





并且人工智能芯片的應用場景細分市場越來越多,專門為某些人工智能應用場景定制的芯片適用性明顯高于通用芯片。這樣的形勢,給一些人工智能芯片的初創公司帶來了機會。寒武紀芯片和地平線的人工智能視覺芯片、自動駕駛芯片等,就是初創公司在人工智能芯片領域取得成功的代表。
人工智能芯片大火的同時,已經呈現出三分天下的態勢。FPGA、GPU和TPU芯片,已經在人工智能領域大規模應用。這三種人工智能芯片有何不同?人工智能企業又是怎樣看待這三種芯片的?下文將為您詳述。
FPGA并不是新鮮的事物,而因為AI的火熱的應用需求不斷增強,FPGA正是作為一種AI芯片呈現在人們的面前。準確的說,不僅僅是芯片,因為它能夠通過軟件的方式定義,所以,更像是AI芯片領域的變形金剛。
FPGA是現場可編程邏輯陣列的首字母縮寫,即Field-Programmable Gate Array。過去曾與可編程邏輯器件CPLD進行過較量,如今已經在PAL、GAL、CPLD等可程式邏輯裝置的基礎上進一步發展,成為英特爾進軍AI市場的一個重要法寶。
FPGA三大特點
劉斌表示:“實際上今天絕大多數人工智能系統是部署在通用處理器上的,原因是在很多應用領域中人工智能部分只是完成某個環節的系統任務,還有大量其它任務一起構成系統處理的完整單元。”在此基礎上,出現了很多種選項,比如FPGA、TPU2或者NNP等專用處理器。這種專用處理器,往往向深度學習和神經網絡領域延伸,擁有更高效的存儲器訪問調度結構。
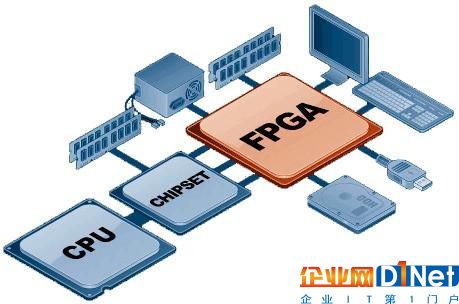
具體而言有三大特點:FPGA器件家族的廣泛覆蓋可以適配從云到端的應用需求;FPGA具有處理時延小并且時延可控的特點,更適合某些實時性要求高的業務場景;FPGA可以靈活處理不同的數據位寬,使得系統可以在計算精度、計算力、成本和功耗上進行折衷和優化,更適合某些制約因素非常嚴格的工程化應用。相比于ASIC則FPGA更加靈活,可以適配的市場領域更加廣泛。
自定義功能芯片
以微軟為例,在微軟必應搜索業務和Azure云計算服務中,均應用了英特爾FPGA技術,在其發布的“腦波項目”(Project Brainwave)中特別闡述了英特爾FPGA技術如何幫助Azure云和必應搜索取得“實時人工智能”(real-time AI)的效果。
英特爾 FPGA 支持必應快速處理網頁中的數百萬篇文章,從而為您提供基于上下文的答案。借助機器學習和閱讀理解,必應 現在可提供智能答案,幫助用戶更快速找到所需答案,而非手動點擊各個鏈接結果。在微軟腦波計劃中,同樣選擇了英特爾現場可編程門陣列的計算晶片,以具有競爭力的成本和業界最低延遲進行人工智能計算。
如果說在AI芯片領域各家有各家的拿手絕學,那么身為“變形金剛”FPGA的拿手絕學就是自定義功能了。作為特殊應用積體電路領域中的一種半定制電路的FPGA,既解決了全定制電路的不足,又克服了原有可編程邏輯器件門電路數有限的缺點。也就是說,盡管FPGA不是輻射范圍最廣的,但是一旦匹配后,輸出驚人,所以也是良好的芯片選擇。
不止FPGA
隨著人工智能的發展,芯片的設計不僅要能夠滿足人工智能對計算力的需求,還要能夠適應不斷變化的產業需要。在不同的應用領域和不同的位置,前端還是數據中心,甚至邊緣計算等應用場景。劉斌表示:一種芯片是沒辦法解決所有問題的。從移動設備,到服務器,再到云服務、機器學習和人工智能的加速,需要不同種類的技術支持,需要能夠支持從毫瓦級到千瓦級的多種架構。
在英特爾人工智能領域,除了FPGA之外,還提供了ASIC方案下的NNP神經網絡計算加速器、Movidius專注前端智能攝像頭領域和Mobieye加速芯片,在無人車領域做視覺相關的物體、道路、異常情況的監測。
過去30多年,摩爾定律幾乎每年都會推動微處理器的性能提升50%,而半導體的物理學限制卻讓其放慢了腳步。如今,CPU的性能每年只能提升10%左右。事實上,英偉達CEO黃仁勛在每年的GTC上都會提到同一件事——摩爾定律失靈了。也就是說,人們要獲得更強的計算力,需要花費更多的成本。與此同時,GPU的崛起速度令人咂舌,看看英偉達近兩年的股價就知道了。
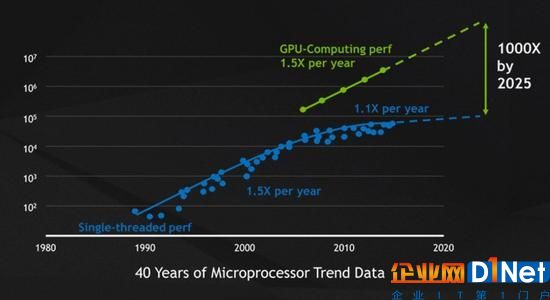
2006年,借助CUDA(Compute Unified Device Architecture,通用計算架構)和Tesla GPU平臺,英偉達將通用型計算帶入了GPU并行處理時代,這也為其在HPC領域的應用奠定了基礎。作為并行處理器,GPU擅長處理大量相似的數據,可以將任務分解為數百或數千塊同時處理,而傳統CPU則是為串行任務所設計,在X86架構下進行多核編程是很困難的,并且從單核到四核、再到16核有時會導致邊際性能增益。同時,內存帶寬也會成為進一步提高性能的瓶頸。
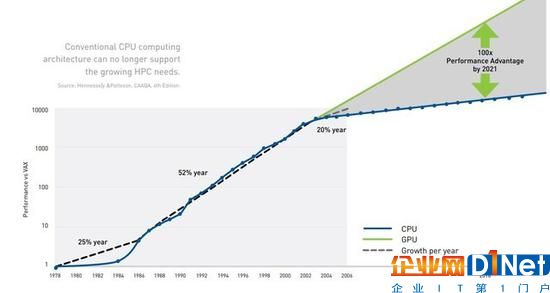
更重要的是,英偉達在利用GPU構建訓練環境時還考慮到了生態的重要性,這也是一直以來困擾人工智能發展的難題。首先,英偉達的NVIDIA GPU Cloud上線了AWS、阿里云等云平臺,觸及到了更多云平臺上的開發者,預集成的高性能AI容器包括TensorFlow、PyTorch、MXNet等主流DL框架,降低了開發門檻、確保了多平臺的兼容性。
其次,英偉達也與研究機構、大學院校,以及向Facebook、YouTube這樣的科技巨頭合作,部署GPU服務器的數據中心。同時,還為全球數千家創業公司推出了Inception項目,除了提供技術和營銷的支持,還會幫助這些公司在進入不同國家或地區的市場時,尋找潛在的投資機會。
可以說,英偉達之于GPU領域的成功除了歸功于Tesla加速器、NVIDIA DGX、NVIDIA HGX-2這些專屬的工作站或云服務器平臺,更依托于構建了完整的產業鏈通路,讓新技術和產品有的放矢,從而形成了自己的生態圈,這也是英特爾難以去打破的。
在不久前舉行的谷歌I/O 2018開發者大會上,TPU3.0正式亮相。根據官方介紹,TPU3.0的計算能力最高可達100PFlops,是TPU2.0的8倍多。TPU的英文全名是Tensor Processor Unit,它是谷歌自主研發的針對深度學習加速的專用人工智能芯片。TPU是專為谷歌深度學習框架TensorFlow設計的人工智能芯片。著名的AlphaGo使用的就是TPU2.0芯片。

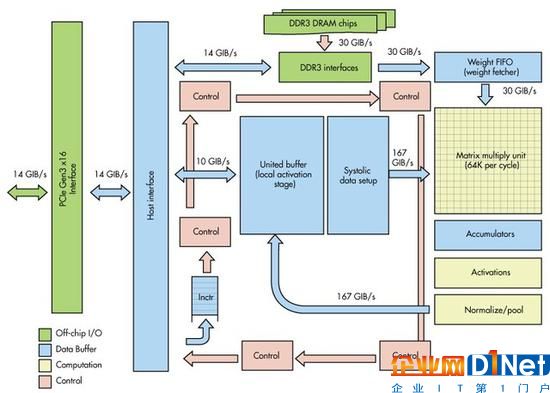

上游廠商喊得再歡,落地到千人千面的行業場景中也要由解決方案商來幫忙,無論是GPU、FPGA還是TPU,最終還是要聽聽客戶的使用感受。為此,我們采訪了人工智能產品和行業解決方案提供商曠視科技。曠視科技利用自主研發的深度學習算法引擎Brain++,服務于金融安全、城市安防、手機AR、商業物聯、工業機器人等五大核心行業。
在曠視科技看來,GPU、FPGA、TPU在通用性和能效比之間的取舍不同。其中,GPU最成熟,但也最耗資源,常用于訓練神經網絡和服務端;FPGA最靈活,能支持應用中出現的特殊操作,但要考慮靈活度和效率之間的trade-off;TPU相對最不靈活,但如果場景合適則能發揮出最大功用。
如果拿汽車類比,GPU是大巴車,適合多人同目標;FPGA是小轎車,能到任何地方,但得自己會開;而TPU是火車,只能在比公路少的多的鐵軌上開,但開的飛快。人工智能還在快速發展,還處于在各個行業落地的過程中。這個階段對GPU,FPGA和TPU都有需求。
目前,曠視科技選擇的是T型技術方案,即在維持一定廣度的同時,深耕某些應用場景,因此在算法實際落地的過程中,自然而然地產生了從GPU/CPU到FPGA的需求。GPU主要用于訓練,而FPGA能在端上能提供比GPU更好的性能功耗比。CPU則是無處不在的“默認“選擇。未來,不排除采用TPU的方案來進一步提高端上的能力。
從行業來看,當前IoT領域對AI芯片的需求最為迫切,原因是IoT領域要求在有限的功耗下完成相應的AI任務,最需要性能功耗比高的AI芯片。至于未來要借助AI賦能各個行業,曠視科技認為,最初階段可能都會先用GPU的AI方案,因為和源頭(即神經網絡訓練階段)銜接最好。另外對于中心化的應用,只要GPU按現在的“黃定律”的速度迭代前進,基于GPU在大批量處理數據的場景下仍然經常是公開可得的最佳方案。








 京公網安備 11010502049343號
京公網安備 11010502049343號