


芯片制造商正在研究可顯著增加每瓦和每時(shí)鐘周期可處理數(shù)據(jù)量的新型架構(gòu),從而開啟了數(shù)十年來(lái)芯片架構(gòu)轉(zhuǎn)變的大幕。
所有主要的芯片制造商和系統(tǒng)供應(yīng)商都在改變方向,引發(fā)了一場(chǎng)架構(gòu)創(chuàng)新大賽,創(chuàng)新涉及從存儲(chǔ)器中讀取和寫入數(shù)據(jù)的方式、數(shù)據(jù)管理和處理方式以及單個(gè)芯片上的各個(gè)元素的結(jié)合方式等。雖然工藝節(jié)點(diǎn)尺寸仍在繼續(xù)縮減,但是沒有人寄希望于工藝的進(jìn)步可以跟得上傳感器數(shù)據(jù)的爆炸性增長(zhǎng)以及芯片間數(shù)據(jù)流量增加的步伐。
在這些創(chuàng)新中, 新型處理器架構(gòu)專注于研究每個(gè)時(shí)鐘周期內(nèi)處理更多數(shù)據(jù)的方法,有時(shí)犧牲部分精度,或者根據(jù)應(yīng)用類型提高特定操作的優(yōu)先級(jí);
正在開發(fā)的新存儲(chǔ)器架構(gòu)改變了數(shù)據(jù)存儲(chǔ)、讀取、寫入和訪問的方式;
更有針對(duì)性的處理元素散布在系統(tǒng)周圍,更加靠近內(nèi)存。系統(tǒng)不再依賴于最適合應(yīng)用的單個(gè)主處理器,而是根據(jù)數(shù)據(jù)類型和應(yīng)用選擇不同的加速器;
通過人工智能技術(shù),將不同的數(shù)據(jù)類型融合在一起,形成多種模式,有效地提高了數(shù)據(jù)密度,同時(shí)最大限度地減少不同數(shù)據(jù)類型之間的差異;
封裝組合形式成為架構(gòu)設(shè)計(jì)的核心之一,越來(lái)越關(guān)注修改設(shè)計(jì)的難易。
“有一些趨勢(shì)導(dǎo)致人們?cè)噲D充分挖掘已有方案的潛力。” Rambus的杰出發(fā)明家Steven Woo說(shuō),“在數(shù)據(jù)中心上,你希望硬件和軟件能夠發(fā)揮盡可能多的作用,這是數(shù)據(jù)中心重新思考其經(jīng)濟(jì)成本的方式。啟用一種新功能的成本非常高,但是瓶頸正在日益凸顯,所以我們看到更多專用芯片和提高計(jì)算效率的方法不斷涌現(xiàn),如果可以減少數(shù)據(jù)在內(nèi)存和I/O上來(lái)回傳輸?shù)拇螖?shù),將會(huì)產(chǎn)生很大的影響。”
這些變化在邊緣節(jié)點(diǎn)上更加明顯,此外,系統(tǒng)供應(yīng)商突然意識(shí)到有數(shù)百億臺(tái)設(shè)備不斷地產(chǎn)生天量數(shù)據(jù),而這些數(shù)據(jù)無(wú)法全部發(fā)送到云端進(jìn)行處理。在邊緣節(jié)點(diǎn)上處理這些數(shù)據(jù)對(duì)節(jié)點(diǎn)自身帶來(lái)了挑戰(zhàn),它們需要在不顯著改變功耗預(yù)算的情況下大幅提高性能。
英偉達(dá)的Tesla產(chǎn)品家族首席平臺(tái)架構(gòu)師Robert Ober說(shuō):“人們把重點(diǎn)放在降低精度上,邊緣節(jié)點(diǎn)性能的提升不僅僅體現(xiàn)在更多計(jì)算周期上。它需要在內(nèi)存中放入更多數(shù)據(jù),比如您可以使用16位指令格式。 所以,解決方案不是為了提高處理效率而在緩存中存儲(chǔ)更多內(nèi)容。從統(tǒng)計(jì)上看,不同精度的計(jì)算結(jié)果應(yīng)該是一致的。”
Ober預(yù)測(cè),在可預(yù)見的未來(lái),通過一系列架構(gòu)優(yōu)化應(yīng)該可以每隔幾年就將處理速度提高一倍。“我們將見證這些改變,”他說(shuō)。“為了實(shí)現(xiàn)這一目標(biāo),我們需要在三個(gè)層面實(shí)現(xiàn)突破。第一是計(jì)算,第二是內(nèi)存,在某些模型中,計(jì)算更關(guān)鍵,而在其它模型中內(nèi)存更關(guān)鍵。第三是主處理器帶寬和I/O帶寬,我們需要在優(yōu)化存儲(chǔ)和網(wǎng)絡(luò)方面做很多工作。”
其中一些變化已經(jīng)發(fā)生。在Hot Chips 2018會(huì)議上的演講中,三星奧斯汀研發(fā)部門的首席架構(gòu)師 Jeff Rupley指出了該公司M3處理器的幾個(gè)主要架構(gòu)變化。其中一個(gè)是每個(gè)周期處理更多的指令,相比于之前M2處理的四條指令/周期,M3為6條。還包括以若干神經(jīng)網(wǎng)絡(luò)取代預(yù)取搜索,改善了分支預(yù)測(cè),以及將指令隊(duì)列深度加倍。
從另一個(gè)角度來(lái)看,這些變化也改變了從制造工藝到前端架構(gòu)/設(shè)計(jì)和后端封裝的協(xié)同創(chuàng)新關(guān)系。雖然制造工藝仍在不斷創(chuàng)新,但是每次新節(jié)點(diǎn)只能帶來(lái)15%到20%的性能和功耗改善,顯然不足以跟上數(shù)據(jù)的增長(zhǎng)步伐。
“變化正以指數(shù)速度發(fā)生,”Xilinx總裁兼首席執(zhí)行官Victor Peng在Hot Chips的演講中表示。 “現(xiàn)在每年將產(chǎn)生10個(gè)zettabytes [1021字節(jié)]的數(shù)據(jù),其中大部分是非結(jié)構(gòu)化數(shù)據(jù)。”
存儲(chǔ)器領(lǐng)域的新方案
處理這么多數(shù)據(jù)需要重新思考系統(tǒng)中的每個(gè)元素,從數(shù)據(jù)的處理方式到存儲(chǔ)方式都需要重新設(shè)計(jì)。
“業(yè)界已經(jīng)進(jìn)行了多次嘗試,以創(chuàng)建新的內(nèi)存架構(gòu),”eSilicon EMEA創(chuàng)新高級(jí)主管CarlosMaciàn說(shuō)。“當(dāng)前內(nèi)存的瓶頸在于你需要讀取出一整行,然后再在其中選擇一位。一種新方法是構(gòu)建可以從左到右、從上到下讀取的內(nèi)存。您還可以更進(jìn)一步,將計(jì)算能力部署到不同的內(nèi)存中。”
還可以改變內(nèi)存的讀取方式、處理單元的位置和類型,以及使用人工智能技術(shù)優(yōu)化不同數(shù)據(jù)在整個(gè)系統(tǒng)中存儲(chǔ)、處理、傳輸?shù)膬?yōu)先級(jí)。
“在稀疏數(shù)據(jù)中,我們一次只能從字節(jié)陣列讀取一個(gè)字節(jié)的數(shù)據(jù),在其它類型應(yīng)用中,也可以在同樣的字節(jié)陣列中一次讀取八個(gè)連續(xù)數(shù)據(jù),而不會(huì)消耗與我們不感興趣的其它字節(jié)或字節(jié)陣列相關(guān)的能耗,”Cadence產(chǎn)品營(yíng)銷部門總監(jiān)Marc Greenberg說(shuō)。 “未來(lái)的新型內(nèi)存可能更適合處理這類事情。比如我們看一下HBM2的架構(gòu),HBM2硅片堆棧被安排到16個(gè)64位的虛擬通道中,我們從任何一次對(duì)任何虛擬通道的訪問中都能得到4個(gè)連續(xù)的64位字。因此,有可能構(gòu)建可水平寫入的1,024位寬的數(shù)據(jù)陣列,一次只讀取4個(gè)64位字。”
內(nèi)存是馮諾依曼架構(gòu)的核心組件之一,也正在成為架構(gòu)創(chuàng)新的最大試驗(yàn)田之一。AMD的客戶端產(chǎn)品首席架構(gòu)師Dan Bouvier表示:“現(xiàn)有架構(gòu)的一個(gè)大報(bào)應(yīng)就是虛擬內(nèi)存系統(tǒng),它迫使你以更加不自然的方式移動(dòng)數(shù)據(jù)。你需要執(zhí)行一次又一次轉(zhuǎn)換。如果您可以消除DRAM中的分區(qū)沖突,您可以獲得更高效的數(shù)據(jù)流動(dòng)。分立GPU可以在90%的效率區(qū)間運(yùn)行DRAM,效率非常高。但是,如果你可以獲得串行的數(shù)據(jù)傳輸,你也可以在APU和CPU上在80%到85%的效率區(qū)間內(nèi)運(yùn)行DRAM。”
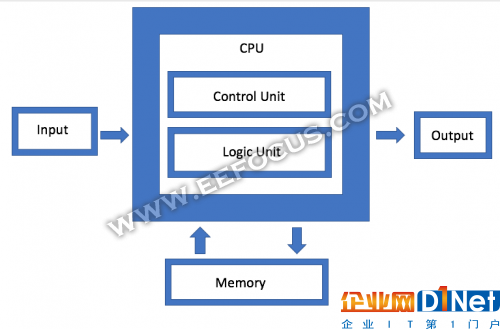
馮諾依曼架構(gòu)
IBM正在開發(fā)一種不同類型的內(nèi)存架構(gòu),它本質(zhì)上是磁盤條帶化技術(shù)的現(xiàn)代版本。磁盤條帶化技術(shù)將數(shù)據(jù)不再局限在單個(gè)磁盤上,同樣,IBM新型內(nèi)存架構(gòu)的目標(biāo)是利用被其系統(tǒng)硬件架構(gòu)師Jeff Stuecheli稱為連接技術(shù)的“瑞士軍刀”的連接器技術(shù),混合和匹配不同類型的數(shù)據(jù)。
“CPU變成了一個(gè)位于高性能信號(hào)接口中間的東西,”Stuecheli說(shuō)。“如果你修改微體系結(jié)構(gòu),不用提高頻率,內(nèi)核就可以在每個(gè)周期內(nèi)做更多的事情。”
為了確保這些體系架構(gòu)能夠處理越來(lái)越龐大的數(shù)據(jù),連接性和吞吐能力變得越來(lái)越重要。 “現(xiàn)在最大的瓶頸在于數(shù)據(jù)傳輸,”Rambus的Woo說(shuō)。 “半導(dǎo)體行業(yè)在提高計(jì)算性能方面做得非常出色。 但是,如果您把大量時(shí)間用在等待數(shù)據(jù)或特定的數(shù)據(jù)模式上,效率依然無(wú)法提高。必須更快地運(yùn)行內(nèi)存。因此,如果你看看DRAM和非易失性存儲(chǔ)器就會(huì)發(fā)現(xiàn),它們的性能實(shí)際上取決于數(shù)據(jù)傳輸模式。如果您能夠?qū)?shù)據(jù)串起來(lái),就可以在內(nèi)存中獲得非常高的效率。但是如果你的數(shù)據(jù)在空間上隨機(jī)分布,效率就會(huì)降低。無(wú)論你怎么做,隨著數(shù)據(jù)量的增加,你必須保證能夠更快地完成所有這些數(shù)據(jù)傳輸。”
更多計(jì)算,更少移動(dòng)
使問題變得更加復(fù)雜的是,邊緣設(shè)備以各種頻率和速度產(chǎn)生了多種不同類型的數(shù)據(jù)。為了使數(shù)據(jù)在各種處理單元之間流暢地移動(dòng),必須比過去更加有效地管理它。
“有四種主要配置 - 多對(duì)多、內(nèi)存子系統(tǒng)、低功耗IO以及網(wǎng)狀和環(huán)形拓?fù)洌?rdquo;Arteris IP董事長(zhǎng)兼首席執(zhí)行官Charlie Janac說(shuō)。 “你可以將所有這四個(gè)要素放在單個(gè)芯片中,現(xiàn)在的決策型IoT芯片就是這么做的。或者您可以添加具有高吞吐能力的HBM子系統(tǒng)。但是由于其中一些工作負(fù)荷是面向特定行業(yè)需求,而且每個(gè)芯片都需要面對(duì)多個(gè)工作負(fù)荷,具有多個(gè)引腳,所以問題依然很復(fù)雜。你看其中一些物聯(lián)網(wǎng)芯片,它們會(huì)收集大量的數(shù)據(jù)。些工作負(fù)載非常具體,每個(gè)芯片有多個(gè)工作負(fù)載和引腳。 如果你看一些物聯(lián)網(wǎng)芯片,它們會(huì)收集大量的數(shù)據(jù)。像汽車中的雷達(dá)和LiDAR這樣的東西尤其如此。如果沒有某種先進(jìn)的互連技術(shù),它們的存在毫無(wú)意義。”
挑戰(zhàn)在于如何盡量減少數(shù)據(jù)移動(dòng),以及在需要時(shí)最大程度提高數(shù)據(jù)傳輸速度,并以某種方式在不消耗太多功率的情況下取得本地處理和集中處理的平衡。
“一方面是帶寬問題,”NetSpeed Systems產(chǎn)品營(yíng)銷經(jīng)理Rajesh Ramanujam說(shuō)。 “如果可能的話,您希望盡量不要移動(dòng)數(shù)據(jù),因此您可以將數(shù)據(jù)放得離處理器更近。但是,如果您必須移動(dòng)數(shù)據(jù),則需要盡可能地壓縮數(shù)據(jù)。但是,現(xiàn)實(shí)情況往往更加復(fù)雜,你必須從系統(tǒng)級(jí)別查看這種可能性。每一步都需要考慮多個(gè)因素,確定您是以傳統(tǒng)的讀寫方式使用內(nèi)存還是利用新的內(nèi)存技術(shù)。在某些情況下,您可能希望更改數(shù)據(jù)本身的存儲(chǔ)方式。如果您想要更快的性能,通常意味著更大的芯片尺寸,這會(huì)影響功耗。現(xiàn)在你還要考慮功能安全,因此不得不擔(dān)心數(shù)據(jù)過載。”
這就是為什么人們把那么多的注意力放在加強(qiáng)邊緣處理能力和增加各種處理單元之間的傳輸吞吐能力上。現(xiàn)在,隨著架構(gòu)的演化和完善,處理的實(shí)現(xiàn)方式和位置都發(fā)生了很大變化。
比如,Marvell推出了一款內(nèi)置AI能力的SSD控制器,它可以在邊緣節(jié)點(diǎn)上處理更大的計(jì)算負(fù)荷。其中的AI引擎可用于固態(tài)存儲(chǔ)本身的分析。
“你可以直接將模型加載到硬件中,并在SSD控制器上進(jìn)行硬件處理,”Marvell的首席工程師Ned Varnica說(shuō)。 “今天,云端主機(jī)就是這樣做的。但是,如果每個(gè)SSD都要將數(shù)據(jù)發(fā)送到云端,那將會(huì)產(chǎn)生巨大的網(wǎng)絡(luò)流量。最好在邊緣就地處理,主機(jī)只需要發(fā)出元數(shù)據(jù)形式的命令。 這樣一來(lái),您擁有的存儲(chǔ)設(shè)備越多,處理能力就越強(qiáng)。降低網(wǎng)絡(luò)傳輸?shù)暮锰幏浅4蟆?rdquo;
這種方法有一點(diǎn)特別值得注意,即它強(qiáng)調(diào)數(shù)據(jù)根據(jù)應(yīng)用類型而移動(dòng)的靈活性。主機(jī)可以生成一個(gè)任務(wù),將它發(fā)送到存儲(chǔ)設(shè)備上進(jìn)行處理,然后只需要返回元數(shù)據(jù)或者計(jì)算結(jié)果。在另外一種場(chǎng)景中,存儲(chǔ)設(shè)備可以存儲(chǔ)數(shù)據(jù),對(duì)數(shù)據(jù)進(jìn)行預(yù)處理并從生成元數(shù)據(jù)、標(biāo)簽和索引,主機(jī)需要進(jìn)行進(jìn)一步分析時(shí)再讀回它們。
這只是其中一種方案,還有其它的選擇。三星的Rupley強(qiáng)調(diào)了亂序處理和融合習(xí)語(yǔ),它們可以解碼兩條指令并將它們?nèi)诤显趩蝹€(gè)操作中。
AI監(jiān)督和優(yōu)化
在所有這些之上是人工智能,它是芯片架構(gòu)領(lǐng)域的新技術(shù)。它不管操作系統(tǒng)和中間件如何管理功能,而是在系統(tǒng)級(jí)別上監(jiān)督芯片以及芯片之間的行為。在某些情況下,AI可以體現(xiàn)為芯片內(nèi)的神經(jīng)網(wǎng)絡(luò)。
eSilicon市場(chǎng)營(yíng)銷副總裁Mike Gianfagna表示,“AI的作用并不是將更多東西包裝在一起,多到足夠改變傳統(tǒng)的處理方式。通過AI和機(jī)器學(xué)習(xí),你可以在系統(tǒng)周圍部署人工智能,以獲得更高效和預(yù)測(cè)性的處理。它有時(shí)可以是在系統(tǒng)內(nèi)獨(dú)立運(yùn)行的單獨(dú)芯片。”
Arm正在開發(fā)首款機(jī)器學(xué)習(xí)芯片,它計(jì)劃于今年晚些時(shí)候推出,面向多個(gè)細(xì)分市場(chǎng)和垂直市場(chǎng)。“這是一種新型處理器,”Arm的杰出工程師Ian Bratt說(shuō)。 “它包括一個(gè)基本塊,其中帶有一個(gè)計(jì)算引擎、一個(gè)MAC引擎和一個(gè)帶有控制單元和廣播網(wǎng)絡(luò)的DMA引擎。該芯片共有16個(gè)計(jì)算引擎,使用7nm制造工藝,在1GHz主頻下可達(dá)到4 teraOps的計(jì)算能力。”
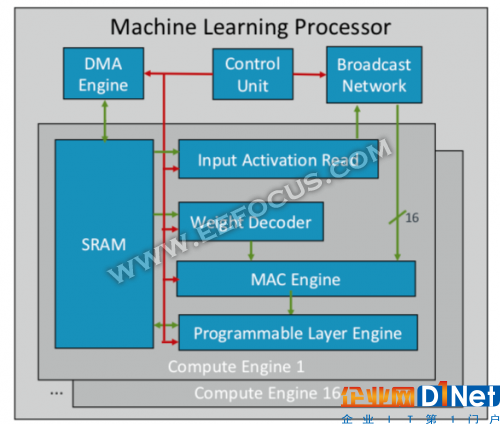
Arm機(jī)器學(xué)習(xí)處理器架構(gòu)
由于Arm生態(tài)系統(tǒng)面向多個(gè)合作伙伴,因此該芯片比其它AI/ML芯片更加通用,配置能力更強(qiáng)。它沒有搭建一個(gè)包羅萬(wàn)物的單片架構(gòu),而是根據(jù)功能劃分不同處理單元,因此每個(gè)計(jì)算引擎都是面向不同的功能特征。Bratt表示,AI芯片的四個(gè)關(guān)鍵要素是靜態(tài)調(diào)度、高效卷積、帶寬減少機(jī)制以及面向未來(lái)設(shè)計(jì)的可編程性。
英偉達(dá)則采取了不同的策略,它選擇在GPU旁邊構(gòu)建專用的深度學(xué)習(xí)引擎,以優(yōu)化圖片和視頻處理的數(shù)據(jù)傳輸。
結(jié)論
芯片制造商表示,通過實(shí)行部分或全部這些方法,他們可以每隔幾年就將性能提高一倍,以跟上數(shù)據(jù)爆炸性增長(zhǎng)的步伐,同時(shí)滿足功耗的嚴(yán)格限制。這些方法不僅是提供更多計(jì)算機(jī),還正在改變芯片設(shè)計(jì)和系統(tǒng)工程化的起點(diǎn),它們更多考慮數(shù)據(jù)的不斷增長(zhǎng),而不是硬件和軟件的限制。
Synopsys公司董事長(zhǎng)兼聯(lián)席首席執(zhí)行官Aart de Geus說(shuō):“當(dāng)最初一代計(jì)算機(jī)開始進(jìn)入公司時(shí),很多人都認(rèn)為世界的發(fā)展速度將會(huì)加快很多。沒有計(jì)算機(jī)時(shí),他們用一堆紙質(zhì)的會(huì)計(jì)賬簿進(jìn)行會(huì)計(jì)處理。自那以后,各種公司事務(wù)的處理速度發(fā)生了指數(shù)級(jí)的變化,現(xiàn)在,這種變化再一次來(lái)到了我們面前。這種快速的變化就像突然可以把會(huì)計(jì)賬簿打印出來(lái)了一樣。就像在農(nóng)業(yè)領(lǐng)域里,你只需要在某一天溫度上升的時(shí)候灌溉適當(dāng)?shù)乃湍撤N肥料,就可以等待豐收一樣,機(jī)器學(xué)習(xí)也是這種之前并不明顯的優(yōu)化。”
西門子子公司Mentor的總裁兼首席執(zhí)行官Wally Rhines也認(rèn)可這種觀點(diǎn)。“新架構(gòu)將被人們接納,人們將在新架構(gòu)下設(shè)計(jì)芯片,在許多甚至大多數(shù)場(chǎng)景下執(zhí)行機(jī)器學(xué)習(xí),就像您的大腦有能力從經(jīng)驗(yàn)中學(xué)習(xí)一樣。我拜訪了20多家正在做自己的專用AI處理器的公司,它們都有自己的特色。你會(huì)越來(lái)越多地在各種特定應(yīng)用中看到它們,它們對(duì)傳統(tǒng)的馮諾伊曼架構(gòu)形成了有效補(bǔ)充。神經(jīng)形態(tài)計(jì)算將成為處理,它將幫助我們提高計(jì)算效率、降低成本,在移動(dòng)和聯(lián)接性的環(huán)境中完成工作,現(xiàn)在我們還必須在大型服務(wù)器集群中完成這些工作。”






正在發(fā)生重大變化?")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)