


去年下半年,我開始負責公司的用戶畫像工作,經歷了公司用戶畫像從0到1的搭建過程。從一個大數據小白,開始慢慢了解神秘的大數據是,與數據同事通力合作進行畫像標簽的清洗輸出,設計用戶畫像分析工具和可視化產品。

本文不是對大數據千篇一律的感悟,而是我一年內工作積累的干貨,希望對各位產品經理有幫助。
一、大數據是什么?
大數據,big data,《大數據》一書對大數據這么定義,大數據是指不能用隨機分析法(抽樣調查)這樣捷徑,而采用所有數據進行分析處理。
這句話至少傳遞兩種信息:
1、大數據是海量的數據
2、大數據處理無捷徑,對分析處理技術提出了更高的要求
二、大數據的處理流程
下圖是數據處理流程:
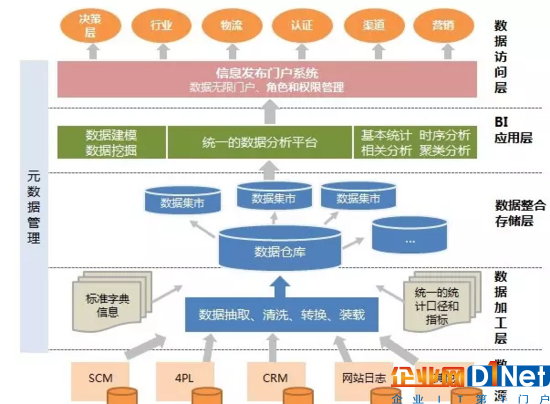
1、底層是數以千億計的數據源,數據源可以是SCM(供應鏈數據),4PL(物流數據),CRM(客戶數據),網站日志以及其他的數據
2、第二層是數據加工層,數據工程師對數據源按照標準的統計口徑和指標對數據進行抽取、清洗、轉化、裝載(整個過程簡稱ELT)
3、第三層是數據倉庫,加工后的數據流入數據倉庫,進行整合和存儲,形成一個又一個數據集市。
數據集市,指分類存儲數據的集合,即按照不同部門或用戶的需求存儲數據。
4、第四層是BI(商業智能),按照業務需求,對數據進行分析建模、挖掘、運算,輸出統一的數據分析平臺
5、第五層是數據訪問層,對不同的需求方開放不同的數據角色和權限,以數據驅動業務。
大數據的量級,決定了大數據處理及應用的難度,需要利用特定的技術工具去處理大數據。
三、大數據處理技術
以最常使用的hadoop為例:
Hadoop是Apache公司開發的一個開源框架,它允許在整個集群使用簡單編程模型計算機的分布式環境存儲并處理大數據。
集群是指,2臺或2臺以上服務器構建節點,提供數據服務。單臺服務器,無法處理海量的大數據。服務器越多,集群的威力越大。
Hadoop類似于一個數據生態圈,不同的模塊各司其職。下圖是Hadoop官網的生態圖。
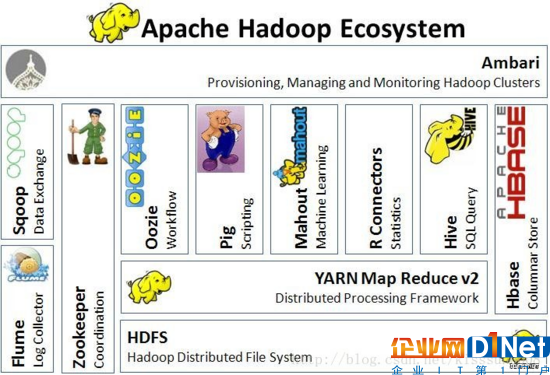
Hadoop的LOGO是一只靈活的大象。關于LOGO的來源,網上眾說紛紜,有人說,是因為大象象征龐然大物,指代大數據,Hadoop讓大數據變得靈活。而官方蓋章,LOGO來源于創始人Doug Cutting的孩子曾為一個大象玩具取名hadoop。
從上圖可以看出,Hadoop的核心是HDFS,YARN和Map Reduce,下面和大家講一講,幾個主要模塊的含義和功能。
1、HDFS(分布式文件存儲系統)
數據以塊的形式,分布在集群的不同節點。在使用HDFS時,無需關心數據是存儲在哪個節點上、或者是從哪個節點從獲取的,只需像使用本地文件系統一樣管理和存儲文件系統中的數據。
2、Map Reduce(分布式計算框架)
分布式計算框架將復雜的數據集分發給不同的節點去操作,每個節點會周期性的返回它所完成的工作和最新的狀態。大家可以結合下圖理解Map Reduce原理:
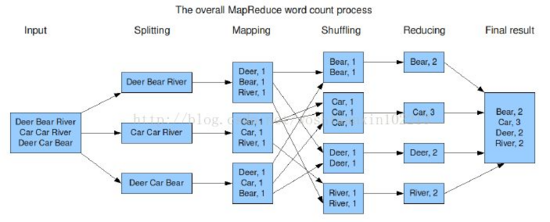
計算機要對輸入的單詞進行計數:
如果采用集中式計算方式,我們要先算出一個單詞如Deer出現了多少次,再算另一個單詞出現了多少次,直到所有單詞統計完畢,將浪費大量的時間和資源。
如果采用分布式計算方式,計算將變得高效。我們將數據隨機分配給三個節點,由節點去分別統計各自處理的數據中單詞出現的次數,再將相同的單詞進行聚合,輸出最后的結果。
3、YARN(資源調度器)
相當于電腦的任務管理器,對資源進行管理和調度。
4、HBASE(分布式數據庫)
HBase是非關系型數據庫(Nosql),在某些業務場景下,數據存儲查詢在Hbase的使用效率更高。
關于關系型數據庫和菲關系型數據庫的區別,會在以后的文章進行詳述。
5、HIVE(數據倉庫)
HIVE是基于Hadoop的一個數據倉庫工具,可以用SQL的語言轉化成Map Reduce任務對hdfs數據的查詢分析。HIVE的好處在于,使用者無需寫Map Reduce任務,只需要掌握SQL即可完成查詢分析工作。
6、 Spark(大數據計算引擎)
Spark是專為大規模數據處理而設計的快速通用的計算引擎
7、Mahout(機器學習挖掘庫)
Mahout是一個可擴展的機器學習和數據挖掘庫
8、Sqoop
Sqoop可以將關系型數據庫導入Hadoop的HDFS中,也可以將HDFS的數據導進到關系型數據庫中
除上述模塊外,Hadoop還有Zookeeper、Chukwa等多種模塊,因為是開源的,所以未來還有出現更多更高效的模塊,大家感興趣可以上網了解。
通過Hadoop強大的生態圈,完成大數據處理流程。
關于云服務、機器學習以及更多大數據熱門應用將在下一篇文章和大家探討。








 京公網安備 11010502049343號
京公網安備 11010502049343號