











微軟亞洲研究院有一位大名鼎鼎的個人助理,昵稱EDI(音同Eddie),從幫助員工預(yù)訂會議室到更新梳理公司內(nèi)部“八卦”信息,隨叫隨到全年無休;不僅如此,EDI對員工們的喜好也堪稱了如指掌,知道你最喜歡什么時候、最常在哪里開會,也知道你最關(guān)心哪些新聞。這份體貼贏得了越來越多員工的信任和喜愛,目前在研究院中已經(jīng)有超過一半的會議是由EDI來安排——是的,你沒猜錯,EDI是人工智能。
職場知識圖譜
EDI為何如此聰明?一方面,EDI擁有精準的自然語言理解和對話能力;另一方面,利用深度學(xué)習(xí)和社交網(wǎng)絡(luò)融合等前沿技術(shù),EDI為每個用戶構(gòu)建了一張關(guān)于他們的職場知識圖譜。本文首先介紹如何構(gòu)建用戶的職場信息圖譜,這是EDI個人助理的“大腦”,后續(xù)文章將介紹如何賦予EDI自然語言理解和對話能力,讓它能為主人愉快地工作,歡迎有興趣的讀者繼續(xù)關(guān)注。

“The more it has, the more it’s him.” 在英劇《黑鏡》第二季第一集當中,女主人公通過和機器人對話的方式懷念自己逝去的男友。借助大數(shù)據(jù)的力量,這個機器人能夠從主人公男友的社交網(wǎng)絡(luò)甚至私人郵件中抽取和整合他的個人信息、關(guān)系網(wǎng)絡(luò)和語言習(xí)慣,構(gòu)建屬于這位男生的個性化知識圖譜,從而實現(xiàn)對他惟妙惟肖的模仿——如上圖臺詞所說,系統(tǒng)抓取到的信息越多,機器人模仿的語言行為就越和他本人相似。

若說《黑鏡》里的機器人是基于關(guān)于用戶的全方位知識圖譜,那么,本文要介紹的EDI 則專注于用戶的一個側(cè)面,即用戶的職場知識圖譜。
在一個機構(gòu)里,我們把員工的職場知識圖譜叫做EDI Graph(Enterprise Deep Intelligence Graph),圖譜內(nèi)的信息包括員工的部門、技能、項目、文檔、時間、會議室和辦公室等,其中每條信息又有各自豐富的屬性,信息與信息之間也存在豐富的關(guān)聯(lián);這些信息的來源主要分為企業(yè)內(nèi)部數(shù)據(jù)和互聯(lián)網(wǎng)數(shù)據(jù)兩部分,其中,企業(yè)內(nèi)部數(shù)據(jù)主要包括內(nèi)部網(wǎng)頁、文檔、會議記錄、員工基本資料等數(shù)據(jù),互聯(lián)網(wǎng)數(shù)據(jù)則主要包括維基百科、學(xué)術(shù)論文、LinkedIn等公開數(shù)據(jù)。如何將來自公司內(nèi)部、社交網(wǎng)絡(luò)、Web等不同來源的異構(gòu)數(shù)據(jù)進行梳理和融合、構(gòu)成一張完整的職場知識圖譜,這是構(gòu)建EDI Graph的關(guān)鍵技術(shù)。只要有了圖譜,就能構(gòu)建EDI Bot,讓這個昵稱為EDI的機器人擁有“大腦”,能進行理解和分析,了解每個員工的專長以及從事的工作內(nèi)容,成為員工貼心的個人助理。
與《黑鏡》里的機器人相似,EDI也是知道信息越多就越能了解人以及人與人之間的關(guān)系,越接近員工的工作知己。
信息融合
“EDI, where is BJW1?”

對于同一件事,人們往往會有不同的表達,這是人與機器的一大不同。舉例:“BJW1”是英文“北京微軟西1號樓“的簡稱,但人們在不同情境下可能還有其他表達方式,比如“BJW-1”、“Beijing West 1”、“Microsoft Tower 1,Beijing,China”以及“微軟1號樓”等,這些表達上的差異無法用簡單的字符串匹配或縮寫匹配的方式來完成相似度的計算。那么,EDI該如何知曉它們所指的其實是同一個地點呢?
我們的做法是將這些千變?nèi)f化的表達看作不同的語言,通過機器翻譯技術(shù),找到詞與詞之間具有的某種翻譯關(guān)系,從而實現(xiàn)相似詞語的融合。
首先,利用種子規(guī)則,找到信息中高準確度的種子節(jié)點對,利用種子節(jié)點對中屬性的不同表達,構(gòu)建平行語料庫。之后,使用深度學(xué)習(xí)技術(shù)構(gòu)建翻譯模型,完成不同信息源之間的屬性“翻譯”。通過機器翻譯,不僅能計算簡單字符串匹配無法計算的相似表達,甚至還能計算不同語言中同一表達的相似度,讓EDI 能夠吸收消化更多更廣泛的信息來源,對用戶的表達做出更準確的判斷。
“Hi EDI, schedule a meeting with David now.”

得到不同表達的相似度之后,如何精準對應(yīng)也是一門學(xué)問。例如,只要給個人助理EDI發(fā)送一條非常簡潔的信息“幫我和David訂個會議室”,EDI就能幫助員工準確預(yù)訂好會議室。然而只要打開微軟員工目錄,就會發(fā)現(xiàn)名為David的員工大約有兩千名,EDI如何分辨他們并從中確定要和用戶開會那個David究竟是哪一個呢?要知道,這兩千位名為David的員工,有些位于同一部門,甚至職務(wù)也都相同,這時,單單通過機器翻譯得到的屬性相似度,可能無法做出正確的對應(yīng)。
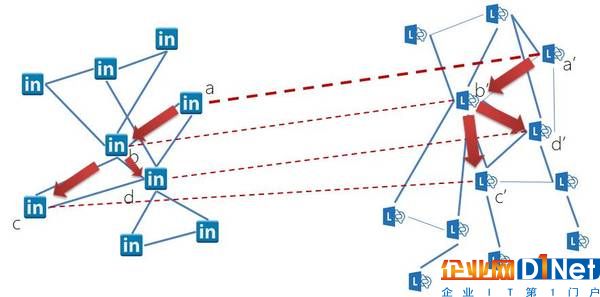
精確匹配的突破口在于不同David的職場知識圖譜,其網(wǎng)絡(luò)結(jié)構(gòu)也是不同的,我們使用協(xié)同訓(xùn)練(Co-Training)的方法,迭代地進行圖結(jié)構(gòu)信息的匹配。在每一輪迭代中,首先利用當前已匹配的實體對,更新神經(jīng)網(wǎng)絡(luò)翻譯模型,并利用更新后的模型完成屬性間的相似度計算;同時,根據(jù)當前已匹配節(jié)點計算待匹配節(jié)點的公共相鄰節(jié)點對,通過結(jié)合屬性匹配和圖結(jié)構(gòu),可以得到新的匹配集合,如此迭代直到收斂。
簡單說,EDI能將職場知識圖譜中同一個David的信息融合到一起,把不同的David放在各自節(jié)點上,然后通過參會歷史、項目合作、內(nèi)部的匯報關(guān)系等等,了解公司同事之間的遠近,從而鎖定用戶真正想找的David,完成用戶交給的安排會議并預(yù)訂會議室的任務(wù)。
信息分析與理解
《黑鏡》中的機器人系統(tǒng)對主人公男友在社交網(wǎng)絡(luò)上的電郵、照片、視頻甚至聊天記錄進行了深入的分析和學(xué)習(xí),從而實現(xiàn)對其惟妙惟肖的模仿。同樣,EDI在掌握豐富的信息之后,也需要進一步分析和理解這些數(shù)據(jù),才能深入了解企業(yè)中的每一個員工。
在一個企業(yè)中為員工構(gòu)建職場知識圖譜,最為基本也最為重要的一點,就是構(gòu)建出每位員工的工作內(nèi)容時間線,通過時間線我們就可以了解到“who,when,what”,即:誰,在何時,做過什么事情。
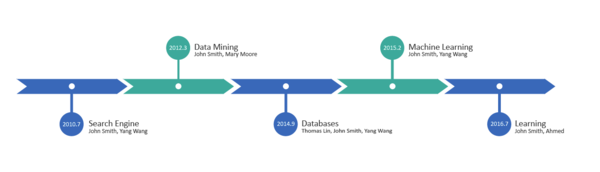
有了這些結(jié)構(gòu)化的知識,如果想知道誰在做Cortana相關(guān)的項目,只需要問“Who is working on Cortana?”,EDI就能給出你想要的答案。這對構(gòu)建企業(yè)智能應(yīng)用具有極為重要的意義。
順帶指出,項目名稱的抽取也不簡單。我們無法通過簡單地標注數(shù)據(jù)、訓(xùn)練模型或是基于規(guī)則的方法來進行抽取,因為不同行業(yè)、不同領(lǐng)域?qū)τ陧椖康谋硎隹赡芮ё內(nèi)f化,那么EDI是如何抽取出工作內(nèi)容以及相關(guān)項目的名稱呢?

我們認為,項目的名稱都是語義完整的短語——例如,在“微軟亞洲研究院在丹棱街5號”這句話里,“微軟亞洲研究院”就是一個語意完整的短語——于是,我們先從企業(yè)內(nèi)部的數(shù)據(jù)抽取出語意完整的短語,再從這些短語中劃分出項目的名稱。在微軟內(nèi)部,各種文檔、網(wǎng)頁等總量在千萬這個數(shù)量級,而統(tǒng)計規(guī)則例如互信息、熵等,在數(shù)據(jù)量較大的時候可以有效地完成對短語的切分。因此,我們在遞歸神經(jīng)網(wǎng)絡(luò)(Recursive Neural Network)模型中通過后驗正則化(Posterior Regularization)引入互信息、熵等統(tǒng)計量定義的偏序切分規(guī)則,在完成短語劃分的同時,得到其對應(yīng)的語意向量表示,最后通過度量語意信息來判斷其是否是一個項目的名稱。
小結(jié)
有了基于企業(yè)內(nèi)部和互聯(lián)網(wǎng)大數(shù)據(jù)構(gòu)建員工的職場知識圖譜EDI Graph,就能讓機器人個人助理EDI Bot擁有聰明的“大腦”,為用戶提供貼心的服務(wù)。我們將在后續(xù)的文章具體介紹EDI Graph怎么被運用到機器人的工作場景中,以及怎樣通過平臺讓機器人獲得與人進行自然語言對話的能力,敬請關(guān)注,也歡迎你就這一題目分享自己的見解和經(jīng)驗。
【大數(shù)據(jù)挖掘組】
微軟亞洲研究院大數(shù)據(jù)挖掘組致力于從大數(shù)據(jù)中挖掘信息構(gòu)建海量知識圖譜,以提高人工智能應(yīng)用中的知識推理和自然語言理解能力。大數(shù)據(jù)挖掘組的研究方向包括數(shù)據(jù)挖掘、大數(shù)據(jù)、深度學(xué)習(xí)、自然語言處理、智能聊天機器人等。十多年來,該組成員的研究成果對微軟的許多重要產(chǎn)品及應(yīng)用產(chǎn)生了深刻影響,包括人立方、微軟學(xué)術(shù)搜索、讀心機器人、微軟知識圖譜(Satori)、智能聊天機器人開發(fā)平臺等。
大數(shù)據(jù)挖掘組現(xiàn)招聘實習(xí)生,工作內(nèi)容涉及機器學(xué)習(xí)、大數(shù)據(jù)挖掘、自然語言處理等領(lǐng)域,工程和研究均可,根據(jù)個人興趣和能力確定工作內(nèi)容。要求編程能力較強;有一定的溝通能力,有責(zé)任心;對機器學(xué)習(xí)、大數(shù)據(jù)挖掘、自然語言處理有熱情和興趣; 高質(zhì)量的完成工作;半年以上實習(xí)期。
















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號