









由Amazon、谷歌以及Facebook等網絡巨頭所收集到的龐大數據集正帶來旺盛的處理需求,這也直接推動了新一代芯片的構建。而其中兩項最新成果將在今年6月下旬召開的計算機架構大會上得以亮相。
斯坦福大學的研究人員們將在會上介紹Plasticine,這款可重配置處理器能夠提供近百倍于FPGA的每瓦處理性能提升,同時更易于編程。另外,由英偉達公司兩位資深設計師打造的一款推理處理器則能夠實現兩倍于現有設備的性能與能源效率。
這些芯片的出現還僅僅是整個行業研發努力的冰山一角。英特爾公司去年收購了三家機器學習初創企業。而作為英特爾的競爭對手,三星以及戴爾-EMC亦決定注資Graphcore(來自英國布里斯托爾),后者為這一領域六家獨立初創企業中的一家。
與此同時,英偉達公司亦在努力推動其GPU產品作為神經網絡當中的訓練平臺。另外,該公司亦在積極調整具體架構以進一步提升相關工作的處理效果。
谷歌公司就此給出了不同答案——其認為無論是大規模x86 CPU集群還是英偉達的GPU都不足以最大程度完成這項任務。因此,谷歌方面推出了自己的兩款加速版本,即TPU。

Graphcore公司首席執行官Nigel Toon表示,“計算2.0時代已然到來; 這顯然代表著計算科學的新世界。考慮到高達98%的營收皆由搜索業務這一理想的機器學習技術應用場景所提供,谷歌公司最終使用大量由TPU構建的機架——其中幾乎不存在任何CPU。”
最終,機器學習芯片將廣泛出現在各類嵌入式系統當中。與全年1000萬臺的服務器銷售量相比,目前世界范圍內汽車的年銷售量為1800萬輛。Toon指出,“自動駕駛車輛的發展前景將給這項技術帶來更為廣闊的空間,更重要的是這一市場目前尚未真正建立起來。”
目前行業的普遍愿景在于開發一款AI處理器,并利用其處理當前神經網絡當中的訓練與推理等任務——甚至希望借此催生出部分自我學習技術。此類處理器需要以大規模并行化方式提供強大性能,但同時具備低功耗以及易于編程等優勢。
事實上,連此類處理器的基本運算能力都引發了熱烈的討論。在Toon看來,此類處理器應當能夠將16位浮點乘法與32位加法運算相結合,從而提供最佳精度與最低錯誤率。
而英偉達公司在其Volta張量計算核心當中也正是使用了這一方式,這意味著Graphcore公司將于今年10月開始向合作伙伴進行早期供應的高端芯片面臨著巨大的競爭壓力。這家初創企業專注于利用新型芯片內/外之內存化與互連機制構建出一款能夠接入各單元與集群的大型芯片。
由Kunle Olukotun帶領的斯坦福大學研究人員團隊也設立起類似的目標,但采用的實現途徑卻與Plasticine有所不同。
“多核心時代正逐步邁向終點……在機器學習這一時代背景之下,我們需要立足于現代應用本身對計算模式加以變更,”曾率先為一家初創企業設計多核心方案(此項技術最終被引入甲骨文公司的Sparc處理器)的Oluotun解釋稱。
“面對機器學習中的統計模型,我們真正需要的計算方式將與經典確定性計算存在巨大區別,因此這亦代表著可觀的發展機遇。”
與來自布里斯托爾的競爭對手類似,斯坦福大學的研究小組同樣拋棄了共享高速緩存等傳統思路。“其中最令人興奮的因素在于硬件,大家可以對其進行重新配置以實現對特定計算任務的優化,”斯坦福大學數據科學項目執行董事Stephen Eglash在介紹Plasticine時表示。

Olukotun解釋稱,“我們的目標在于幫助擁有特定領域專業知識的用戶在無需了解機器學習或者硬件認知的前提下構建起高質量機器學習系統。”
為了實現這一目標,斯坦福大學團隊定義了Spatial,這種語言負責將算法中的各部分映射至并發處理器中的各部分。“我們立足于一套高級TensorFLow框架構建起一套完整編譯器流程以表達硬件……具體來講,其每瓦性能水平可達FPGA的10倍,而編程易行性則可達FPGA的上百倍,”Olukotun解釋稱。
Spatial類似于英偉達公司的Cuda GPU編程語言,但在易用性方面應該更為出色。其能夠將scatter/gather或者MapReduce等函數映射至硬件當中的具體內存層級結構當中,從而實現經由DRAM與SRAM的流式數據集。
Olukotun解釋稱,如此一來,Pasticine處理器“即成為一個軟件至上型項目”。
Eglash還意識到物聯網浪潮帶來的邊緣計算需求必須具備對應的技術方案。“未來,我們所生產的數據量將遠超面向云環境的傳輸能力,因此我們還需要分布式本地計算資源的協同支持。”
著眼于短期,機器學習將帶來“超個性化”智能手機以自動定制用戶喜好。如此一來,使用者將不再需要密碼或者指紋。“手機能夠在數秒鐘之內即意識到當前用戶是否為其真正的主人,”Eglash表示。
在工業物聯網領域,推理工作已經被分配至網關處,通用電氣數字公司云工程技術負責人Darren Haas解釋稱。“我們的一切建設項目皆可被劃分為更小的設備,甚至經由Raspberry Pi單片機實現……我們將大規模模型運行在云端,并在邊緣位置運行各類輕量級硬件。”
斯坦福大學構建的Plasticine是一種全新架構,并可能為Graphcore等初創企業廠商所采用。其利用并行模式與高層級抽象以捕捉具體的數據位置、內存訪問模式以及控制流,從而“跨越多種不同應用密度水平”執行運算,相關論文解釋稱。
作為其核心,這款芯片采用16 x 8交錯式計算單元(簡稱PCU)與模式內存單元(簡稱PMU)陣列,且各單元通過三條互連通道利用三種控制協議實現對接。這款113平方毫米的芯片采用Spatial以將應用程序映射至陣列當中,用以交付相當于28納米制程FPGA芯片約95倍的性能水平以及高達77倍的每瓦性能。
Plasticine在1 GHz時鐘頻率運行狀態下最高能耗為49瓦。其峰值單精度浮點運算性能為12.3萬億次,而片上總容量為16 MB。
PCU屬于由執行嵌套模式之可重配置SIMD功能單元構成的多段式管道。PMU采用暫存式內存與專用尋址邏輯及地址解碼器。
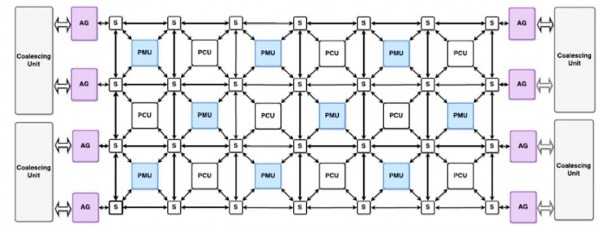
Plasticine采用16 x 8模式計算單元(簡稱PCU)與模式內存單元(簡稱PMU)陣列,同時內置有地址生成器與交換機制
這些主單元及其它外圍元件通過字級標量、多字向量與bit級控制互連實現對接,且皆使用同樣的拓撲結構。各鏈接采用一套分布式分層控制模式以盡可能降低需要同步的單元數量,意味著其能夠實現按序、流水線或者流式執行能力。
該方案“簡化了編譯器的映射方式并提升了執行效率,”論文當中解釋稱。“每個Eplasticine組件皆用于對應用程序中的特定部分進行映射:位置地址計算由PMU完成,DRAM地址計算由DRAM地址管理單元完成,而剩余數據計算則由PCU完成。”
“從本質上講,這可以被視為一組利用特定地址單元生成鄰近地址的庫式內存,”Olukotun解釋稱。“大家只需要提供計算布局,其即可在無需解釋具體指令的前提下在正確的時間將數據導流至計算單元。”
這款芯片采用四DDR通道以對接外部DRAM,并配合緩沖與管理機制以最大程度降低芯片外處理強度。
Olukotun解釋稱,“目前大多數機器學習類負載專注于卷積神經網絡的實現,但我們的目標是更加靈活地覆蓋各類不同計算密度的算法,意味著開發者可以隨時對其進行調整,從而將自己的設計思路傳達給硬件。”
研究人員們還面向線性代數、機器學習、數據分析以及圖形分析等常用方向構建起基準測試方案,旨在利用精確的周期對設計中的綜合RTL進行模擬。“我們希望能夠將這些思路貫徹到芯片方案當中,并計劃在未來6到18個月之內完成芯片設計。”
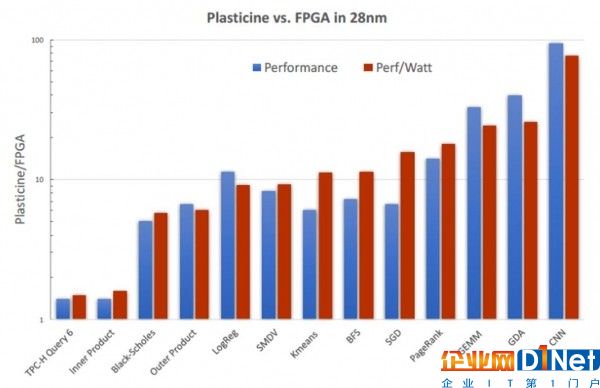
Plasticine與英特爾28納米Startix-V的性能比較結果
由九位成員組成的研究人員小組(其中七位來自英偉達公司)將出席Sparse CNN(簡稱SCNN)卷積神經網絡推理加速器大會。該團隊中包括經驗豐富的微處理器設計師Joel Emer(曾協助定義并發多線程機制)以及英偉達公司首席科學家William Dally。
SCNN與“同等配置密度的CNN加速器”相比能夠提供2.7倍性能水平以及2.3倍能源效率,論文指出。該芯片采取較此前項目更具進取性的設計思路,旨在消除無關緊要的數學運算并高度專注于處理CNN加權及其它操作。
除此之外,其“采用一種新的數據流以降低壓縮編碼過程中的加權與操作量,從而消除不必要的數據傳輸活動并降低存儲資源需求,”論文同時強調稱。“另外,SCNN的數據流將使這些加權與操作更加高效地被傳遞至乘法器陣列內,并在這里進行廣泛使用。”
這套方案使得“較大CNN的所有活動始終處于片上各層間的緩沖區內,這將徹底消除跨層DRAM調用所帶來的高昂網絡資源需求。”
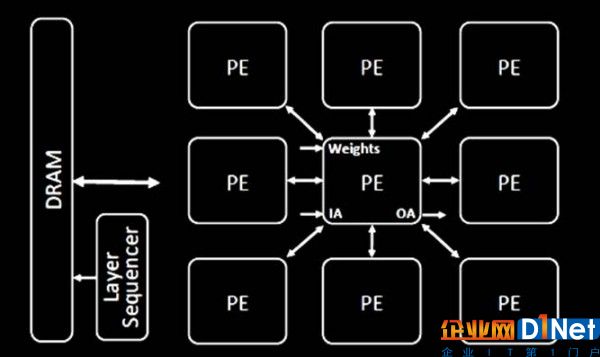
SCNN采用處理元素(簡稱PE)陣列以操作加權與輸入/輸出活動
作為核心設計概念,這款芯片中的每個處理元素(簡稱PE)采用一套乘法器陣列,其能夠接收加權與活動向量。在采用16納米制程技術的情況下,64個PE與16個乘數可全部被納入1個7.4平方毫米的芯片內,這意味著其尺寸相較于同等密度的CNN加速器要略大一點。
這篇論文主要探討了SCNN與其它研究性芯片間的差異。然而,Dally表示他認為SCNN“將憑借著低密度用例的處理優勢而超越其它商用型推理加速器。”
在Plasticine方面,目前公布的結果皆立足于模擬,即尚無任何芯片制備計劃。Dally指出,“我們正在進行布局設計(即布局與布線)以及時序收斂規劃。”
英偉達公司并沒有公布任何將此類技術進行商業化的計劃,僅表示“我們仍在繼續推進這方面的研究工作。”
















 京公網安備 11010502049343號
京公網安備 11010502049343號