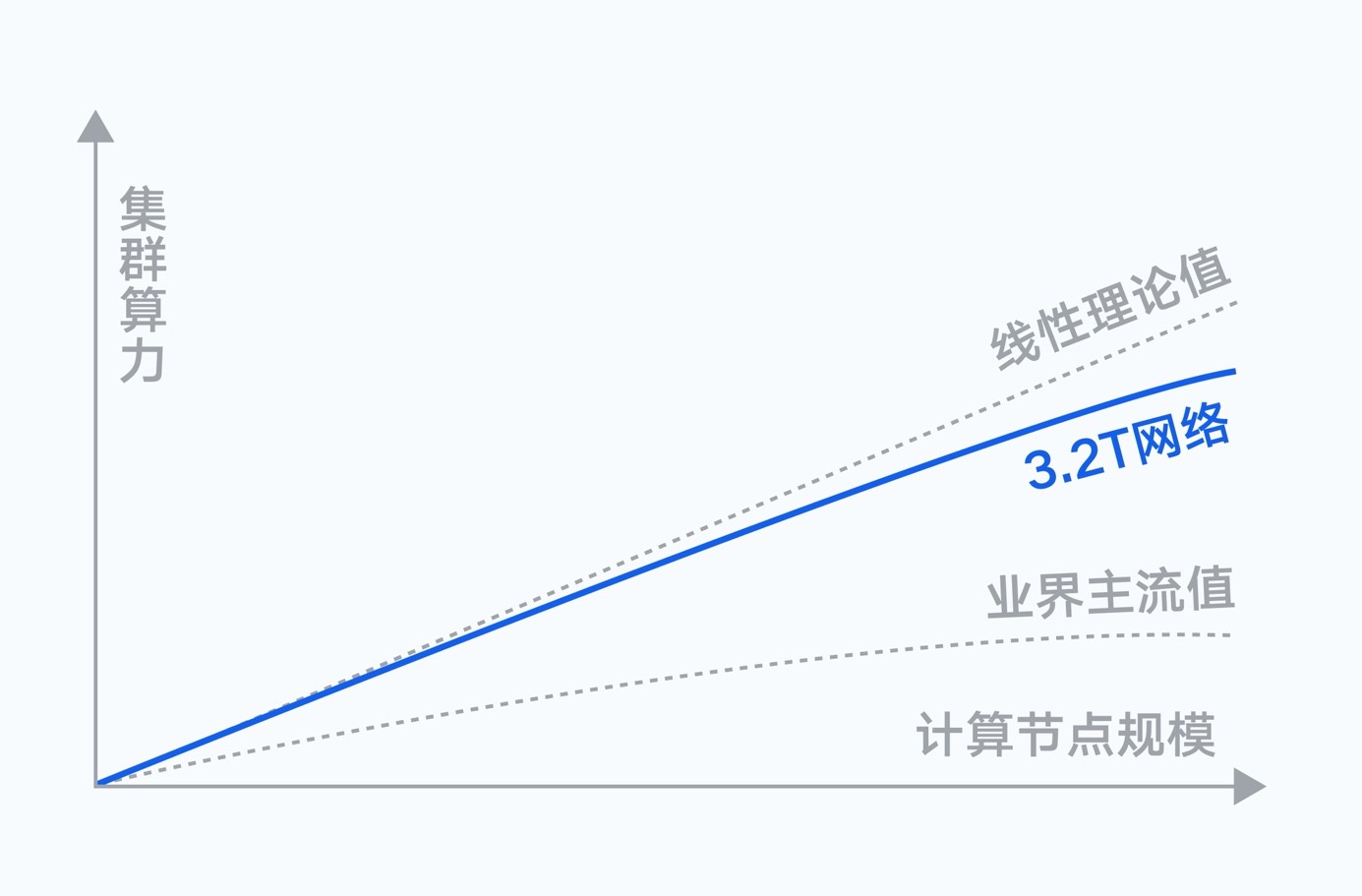
網絡層面,計算節點間存在海量的數據交互需求,隨著集群規模擴大,通信性能會直接影響訓練效率。騰訊自研的星脈網絡,為新一代集群帶來了業界最高的3.2T的超高通信帶寬。實測結果顯示,搭載同樣的GPU卡,3.2T星脈網絡相較前代網絡,能讓集群整體算力提升20%,使得超大算力集群仍然能保持優秀的通信開銷比和吞吐性能。并提供單集群高達十萬卡級別的組網規模,支持更大規模的大模型訓練及推理。
存儲層面,幾千臺計算節點同時讀取一批數據集,需要盡可能縮短加載時長。騰訊云自研的文件存儲、對象存儲架構,具備TB級吞吐能力和千萬級IOPS,充分滿足大模型訓練的大數據量存儲要求。

底層架構之上,針對大模型訓練場景,新一代集群集成了騰訊云自研的TACO Train訓練加速引擎,對網絡協議、通信策略、AI框架、模型編譯進行大量系統級優化,大幅節約訓練調優和算力成本。
騰訊混元大模型背后的訓練框架AngelPTM,也已通過騰訊云對外提供服務,幫助企業加速大模型落地。
目前,騰訊混元AI大模型,已經覆蓋了自然語言處理、計算機視覺、多模態等基礎模型和眾多行業、領域模型。
在騰訊云上,企業基于TI 平臺的大模型能力和工具箱,可結合產業場景數據進行精調訓練,提升生產效率,快速創建和部署 AI 應用。
此前,騰訊多款自研芯片已經量產。其中,用于AI推理的紫霄芯片、用于視頻轉碼的滄海芯片已在騰訊內部交付使用,性能指標和綜合性價比顯著優于業界。其中,紫霄采用自研存算架構,增加片上內存容量并使用更先進的內存技術,消除訪存能力不足制約芯片性能的問題,同時內置集成騰訊自研加速模塊,減少與CPU握手等待時間。目前,紫霄已經在騰訊頭部業務規模部署,提供高達3倍的計算加速性能,和超過45%的整體成本節省。
目前,騰訊云的分布式云原生調度總規模超過1.5億核,并提供16 EFLOPS(每秒1600億億次浮點運算)的智算算力。未來,新一代集群不僅能服務于大模型訓練,還將在自動駕駛、科學計算、自然語言處理等場景中充分應用。
以新一代集群為標志,基于自研芯片、星星海自研服務器和分布式云操作系統遨馳,騰訊云正通過軟硬一體的方式,打造面向AIGC的高性能智算網絡,持續加速全社會云上創新。








 京公網安備 11010502049343號
京公網安備 11010502049343號