


工業大數據的目的是為了改變以往工業價值鏈從生產端向消費端、上游向下游推動的模式,實現以客戶價值為核心的定制化產品和服務,以及與之相適應的全產業鏈協同優化。為此,工業大數據應滿足用戶需求定義、工業智能制造、活動協同優化三方面的應用。
在這些應用中,工業大數據的落地需要與之相適應的技術架構作為支撐。目前,李杰教授提出的“5C”架構體現了工業大數據“數據->知識->應用”的信息架構,而工業互聯網參考架構(IIRA)和工業4.0參考架構(RAMI4.0)均是頂層系統架構,還有一些公司企業依據自身的業務提出了自定義的技術架構,如通用的Predix、三一的根云等。
我們知道技術架構應由應用場景的特征來決定,就現狀而言,工業大數據還處在產業的初級階段,對工業大數據應用場景的認知還不太深入,但大數據在互聯網的應用已具備成熟的技術體系和應用框架,因此,本文主要通過比較工業應用場景和互聯網應用場景的差異性,期望能夠修正互聯網大數據的相關應用技術框架,以滿足工業大數據落地對技術框架的要求。
工業大數據和互聯網大數據的技術架構都具備數據環境、知識環境和應用環境三個層,如下圖所示。
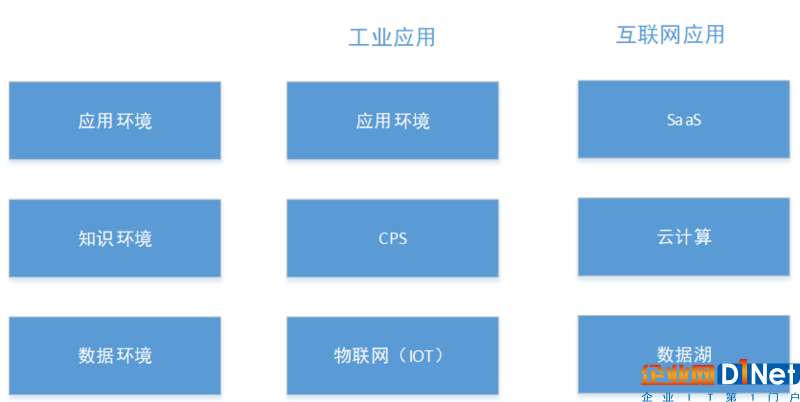
從數據環境來看,首先,互聯網大數據和工業大數據具備不同特征。如下表所示:
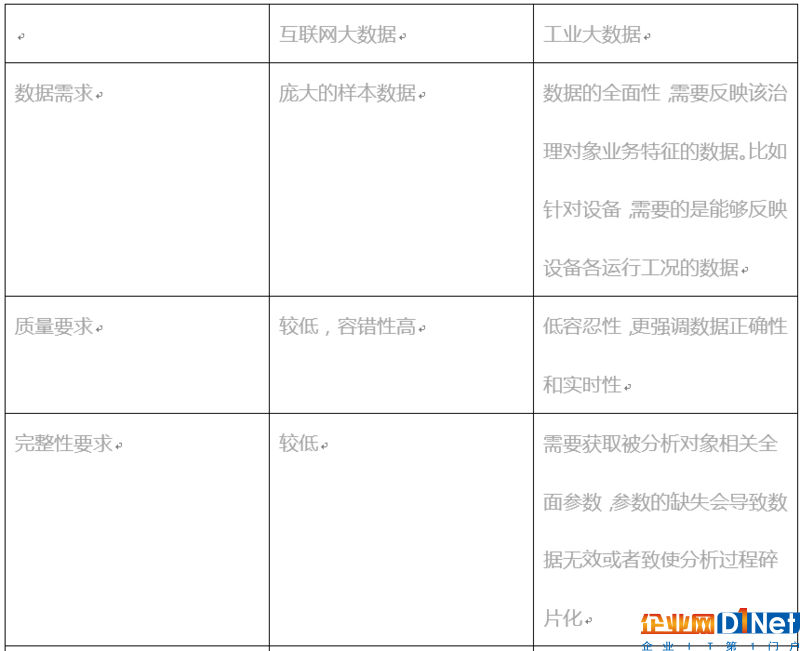
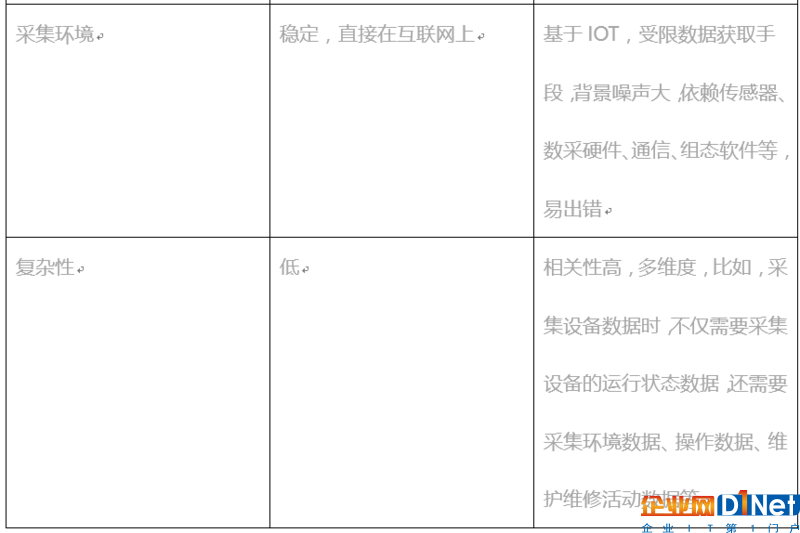

由于上述對數據的差異性,互聯網大數據更多的是關注數據的持久化,其技術架構側重于實現異構數據的存儲、訪問的一致性,滿足多負載的并行讀能力。所以,互聯網催生了大量的非關系型數據庫、實時數據庫、分布式文件存儲的技術。
工業大數據同樣關注數據持久化,但工業大數據部署應用的一個原則是將應用盡可能部署在離數據產生源越近的地方。這是因為,就近部署其可靠性、實時性越高。需要按照業務需要進行部署,因此,很多應用部署在設備、生產車間等。所以,與互聯網大數據集中式存放的方式相比,工業大數據對數據存放更加離散化,在空間中形成跨網的分布式存儲,且各數據節點對數據存放、訪問的能力要求不一樣。比如以在某一公司實施的智能風場項目為例,在風機上部署的采集終端,需要存儲結構化且要求實時性高的技術方案;在相應業務端,如生產系統或調度系統,數據是半結構化且實時性要求一般;在公司數據中心,數據是非結構化且需要語義組織。因此,需要抽象和設計一個統一的數據持久化環境,為工業大數據的上層應用提供基于語義的數據發現和相適宜的訪問能力。
另外,工業大數據的數據環境,更關注數據采集的能力。工業大數據的數據采集依賴于物聯網(IOT)的實現,IOT關注的采集的可靠性,實現數據接入的總線化,但工業大數據對IOT提出了更多的需要。以在某一公司實施的智能風場項目為例,在設計數據采集時,考慮了如下一系列的需要。
一,IOT終端需要具備邊緣計算能力,首先是風機高頻運行狀態數據沒必要全部上傳,只需要上傳從風機運行狀態數據提取的相應特征數據,在必要時,如發生故障需要原始數據進行深入分析或者為訓練模型需要原始數據,才需要終端上傳數據。因此IOT終端需要運行特征提取算法;
二,IOT終端需要具備對采集數據的辨偽能力,需要對數據質量進行預判和修復。在采集風機運行數據時,數據大多是通過傳感器,傳感器本身存在故障、標定、存在壽命等問題,產生錯誤數據的概率較大,而壞數據對基于物理關聯和因果分析的模型影響相對于互聯網應用基于統計分析的影響更高;
三,IOT需要提供更智能的接入能力,形成數據生態環境,因為工業數據不會自發形成,不像互聯網一樣本身在線,需要解決傳感器、物聯網、嵌入式智能等在邊緣端需要解決的技術問題;
四,IOT需要提供基于語義的定義,是因為作為工業大數據應用的最基本數據產生源,它是物理世界實體的高度抽象,能夠映射物理世界實體的特征、實體間的關系,能夠發現和被發現,提供互操作性,從而形成物理世界在虛擬世界里的組織和協作能力。
知識環境工業大數據和互聯網大數據都需要對數據進行分析、處理,以獲得相應的知識,用以支撐上層業務應用。它們的差異性首先體現在模型特性上面。如下表所示:
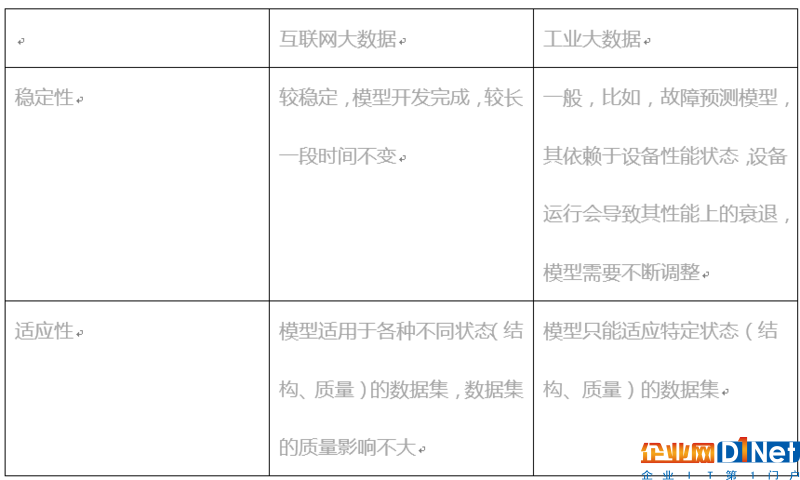
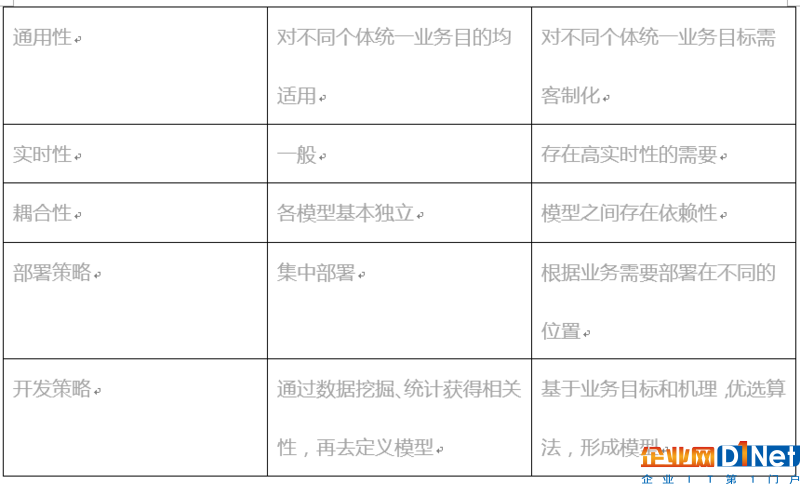
由模型的差異性,在工業大數據和互聯網大數據應用中,對模型執行的環境要求有很大區別。
目前,在互聯網環境中,一般都是基于云平臺,使用hadoop生態環境進行搭建,通過流式或離線計算對數據進行處理,采用容器技術運行相應的計算模型,統一對外提供知識數據的訪問,其根本是在于其服務或者算法的通用性和可復制性,當一個服務滿足不了外部需求,可以通過容器方便的產生副本,擴展其提供外部訪問的能力,而微服務、無服務等技術架構更多是基于對服務的結構、協作等的重新定義,來解決服務響應、資源使用、實施、并行等相關非功能特性。而在工業大數據中,絕大多數模型對外提供服務并不用在意訪問的并發性,比如風場智能運維系統對某個風機的健康狀態評估,使用其評估結果的外部訪問僅限于幾個終端,畢竟是只有與風機相關的干涉人才會需要。因此,工業大數據應用所需要的模型執行平臺關注的是單例執行效率以及類型的擴展性。
另外,工業大數據應用的模型相關性較強。比如,在風場智能運維系統中,對風機的狀態評估,依賴于對其組成的多個部件的健康評估,對風機發電效率預測需要結合環境、風機健康狀態的結果。因此,工業大數據應用所需要的模型執行平臺還需要提供較好的模型執行協作環境。
因此,工業大數據的知識環境的技術平臺是CPS,云計算是CPS的一個組成部分。CPS關注的是物理實體映射的邏輯實體的管理,提供邏輯實體的關系、協作,以對稱的方式來演進,體現與物理實體的相關性,實現知識的挖掘。
應用環境互聯網大數據的應用可以充分利用云平臺相關的技術提供集中式的服務環境,對外以SaaS的方式提供應用功能,但工業大數據的應用多樣,既有對物(設備、生產線)的嵌入式應用,也有與傳統信息系統相似的應用,如風場的維護排程優化、設備狀態監控,也有與互聯網大數據應用相同的SaaS應用,如Predix。
因此,工業大數據的應用環境包括了嵌入式環境、單機環境、集群或云平臺環境,需要考慮應用支撐環境的多樣性統一;其次,工業大數據的應用部署可以在生產一線、控制中心、數據中心等地域分離的地方,其應用環境也需要提供應用跨域的協作能力和應用從故障中恢復的能力;工業大數據的應用環境不僅需要提供服務本身的彈性擴展(并發能力和瞬時負載能力),還需要提供服務的(類型、行為、資源要求)多樣性擴展。
總之,由互聯網推動的大數據、智能應用等已成熟的技術體系和應用框架,是構建工業大數據應用的最好參考,是工業大數據技術實施的基礎。但建立有效的工業大數據應用,離不開工業應用技術的核心——CPS平臺,并在相應的信息架構、資源架構等方面,做出合適的設計和實踐。
作者簡介朱武,任職于北京天澤智云科技有限公司,承擔過多項國家重點型號科研項目,擅長工業領域的軟件系統開發、測試和架構設計。曾就職于中國船舶系統工程研究院,主導并實施海軍后勤裝備保障體系信息化建設;作為總架構師與IMS共同合作,參與船舶智能運行與維護(SOMS)系統等多個智能化系統的架構設計和實施。








 京公網安備 11010502049343號
京公網安備 11010502049343號