


雷鋒網按:本文作者為Decision Management Solutions的CEO James Taylor,是基于數據分析的決策管理系統構建領域的領先專家,他為各種規模的公司提供戰略咨詢,與客戶的各個部門合作,讓他們可以使用決策模型,數據分析和其他決策技術。
決策管理系統可以幫助公司改進決策過程,開發數據驅動的敏捷業務系統。 Taylor 在 Kdnuggets上介紹了CRISP數據挖掘流程中常見問題和解決方案。本文由雷鋒網編譯。
CRISP-DM (cross-industry standard proCESs for data mining),即跨行業數據挖掘標準流程,描述了數據挖掘的生命周期,是迄今為止最流行的數據挖掘流程,更多CRISP-DM的應用示例請看《CRISP-DM, still the top methodology for analytics, data mining, or data science projects》這篇文章。
之所以許多數據分析人員使用CRISP-DM,因為他們需要的是一種可重復使用的分析方法。然而,如何在日常工作中使用CRISP-DM方法時,仍存在一些問題。排名前四的4個問題分別是對業務需求缺乏認知,盲目的返工,盲目的部署和無法形成迭代。決策建模和決策管理可以解決這些問題,使CRISP-DM流程的價值最大化,并確保模型分析的有效性。
完整的CRISP-DM數據挖掘流程的各個階段如圖1所示。下面介紹每個階段所要完成的任務。
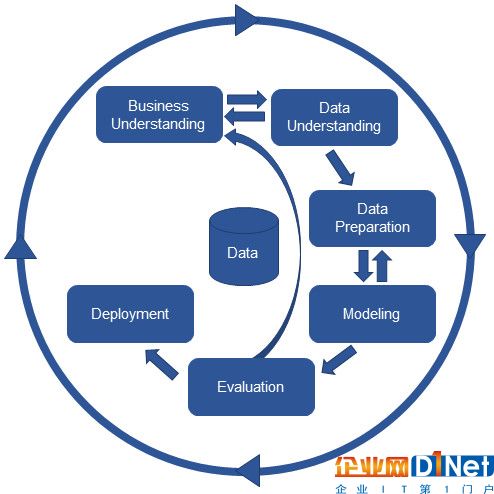
圖1 基于CRISP-DM的完整數據挖掘流程圖
1. 業務理解階段(Business Understanding):集中在理解項目目標和從業務的角度理解需求,定義數據挖掘問題和完成目標的初步計劃;
2. 數據理解階段(Data Understanding):從初始的數據收集開始,通過一些活動的處理,目的是熟悉數據,發現數據的內部屬性,或是探測引起興趣的子集去形成隱含信息的假設;
3. 數據準備階段(Data Preparation):數據準備階段包括從未處理的數據中構造最終數據集的所有活動。這些數據將是建模階段的輸入值,任務包括屬性的選擇、數據表、記錄的抽取,以及將數據轉換為模型工具所需的格式和清洗數據;
4. 建模階段(Modeling):可以選擇和應用不同的模型技術,模型參數被調整到最佳的數值。有些技術在數據格式上有特殊要求,因此需要經常跳回到數據準備階段;
5. 評估階段(Evaluation):經過建模階段后,已建立了一個高質量的決策模型,但在開始最后部署模型之前,重要的事情是徹底地評估模型,檢查構造模型的步驟,確保模型可以完成業務目標。這個階段的關鍵目的是確定是否有重要業務問題沒有被充分的考慮,評估模型是否有達到最初設定的目標;
6. 部署階段(Deploying):根據用戶需求,實現一個重復的、復雜的數據挖掘過程。
最外面這一圈表示數據挖掘自身的循環本質,每一個解決方案部署之后代表另一個數據挖掘的過程也已經開始了,需要在運行過程中不斷迭代、更新模型。
CRISP-DM是一個偉大的框架,它可以讓項目組聚焦于挖掘真正的商業價值上。CRISP-DM路程已經存在有很長時間了,許多使用CRISP-DM流程的項目常常會走捷徑,這些捷徑中的有一些是有意義的,但捷徑往往會導致項目使用不完整的流程,如圖2所示。
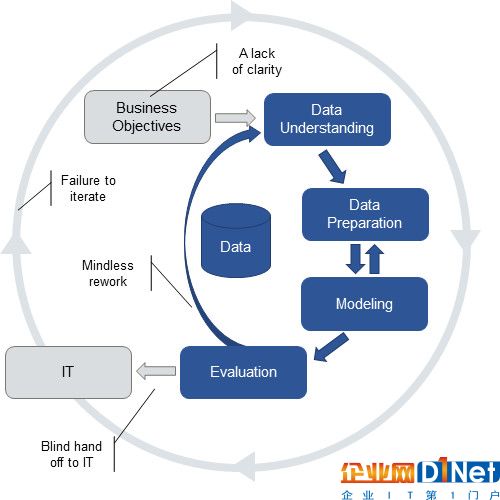
圖2 典型的不完整CRISP-DM
這種不完整的CRISP-DM流程存在四個問題,具體包括:
1. 業務目標不清晰:
不能一開始就陷入細節,應該真正去了解業務問題以及明確一個模型可以發揮什么作用,確定項目團隊的業務目標和提出衡量項目成功的指標。“理解”了業務目標,團隊想把工作負擔最小化,就跳入項目的最有趣的部分--分析數據,但這樣做只產出有趣的模型,而不能滿足真正的商業需要。
2. 盲目地返工:
一些分析團隊只用分析術語來評估他們的模型,認為如果模型只要做到可預測,那么它就是一個好的模型。大多數人通常可以意識到模型是有問題的,就會嘗試檢查他們的模型是否符合業務目標。但如果缺乏對商業問題的充分認識,這樣的檢查往往是非常困難的。如果他們開發的模型不符合業務需求,此時團隊幾乎沒得選擇,此時大多數人是在嘗試找到新數據或新的建模技術,而不是與他們的業務合作伙伴一起重新評估業務問題。
3. 盲目地部署:
一些分析團隊根本不考慮他們模型的部署和操作的易用性。做得好些的團隊可以認識到他們構建的模型必將處理實時數據,數據通常存儲在數據庫中,或嵌在式操作系統中。即使是這樣的團隊通常也沒有參與到部署工作中,不清楚模型是如何部署的,并不把部署當做分析工作的一部分,結果就是模型直接丟給IT團隊去部署,模型是否容易部署、以及在生產環境是否可用都是別人的問題。這增加了模型部署的時間和成本,并產生了大量從未對業務產生影響模型。
4. 無法形成迭代:
分析專家了解模型的生命周期,為了保證模型的可用性,需要對模型保持更新。他們知道隨著商業環境變化,模型的價值會改變,驅動模型的數據模式可能會改變。但他們認為這是另一個時間點的問題。由于他們缺少對業務問題的足夠認識,往往難以確定如何評估模型的表現,相比模型建立階段,他們在模型迭代、修改上的投入更少。畢竟解決另一個新問題更有趣。這使得老的模型不受監控和保護,從而破壞了模型的長期價值。
以上任一問題都可能使構建出來的模型毫無商業價值,真正需要利用分析的組織,特別是數據挖掘、預測和機器學習等更高級的分析,必須避免這些問題。
解決這些問題需要明確、清晰地關注決策,圍繞著決策展開,包括需要改善的決策方法,改善意味著什么,做能實際改善決策的分析模型,設計可以輔助決策的系統,還需要明確在怎樣的外部環境下需要重新評估模型。雷鋒網將關注Taylo后續關于數據挖掘的文章,敬請期待。








 京公網安備 11010502049343號
京公網安備 11010502049343號