









文 中國建設銀行北京數據中心 王昌旭 林莉 王周碩
銀行業大數據應用現狀簡介
大數據是指社會生產生活和管理服務過程中形成的,依托現代信息技術采集、傳輸、匯總的,超過傳統數據系統處理能力的數據,具有數據量大、數據類型多、處理速度要求快等特點,通過整合共享、交叉復用、提取分析可獲取新知識,創造新價值。科學界一般將大數據視為“海量數據+復雜的數據類型”。
21世紀是數據信息大發展的時代,移動互聯、社交網絡、電子商務等極大拓展了互聯網的邊界和應用范圍,各種數據正在迅速膨脹并變大。2015年的統計數據顯示中國大數據IT應用投資規模,其中金融領域(8.9%)排名第三(如圖1)。金融業中又以銀行業大數據應用投入最大。銀行業具有信息化程度高,數據質量好,數據維度全,數據場景多等特點,因此大數據應用的成熟度較高,也取得了較好的成績。
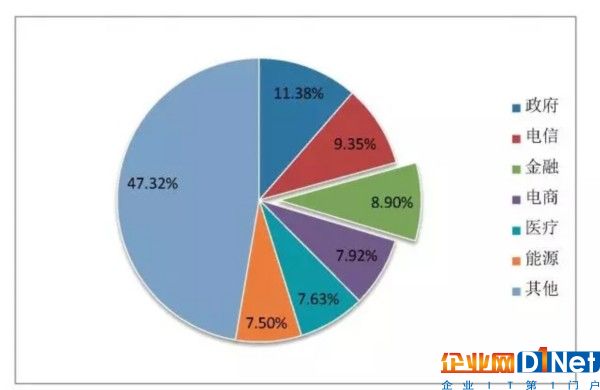
圖1 銀行業大數據應用投資情況
縱觀近幾年國內外銀行業發展趨勢,利用大數據技術預測客戶行為并據此優化業務模式,成為大型銀行轉型的共同趨勢,一些領先銀行已經借此取得了較大競爭優勢。例如花旗銀行亞太地區,近年來有25%的利潤來自于數據挖掘;匯豐銀行通過數據挖掘開展交叉銷售,使客戶貸款產品響應率提高了5倍。總的來看,銀行大數據應用目前主要集中在客戶畫像、精準營銷、風險管控和運營優化等領域。在“十二五”規劃中,大數據已不再只是專有名詞,大數據已然上升為國家戰略。
一般情況下在數據量低于20TB,用戶數量低于50萬時,傳統的數據倉庫和分析工具可以滿足數據分析需要。如果需要處理的數據超過這個范圍,傳統數據平臺的投資會高達幾千萬,未來維護成本也很高。這種情況下銀行業需要利用大數據平臺來處理。在這個量級以上大數據平臺處理效率比傳統的數據倉庫要高很多,總的投資費用和維護費用也要更低。大數據平臺普遍要求高效性,并發數據處理能力強,能在短時間內分析處理海量的數據。一般采用分布式處理、分布式數據庫及分布式存儲,把數據分散在多個節點上進行高效處理。高擴展性,可以靈活地從幾十臺擴展到幾千臺不等的各種規模,能夠處理PB級數據;高容錯性,自動保存數據的多個副本,自動將失敗的任務重新分配;讀多寫少,更強調查詢性能,適合各種緯度的數據挖掘分析。
隨著我國經濟的發展和直接融資規模不斷擴大,銀行業仍有不錯的前景。銀行業由于追求效率、優化結構和控制風險的需要,未來越來越依賴大數據技術的支持。貴陽大數據交易所預測,我國金融大數據市場規模預計2020年將達到450億元。總的來看,大數據在銀行業的應用深度和廣度還有很大的擴展空間。銀行業的大數據應用依然有很多的障礙需要克服,比如銀行企業內各業務的數據孤島問題嚴重、大數據人才相對缺乏以及缺乏銀行之外的外部數據整合等問題。可喜的是,銀行業尤其是銀行的中高層對大數據渴望和重視度非常高,相信在未來的幾年內,在互聯網和移動互聯網的驅動下,銀行業的大數據應用將迎來突破性發展。
銀行業大數據發展與基礎設施規劃的關系
隨著銀行業大數據應用的蓬勃發展,需要存儲的數據量呈爆發式增長,配套的服務器設備、網絡設備大量增加,對數據中心存儲系統、網絡系統、數據備份、機房等基礎設施提出了巨大挑戰。提前做好基礎設施的規劃對于銀行業大數據應用的可持續發展至關重要。
1.大數據與存儲方式規劃
當前面臨數據爆炸的問題,一是數據量的爆炸性劇增。最近2年所產生的數據量等同于2010年以前整個人類文明產生的數據量總和;二是數據來源的極大豐富,形成了多源異構的數據形態。其中非結構化數據(包括語音、視頻、圖像等)所占比例逐年增大。2006 年才剛剛邁進TB時代,全球共新產生了約180EB的數據,在2011 年這個數字就達到了1.8ZB。而有市場研究機構預測:到2020 年,整個世界的數據總量將會達到35.2ZB(1ZB=10 億TB),如圖2。
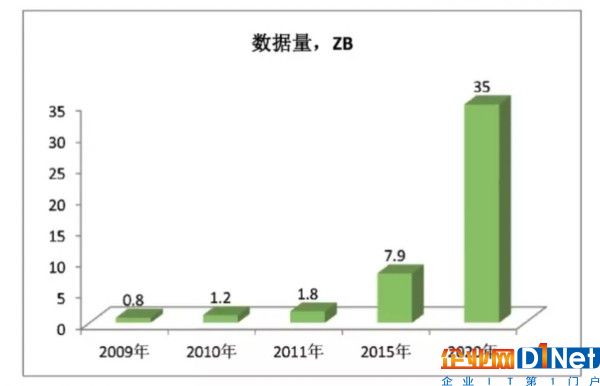
圖2 數據量增長情況圖
根據波士頓咨詢公司發布的《互聯網金融生態系統2020系列報告之大數據篇》,該報告顯示,銀行業的數據強度高于其他行業,每創收100萬美元,平均就會產生820GB的數據,而在電信行業產生的數據量為460GB,快速消費品行業這一數字僅為180GB。由此可見,銀行業的數據量更大,對存儲系統的要求更高。
大數據的存儲成本非常昂貴。“2000年左右,某國有商業銀行建設數據倉庫,一期投資是1億元”。盡管數據儲存成本已經從每GB單位10萬元降低到每TB單位10萬元,但是銀行業的大數據量已經快速地從TB級增加到了PB級。以存儲10PB的數據來計算,存儲成本高達10億元。參考互聯網行業的大數據,2012年百度的大數據存儲量就已經超過100PB,阿里巴巴的存儲量也超過60PB,騰訊的TDW存儲容量在2014年達到100TB,Yahoo 2012年的存儲量更是超過350PB。銀行業的大數據預計在未來幾年將突破1000PB,達到EB級。
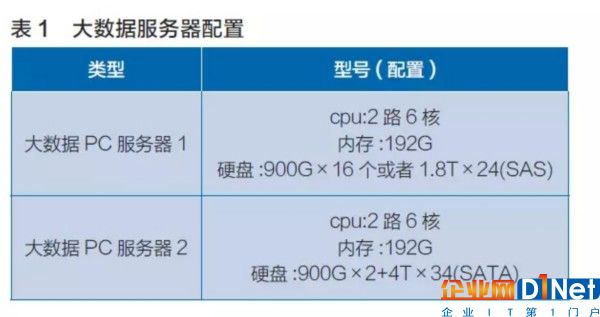
銀行應該如何選擇大數據的存儲呢?為了降低數據存儲成本,采用高端的SAN和IP SAN存儲,甚至NAS存儲都是不可行的。銀行的大數據存儲可以采用廉價的大容量X86服務器,普通的X86服務器設備已經可以達到43.2T/臺。同樣儲存10PB數據,采購230臺X86服務器,存儲成本可以降低到2300萬元,在提供存儲空間的同時,還獲得了強大的計算能力,可謂“一舉兩得”。由于X86服務器處理能力已經大大提高,完全可以滿足一般的大數據處理性能需求。同時,建議按照大數據訪問頻繁程度分層,按“溫度”放在不同檔次的存儲上,對于大數據應用對讀寫性能要求較高的場景,可以配置SAS硬盤,未來還可以考慮使用SSD固態硬盤。對于讀寫性能要求不高的應用,例如歷史歸檔數據,可以使用更廉價的SATA硬盤,單臺設備容量已經可以達到136TB,進一步降低大數據儲存成本,可以參考的服務器配置如表1。
2.大數據與網絡架構規劃
大數據規模從幾TB到幾PB數據量不等,要求高性能系統實時地或者接近實時地處理大量數據。適用于大數據的技術包括大規模并行處理(MPP)數據庫、數據挖掘網格計算、Apache Hadoop框架、分布式文件系統、分布式數據庫、Map Reduce算法、云計算平臺、互聯網和歸檔存儲系統。大數據一般采用龐大的計算集群和先進技術及算法來減少數據集,并控制數據如何進出服務器,需要以非常高速和高性能的方式連接計算機的最新網絡架構。
目前,各家網絡廠商正在以支持大型計算集群的新網絡架構配置來應對這些需求。傳統網絡分為核心層、匯聚層和接入層,對于擔負以往工作負載的數據中心是適用的。當通信方式以南北方向(換句話說,就是進出數據中心的通信)占主導地位時,傳統數據中心三層架構還是具有優勢的(如圖3)。
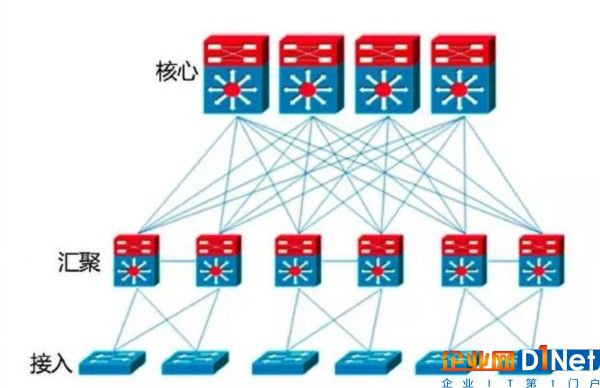
圖3 傳統三層網絡架構
但是當銀行業大數據應用的通信以東西方向占主導地位時(如計算集群或虛擬化計算),傳統的三層網絡架構就不再適用,需要使用分布式核心架構。例如一臺服務器需要與不在同一網段上的服務器進行通信時,必須通過接入層—匯聚層—核心層—匯聚層—接入層的路徑。這種方式在面對成千上萬臺服務器相互通信的大數據業務時就不是一種有效的方式,不但系統帶寬會被大量消耗,還會造成不可預測的延時,從而形成網絡阻塞。因此近年來全球大型互聯網數據中心越來越多地采用便于橫向數據傳輸(東西向)的葉脊兩層(Leaf-Spine)網絡結構。
分布式核心架構也稱為“Leaf-Spine架構”(如圖4),它包括兩種類型節點: 一種節點連接服務器和架頂設備(leaf節點);第二種節點連接交換機(spine節點),Leaf-Spine系統架構內的任意兩個端口之間提供延遲非常低的無阻塞性能。其最大的特點就是每一個葉交換節點都與每一個脊交換節點相連,從而大大提高了不同服務器間的通信效率并且降低了延時。此外,采用脊葉兩層網絡結構可以不必采購價格昂貴的核心層交換設備,并且更便于根據業務需要逐漸增加交換機和網絡設備進行擴容,有效節省初期投資。
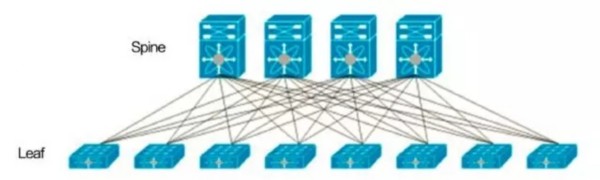
圖4 Leaf-Spine分布式核心架構
根據實踐經驗來看, 分布式核心架構可以很好地適應目前銀行業的GreenPlum和Hadoop大數據集群,根據大數據對網絡帶寬的需求,建議優先采用10GB網絡接入。隨著用戶對數據中心網絡帶寬需求的逐年提高,數據中心主干網絡已經逐漸由10G向40G演進,今后還將會升級到100G。這種網絡結構不但可以支持40G網絡,還可以平滑地升級到未來的100G網絡,有效解決了用戶對未來系統升級的困擾。
3.大數據與數據備份方式規劃
大數據非實時數據,數據量巨大,如何進行數據備份,防止數據丟失。按照單個大數據集群10PB的數據量,如果采用傳統數據備份方式,有兩個問題難以解決:一是備份時間過長,每次的備份時間將達到數十小時,甚至數天。例如備份100TB的數據需要約10小時,備份10PB的數據則需要1000小時。二是備份目標消耗的存儲資源過多,如果保存多份全量數據,無論是磁帶備份,還是磁盤備份,都無法滿足大數據備份的海量需求。
由于大數據應用通常并不會被定位為關鍵業務系統,不會用于處理運營數據,雖然它們也支持銷售和營銷決策,但是并不會顯著影響一些核心運營業務,如客戶管理、訂單、庫存和配送等。遇到大數據時該怎么辦?大多數公司認為大數據的備份與恢復并不重要。其中包括以下原因。
一是故障發生后對可選數據(賬戶、訂單等)的恢復有著更高的優先級。二是大數據解決方案并不運行關鍵業務。此外,由于分析是在一個大范圍的時間序列上進行的,所以大數據恢復并不需要做到完全最新。三是大數據真的很大,因此備份大量數據所需要的存儲介質成本是難以承受的。四是對于處理數據和必要的數據通道容量來說,存儲和加載到大數據表是非常昂貴而又耗時的,事實上,它可能會需要幾天或幾星期的時間才能完整恢復整個數據存儲。
銀行業大數據備份采用那種方式呢?根據實踐經驗來看,銀行業大數據由于數據量大,不適合采用傳統的磁帶庫等數據備份方式,建議可以采用數據復制的方式。通過采用廉價的大容量服務器進行數據備份,保存多份數據的方式,結合全量備份和增量備份。例如Hadoop的HDFS就內置了數據復制方式,可以靈活設置數據復制的份數,GreenPlum也有類似的機制。在一次全量備份的基礎上,后續采用增量備份。另外,還建議結合數據壓縮和重復數據刪除技術。大數據不能采用傳統磁帶庫備份或虛擬帶庫方式,更不適合采用本地與遠程副本方式,復制遠程副本必然大量消耗網絡帶寬,需要額外增加網絡線路的成本。采用數據復制的主要優點:一是降低成本;二是提高讀寫速率,讀取數據更加方便。當然,這種方案的缺點是顯著增加了X86服務器的數量。以10PB大數據量為例,儲存一份數據需要230臺服務器,如果再保留一份數據副本則需要增加到460臺服務器,服務器的增加對機房規劃提出了新的挑戰。
4.大數據與機房規劃
目前大數據普遍采用X86服務器物理機構建集群的方式,例如阿里巴巴2012年的Hadoop集群規模已經高達5000臺;騰訊2012年的Hadoop集群總數超過5000臺,最大單集群約為2000臺;百度2012年的集群數近10個,單集群超過2800臺,Hadoop總數超過萬臺。2017年的最新數據表明,騰訊最大集群約8800臺,阿里巴巴最大集群接近1萬臺,百度最大集群也接近1萬臺,華為最大集群約3000臺。銀行業大數據應用也采用大量廉價X86服務器,例如農業銀行2015年建成的Gbase國產大數據集群采用了236節點X86服務器。某國有銀行單個Hadoop大數據最大集群已經接近580臺,GreenPlum最大集群也接近200臺,這樣的集群累計有數十個,所有大數據服務器已經達到約3000臺。
結合大數據行業趨勢,根據目前的增長情況判斷,未來銀行業大數據服務器的規模還將快速增加,幾年內將很快突破5000臺,甚至超過10000臺。如此大規模的服務器,必然對數據中心的機房、電力、網絡都提出挑戰。結合實踐經驗來看,銀行業大數據應用的機房規劃需要重點考慮如下因素。
單獨的大數據機房空間。由于大數據網絡架構的特殊性,建議規劃單獨的大數據機房空間,避免網絡流量互相影響。
機房空間的擴展性。由于大數據應用采用集群方式,集群內的節點之間有大量的內容如網絡通信流量,對帶寬和延時要求極高。因此,同一大數據集群內的節點擴容通常需要部署在同一Spine架構下,這種擴容方式可以把網絡流量限制在小范圍內,避免影響到網絡的匯聚和網絡的核心。跨機房樓部署會遇到問題,阿里巴巴在大數據單個集群規模達到5000臺時遇到了跨機房問題,建議在大數據應用部署時,預留未來擴容相鄰的機房空間。
提高機房的供電密度。為了適應大量部署X86物理機,節省機房空間資源,需要提高機房內單機柜的部署能力,例如42U的機柜至少可以部署12臺,甚至16臺2U的服務器,按照每臺服務器的實際功耗440W計算,16臺的總功耗超過了7KW。有些數據中心已經在嘗試采用50U以上的機柜,每機柜部署超過20臺2U服務器,功耗將高達8.8KW。建議開辟專門的大數據機房,并提高機房供電密度。
結論
本文研究了銀行業的大數據應用發展現狀,隨著大數據應用的快速發展,對數據中心的基礎設施規劃提出了挑戰。本文查閱了大量文獻資料,經過理論研究,并結合生產實踐,探討了銀行業大數據基礎設施規劃相關的解決方案:大數據存儲可以采用大容量X86服務器,按照數據訪問頻繁程度分層存儲;使用分布式核心架構“Leaf-Spine”網絡架構滿足大帶寬,低延時的網絡需求;數據備份可以采用內置數據復制,復制多份數據,并結合增量備份、壓縮、重復數據刪除等技術;提前規劃機房空間,提高機房供電密度,更好地滿足大數據業務發展。
















 京公網安備 11010502049343號
京公網安備 11010502049343號