


試想一下:Tesla自動駕駛、華爾街自動交易算法、智能家居、能夠實現日內閃電般運抵的交通網絡和紐約市警察局發布的開放數據,它們都有哪些共同點?
一方面,它們預示著我們的世界正以曲速般變化,我們捕獲和解析的數據比以往更多,速度比以往更快。
但是,如果仔細觀察你會發現,這些應用程序都需要一種特殊的數據:
自動駕駛汽車持續收集所處環境中的變化數據自動交易算法持續收集市場的變化數據智能家居系統持續監控房屋內的變化,調整溫度,識別侵入者,對于使用者總是有求必應(“Alexa,播放一些輕松的音樂”)。零售行業精確高效地監控資產運轉狀況,使得日內運抵的成本足夠低廉且能夠為絕大多數人所使用。紐約警察局通過跟蹤車輛來更好地履行其職責(例如,分析911報警電話的響應次數)這些應用程序均依賴一種衡量事物隨時間的變化的數據形式,這里的時間不只是一個度量標準,而是一個坐標的主坐標軸。
這就是時間序列數據,它漸漸在我們的世界中發揮更大的作用。
軟件開發人員的使用模式早已反映了這一點,在過去的24個月中,時間序列數據庫(TSDB)已經成為增長最快的類別:
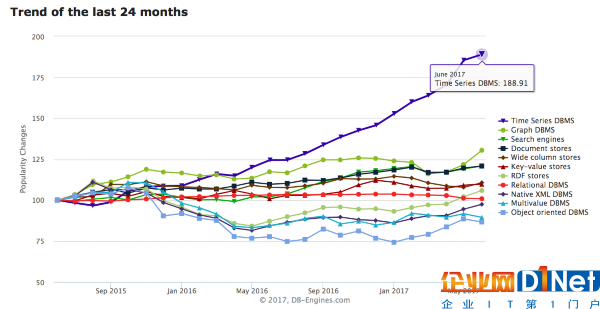
數據來源:DB-Engines,2017年6月. https://db-engines.com/en/ranking_categories
我們開發了一款新的開源時間序列數據庫,經常有人問TSDB的趨勢如何,他們通常會問以下三個問題:
時間序列數據是什么?何時需要使用時間序列數據庫?使用(或不使用)TimescaleDB的理由是什么?起初,這些材料是為我們在4月份開源數據庫大會Percona Live中的演講而準備的,現在我們將其發布在本文中,并在深思熟慮后嘗試具體回答一下這些問題,并盡可能分享給更多的人。
那么我們開始吧。
時間序列數據是什么?
有些人將“時間序列數據”視為按時間順序存儲的一連串隨時間推移測量相同事物的數據點,這樣解釋沒錯,但只描述了淺層信息。
其他人可能會認為是一連串與時間戳配對的數值,這些數值由一個名稱和一組歸類維度(或稱“標簽”)所定義。這也許是一種為時間序列數據建模的方式,卻不是數據自身的定義。
我們繼續深入。
以下是一個基礎示例,設想這個傳感器從三個環境中收集數據:分別是城市、農場和工廠。在這里,每一個數據源定期發送新的讀數,創建一系列隨時間推移收集到的測量結果。
接下來是另一個示例,這是一份紐約市的實際數據,這些數據展示了2016年前幾秒出租車的乘坐情況。正如你所見,每一行都是在特定時間收集的“測量結果”。

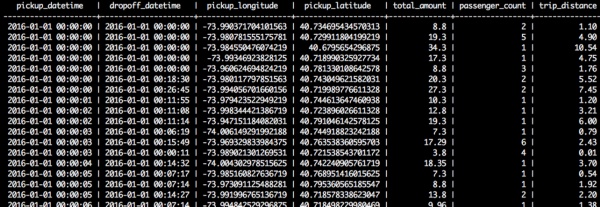
2016年前幾秒紐約出租車乘坐數據。數據源:http://www.nyc.gov/html/tlc/html/about/trip_record_data.shtml
還有許多其他類型的時間序列數據,例如:DevOps監控數據、移動/Web應用程序事件流、工業機器數據、科學測量結果。
這些數據集主要有以下三個共同點:
抵達的數據幾乎總是作為新條目被記錄數據通常按照時間順序抵達時間是一個主坐標軸(既可以是規則的時間間隔,也可以是不規則的)換句話說,時間序列數據的處理過程通常是伴隨數據的抵達而進行的。雖然在事后需要糾正錯誤的數據,或處理延遲數據或無序數據,但這些都是例外情況,不屬于標準范疇。
你可能會問:這與在數據庫中添加字段有何區別?
那么,這取決于:你的數據集如何跟蹤變化?是更新當前條目,還是插入新的條目?
當你為sensor_x收集新讀數時,是覆蓋以往的讀數,還是在新的一行創建全新的讀數?盡管這兩種方法都能為你提供系統的當前狀態,但只有第二種方法才能跟蹤系統的所有狀態。
簡而言之:時間序列數據集跟蹤整個系統的改動并不斷插入新數據,而不是更新原有數據。
時間序列數據之所以如此強大,是因為將系統的每個變化都記錄為新的一行,從而可以去衡量變化:分析過去的變化,監測現在的變化,以及預測未來將如何變化。
因此,我們這樣定義時間序列數據:統一表示系統、過程或行為隨時間變化的數據。
這不僅是一個學術上的區別:通過圍繞“變化”的定義,我們可以開始找出當下我們應該收集卻沒有收集的時間序列數據集。
事實上,我們發現人們早已坐擁時間序列數據,但他們卻沒意識到這一點。
假設你正在維護一個Web應用程序,每次用戶登錄時,你可以在“users”表的某行中更新用戶的“last_login”時間戳,但是如果將每次登錄作為一個單獨的事件處理,并隨著時間推移收集這些數據又會有怎樣的效果?屆時你可以:跟蹤歷史登錄活動,了解隨時間推移用戶使用的增減情況,根據訪問App的頻率或更多指標區分用戶。
這個示例說明了一個關鍵點:通過保留數據固有的時間序列性質,我們能夠保留有關數據隨時間變化的有用信息。
(事實上,這個示例還說明了另一點:事件數據同樣也是時間序列數據)
當然,按照這種方式存儲數據會帶來一個明顯的問題:最終你會以相當快的速度得到大量的數據,時間序列數據很快會堆積起來。
數據量太大會給記錄和查詢操作帶來嚴重的性能問題
這也是人們正逐漸轉向時間序列數據庫的原因。
我為什么需要一個時間序列數據庫?
你可能會問:為什么我不能用一個“常規”(也就是非時間序列)的數據庫?
事實上你可以使用非時間序列數據庫,也確實有人這樣做:
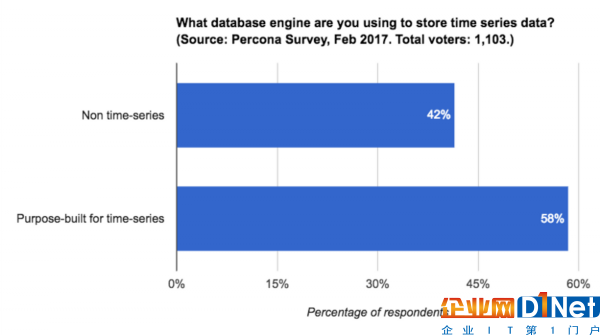
數據源:Percona,2017年2月. https://www.percona.com/blog/2017/02/10/percona-blog-poll-database-engine-using-store-time-series-data/
那么為什么大部分調查對象使用時間序列數據庫而不是常規數據庫呢?為什么TSDB如今成為增長最快的數據庫?
有兩個原因:(1)規模(2)可用性
規模:時間序列數據累計速度非常快。(例如,一輛聯網汽車每小時能收集25GB數據。)常規數據庫在設計之初并非處理這種規模的數據,關系型數據庫處理大數據集的效果非常糟糕;NoSQ數據庫L可以很好地處理規模數據,但是讓然比不上一個針對時間序列數據微調過的數據庫。相比之下,時間序列數據庫(可以基于關系型數據庫或NoSQL數據庫)將時間視作一等公民,通過提高效率來處理這種大規模數據,并帶來性能的提升,包括:更高的容納率(Ingest Rates)、更快的大規模查詢(盡管有一些比其他數據庫支持更多的查詢)以及更好的數據壓縮。
可用性:TSDB通常還包括一些共通的對時間序列數據分析的功能和操作:數據保留策略、連續查詢、靈活的時間聚合等。即使當下不考慮規模(例如,您剛開始收集數據),這些功能仍可提供更好的用戶體驗,使你的生活更輕松。
這就是為什么開發人員越來越多地采用時間序列數據庫,并將它們用于各種使用場景的原因:
監控軟件系統: 虛擬機、容器、服務、應用監控物理系統: 設備、機器、接入的設備、環境、我們的房屋、我們的身體資產跟蹤應用: 汽車、卡車、物理容器、運貨托盤(Pallets)金融交易系統: 傳統證券、新興的加密數字貨幣事件應用程序: 跟蹤用戶、客戶的交互數據商業智能工具: 跟蹤關鍵指標和業務的總體健康情況更多場景但即使如此,你仍需選擇最適合你的數據模型和寫入和讀取模式的時間序列數據庫。
使用(或不使用)TimescaleDB的理由是什么?
如果你確實需要一個時間序列數據庫,已經有相當多的現成選擇。你可能對某一個感到滿意,但我們并未滿足。
為什么我們對最先進的仍不滿足?因為我們希望在大規模數據上應用SQL的全部能力,現有的數據庫無一具備這項能力。
具體來說,我們發現現有的時間序列數據庫:
在我們的許多查詢試驗中表現不佳(解讀:高延遲)甚至都不支持許多其他的查詢(因數據庫而異)要求我們學習一門新的查詢語言(解讀:不是SQL語言)不能與我們現有的大多數工具合用(解讀:糟糕的兼容性)要求我們將數據分為兩個數據庫:一個“常規”的關系數據庫,還有一個時間序列數據庫(解讀:操作與開發過程極為頭痛)所以我們打造了TimescaleDB,因為我們需要它。后來其他人也想使用這個數據庫,所以今年早些時候我們根據基于Apache 2的許可開源。

你何時應該考慮使用TimescaleDB?如果你想:
一個普通的SQL接口,用于時間序列數據,甚至是大規模數據操作簡單:一個數據庫同時存放關系型數據和時間序列數據連接(JOINs) 查詢時跨關系型數據和時間序列數據連接PostgreSQL!(Timescale的行為表現就像PostgreSQL一樣)查詢性能,尤其是對于廣泛而多樣化的查詢(通過強大的二級索引支持)原生支持地理空間數據 (兼容PostGIS)第三方工具:Timescale支持任何使用SQL的工具,包括像Tableau這樣的BI工具同樣,如果滿足下列條件中的任意一條,你可能不太希望使用TimescaleDB:
如果你只有簡單的查詢模式(例如,鍵值查找、一維匯總)。其他數據庫針對此類查詢的優化更徹底。如果你有稀疏數據或完全非結構化的數據 雖然TimescaleDB支持結構化和半結構化數據(包括JSON),但如果你的數據一般是稀疏或完全非結構化的,那么其他數據庫中還有更好的選擇。但是,如果TimescaleDB看起來很有趣或有用,我們歡迎你進一步了解它,下載并安裝,嘗試一下。(亦可訪問項目的Github,歡迎Star。)
延展思考:是否所有數據都是時間序列數據?
我們先回歸時間序列數據話題本身。
過去十多年以來,我們生活在“大數據”時代,收集了大量有關我們所處世界的信息,并運用計算資源來理解它。盡管這個時代始于適度計算(Modest Computing)技術,但由于存在摩爾定律(Moore’s Law)、克拉底定律(Kryder's Law)、云計算以及整個“大數據”技術產業這些主要的宏觀趨勢,我們捕獲、存儲和分析數據的能力已經以指數級的速度得到提高。
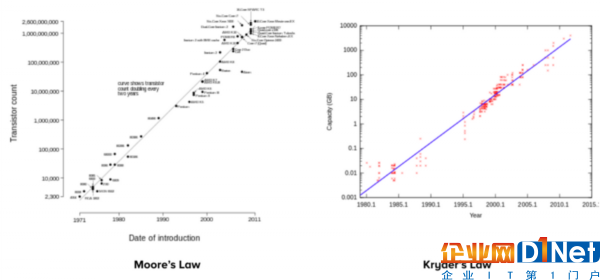
根據摩爾定律,計算能力(晶體管密度)每18個月翻一番,而克拉底定律則假定存儲容量每12個月翻一番。
現在我們不再滿足于觀察世界狀態,想要的更多,我們想度量世界隨亞秒級別時間推移的變化。我們的“大數據”數據集現在正被另一種數據超越,這些數據在很大程度上依賴時間來保存正在發生的變化的信息。
但是否所有數據一開始都是時間序列數據? 回顧我們早期的Web應用示例:我們其實已坐擁時間序列數據,只是當時沒有意識到。
或者想一下任何“常規”數據集,例如主流零售銀行活期賬戶和余額、軟件項目的源代碼或這篇博客文章的文本。
通常我們選擇存儲系統的最新狀態。但是如果我們反過來存儲每個變化,并在查詢時計算最新的狀態又會如何?“常規”數據集是不是很像相應時間序列數據集的頂層視圖,只是考慮到性能原因先被緩存了起來?銀行是不是有交易賬本?(區塊鏈是不是分布式、不可修改的時間序列記錄?)一個軟件項目是不是要有版本控制(例如,Git Commit?)這篇博客文章是不是有修訂歷史?(撤銷、重做。)
換句話說:是否所有數據集都有日志?
我們注意到許多應用程序可能永遠不需要時間序列數據(而且使用“當前狀態視圖”效果更好)。但是隨著技術進步的指數曲線的不斷向前發展,似乎這些“當前狀態視圖”變得不是很必要了。只有以時間序列形式存儲更多的數據,我們才能夠更好地了解它。
是否所有數據都是時間序列數據?我們尚未找到一個很好的范例,如果你有幸找到,我們愿洗耳恭聽。
無論如何,有一件事情是清楚的:時間序列數據已經出現在我們周圍,現在是時候將其投入使用。
感謝閱讀我們的博文,如果你覺得這篇文章有幫助并推薦或分享,我們在此表示感謝。
如果您有任何后續問題或意見,可以通過email或Twitter發送給我們。
如果您想了解有關TimescaleDB的更多信息,請查看我們的GitHub,如需幫助請聯系我們。
查看英文原文:https://blog.timescale.com/what-the-heck-is-time-series-data-and-why-do-i-need-a-time-series-database-dcf3b1b18563








 京公網安備 11010502049343號
京公網安備 11010502049343號