









“天地玄黃,宇宙洪荒”,在二十世紀末開始進入信息化時代,人類慢慢地從線下的面對面交流轉移到了線上進行簡單的Email信息交互,這是Web1.0信息互聯網,在MSN、QQ等PC端軟件出現后,人們開始通過文字、語音、視頻等方式在網上進行社交,隨著移動互聯網的高速發展,智能手機的出現,社交、購物、遠程教育等活動可以隨時隨地進行,我們全面進入了Web2.0社交互聯網。
而如今,人們在互聯網上進行著的各項活動(網頁瀏覽行為、APP使用行為等)信息匯聚成的一片數據的汪洋大海,企業再也無法用以前的小型數據庫、小規模計算中心來處理這些龐大的數據了,我們今天一天產生的數據就足以睥睨過去20世紀的所有書籍轉為電子文字的大小總和。這些互聯網上的活動數據,人們在進行信息“饕餮大餐”后留下的“面包屑”,就如同天上璀璨的繁星,數不勝數。
概要
就是在這樣的背景下,大數據孕育而生,在(Google、高校、開源社區等)多年的耕耘下,眾多技術百花齊放,到現在已經是百家爭鳴的興盛狀況。那么,無論是剛入大學校園的莘莘學子,還是初入職場的技術小白,亦或者是在傳統軟件里的“老”程序員等,他們在大數據的門前熙來攘往,很多人徘徊踟躕又不得入。
這是作者為什么寫本文的原因,這篇文章將會提供你大數據的學習指南,就像圣經里描述的一樣,人們想要登上天堂,于是齊心協力開始搭建巴別塔,大數據的最終目標其實還遠遠尚未達到,我們也是在進行時,這座巴別塔并不一定適合任何人,你也可以按自身理解另辟蹊徑。本文能夠給你的,是一份大綱指南,每一個細節單元的內容對應著非常多的教科書,希望你能夠在大數據領域里,無論是學術還是工作都能有所突破。
每一個想要學習大數據的人問我的問題常常是,“我應該從hadoop,還是分布式計算、Flink、Kafka、NoSQL還是Spark開始學起?”我往往這樣回答: “這取決于你到底想做什么”。當然,要回答這個問題的前提是,你要有個總體上的了解。所以,讓我們通過三個問題(市場、自身、流程三方面)的解答,再一步步了解大數據的整條學習路徑。
一、在大數據行業需要什么人才?
我們首先需要解答的問題是:“在大數據行業需要什么人才?”,這是我們的直接需求,先了解市場的需求,再結合自身的情況,才能夠準確地做出選擇。在大數據行業需要非常多領域的人才,但總的來說可以概括為以下兩類:
大數據工程
大數據分析
這兩個領域相互依賴又區分明顯,在解決一個實際問題的時候,我們往往先需要一個大數據工程方面的人才先搭建起大規模數據的系統,收集到了數據后布置計算平臺,然后就需要大數據分析方面的專家來對數據在計算平臺上進行分析和研究,而這樣的團隊我們稱之為數據科學團隊,當然,也有十分厲害的人,能夠兩方面都精通,我們稱之為數據科學家,也稱為“獨角獸”(在企業里,獨角獸公司指的是尚未上市,估值超過十億美金的公司,這里用來比喻數據科學家的珍貴),想要成為“獨角獸”的話,需要付出遠超常人的艱辛,還需要有十足的天賦,如果沒有,往往只能成為大數據的通才,空有口才,卻無實干能力。
大數據工程解決的是關于海量數據(起碼在T級別以上)的設計、部署、存儲和計算需求等方面的問題。在當今,大數據工程師要設計和部署的系統,往往都是與消費者和內部工作人員直接使用的應用程序。
而大數據分析則是基于在處理使用由大數據工程師設計的系統上的大量數據上的相關概念,大數據分析涉及分析趨勢,模式和開發各種分類和預測系統。
因此,簡而言之,大數據分析涉及大數據的高級計算(統計、建模預測等),而大數據工程涉及系統的設計、部署和實施。
二、你的背景和興趣如何,你適合什么崗位?
現在,我們已經知道了工業界里需要什么樣的大數據人才,那么你究竟是怎樣的背景,你究竟適合從事哪一方向的崗位呢?這需要結合你的實際情況進行分析。總的來說,這需要先了解你的教育背景和行業經驗:
一、教育背景(這包括個人興趣和自學功底,不一定指你的大學專業)
1.計算機科學相關
2.數學相關
二、行業經驗
1.新手小白(在讀生或者剛剛工作)
2.分析相關
3.計算機工程相關
這樣,確定了歸屬,你才能找到你大數據行業學習路徑的前提,當你清晰地了解自己的背景后,請選擇你想要在大數據方面作為第一個的起點領域。
大數據工程領域
如果你有嫻熟的編程能力和理解計算機互聯網交互原理(基礎),而不對數學和統計學感興趣,你這種情況下你應該先進入大數據工程領域。
大數據分析領域
如果你擅長編程,并且你的教育背景和興趣于數學和統計學相關。你先應該進入大數據分析領域。確定從哪里開始后,我們先結合現實案例來描述下大數據是如何解決一個現實問題的。
三、大數據工作完整初體驗是怎么樣的?
如果你不對整體的流程有所了解,你只是盲人摸象,只是在黑暗中摸索著大數據這只巨大無比的原始象。為了確定工作流程,你首先必須了解常見的大數據術語。那么讓我們來看一下大數據工作實際上是什么意思?首先,我們要確定需求,確定需求就必須用到大數據的專業術語,我們先簡單過一下確定一個需求所會用的術語。
大數據術語(部分)
大數據項目有兩個主要方面 - 數據要求和處理要求。
一、數據要求術語
結構:如果數據是按照預定義的數據格式排列存儲(即具有表結構),則稱為結構化數據。如果它存儲在文件中沒有固定的模式,則稱為非結構化數據,一般數據分為這兩種結構,當然,像JSON這樣的則稱為半結構化數據。
大小:系統所處理的數據量評估,例如說大概一天會有100M以內的數據需要系統處理,那么則評估為S,往上以此增加為M,L,XL,XXL和最后的實時流處理等。
Sink吞吐量:定義系統可以接收數據的速率,低速率的稱為L(如同2G網絡,中速的為M(如同3G)高速的稱為H(如同4G或者以上)。
源吞吐量:定義可以將數據更新和轉換到系統的速率,如同Sink吞吐量一樣分為三個等級。
二、處理要求術語
查詢時間:系統執行查詢所需的時間,其實等同于查詢效率,也跟吞吐量一樣分為H/M/L三種等級。
處理時間:處理數據所需的時間,分為H/M/L。
精度:數據處理的準確性,有些數據需要非常精確,有些只要大概的一個統計值來替代即可,則分為精確/近似。
那么如何用這些術語來如何描述需求與設計大數據系統架構呢?
各種現實情境下有各其問題各自對應的具體要求,大數據里,往往需要結合以上兩個方面的要求來進行分析,才能最終確定拍板定案。
假設我們有一下這個場景: 我們公司的需要制作一個能夠通過從客戶數據,潛在客戶數據,呼叫中心數據,銷售數據,產品數據,博客等多個數據源創建的數據湖來設計分析公司銷售業績的系統。
這只是我所想出的一個解決方案,不排除有更好的解決方案。那么,大數據工程師如何解決這個問題呢?牢記一點,大數據系統不僅要設計成能夠無縫集成其他來自各種源的數據,使其一直有效可用,還必須設計成一種能夠對數據的進行分析、和使用的平臺,能夠簡易快速地讓大數據分析師在上面開發應用程序(在這種情況下也為智能儀表板)。
因此我們的最終目標是:
通過集成來自多個來源的數據創建數據湖。
定期自動更新數據(在這種情況下可能是每周)
數據可用性分析(全天候,甚至每天)
架構,便于訪問和無縫部署分析儀表板。
現在我們知道我們的最終目標是什么,讓我們嘗試以術語的專業方式來制定要求。
一、數據相關要求
結構:大部分數據是結構化的,并具有定義的數據模型。但數據源,如網絡日志,客戶互動/呼叫中心數據,銷售目錄中的圖像數據,產品廣告數據。圖像和多媒體廣告數據的可用性和要求可能取決于公司。 結論:結構化與非結構化數據都需要兼顧。
大小:L或XL(選擇Hadoop)
Sink吞吐量:H
質量:M(Hadoop&Kafka)
完整性:不完整
二、處理相關要求
查詢時間:M至L
處理時間:M至L
精度:準確
同時隨著多個數據源的集成,重要的是注意到不同的數據將以不同的速率進入系統。例如,網絡日志將以高級別的粒度(實時流的形式)進入。因此,綜合上述對系統要求的分析,我們可以推薦以下大數據架構設計。
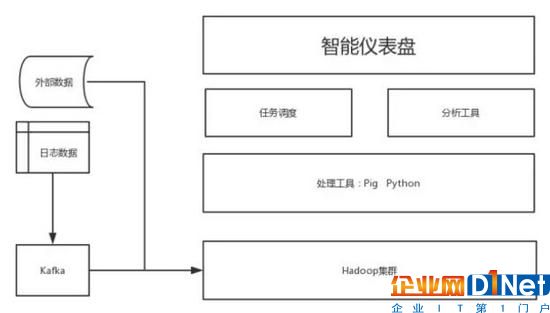
這樣,我們就完成了一次完整的大數據系統設計體驗,關于系統實現或者數據分析的技術細節可以通過下面學習路徑具體習得。
大數據學習路徑
在這個下面樹形圖的幫助下,你就可以開始學習大數據的旅程。現在,你已經了解大數據行業,大數據從業人員的不同角色和要求,也知道了這身的興趣出發點,我們希望你先從自己的出發點開始,到達Data Scientist節點的時候,能夠再學習其他路徑的知識。
(點擊放大圖像)
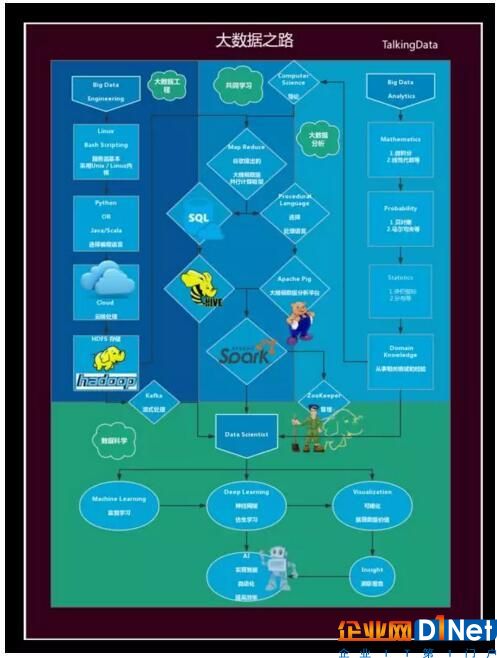
共分為四條學習路徑:
大數據工程;
大數據分析;
共同學習;
數據科學。總體要點
一、大數據工程和大數據分析路徑是起始路徑,共同學習和數據科學路徑的前提依賴于前面兩者。
二、任何想要部署應用程序的工程師必須掌握的基本概念之一是Bash腳本,你必須非常了解Linux和bash腳本,這是處理大數據的基本要求。大部分大數據技術核心都是用Java或Scala語言寫的。但是別擔心,如果你不想用這些語言寫代碼,那么你可以選擇Python或者R,因為大部分的大數據技術現在都支持Python和R。因此,你可以從上述任何一種語言開始。我建議選擇Python或Java。
三、你需要熟悉在云端服務器上工作,這是因為如果你沒有在云端處理過大數據,沒有人會重視你。可以嘗試使用AWS、或阿里云等提供商的小型數據集,大多數都有一個小型的免費服務版本讓你練習。
四、你需要了解一個分布式文件系統。最流行的DFS就是Hadoop分布式文件系統。在這個階段你還可以學習一些你領域相關的NoSQL數據庫。下圖可以幫助你選擇一個NoSQL數據庫,以便根據你感興趣的領域進行學習。
五、到目前為止的路徑是每個大數據工程師必須知道的基礎知識。現在,你決定是否要處理數據流或存儲著的大量數據,這是用于定義大數據(Volume,Velocity,Variety和Veracity)的四個維度中兩個之間的選擇。
六、假設你決定使用數據流來開發實時或近實時分析系統。那么你應該采取Kafka路徑,或者你采取Map reduce路徑,你就需要按照你創建的路徑學習。請注意,在MapReduce路徑中,不需要Pig和Hive都學習,只學習其中之一就足夠了。
學習流程
先從起始路徑開始,用深度優先策略遍歷。
到下一個節點前先停止,檢查文章最后學習資源附錄中給出的資源。
如果你充分了解并且在使用該技術方面有相當的信心,那么請轉到下一個節點。
在每個節點嘗試完成至少3個編程問題。
轉入下一個節點學習。
到達路徑尾端節點。
從另外一條路徑再開始。
別讓最后一步(第七步)擋住了你!說實話,沒有應用程序能夠同時以流處理或慢速延遲處理數據。因此,你在工程技術上需要成為架構的高手。另外,請注意,這不是學習大數據技術的唯一方法。你可以隨時創建自己的路徑。但這是一個可以被任何人使用的路徑。如果想進入大數據分析領域,也可以遵循相同的路徑。對于能夠處理大數據的數據科學家,需要在下面部分的樹中有機器學習、深度學習、可視乎研究等,先要將重點放在機器學習上。
我希望你喜歡閱讀這篇文章。借助這種學習途徑,你能夠踏上在大數據行業的旅程。我已經涵蓋了大部分要求工作的主要概念。如果有任何疑問或疑問,請隨時提問。
學習資源附錄(推薦Google)
Bash Scripting
Bash Guide for Beginners by Machtelt Garrels
Python
Python for Everybody Specialization by Coursera Learning Path for Data Science in Python for Coursera
Java
Introduction to Programming with Java 1 : Starting to Code with Java by Udemy
Intermediate and Advanced Java Programming by Udemy
Introduction to Programming with Java 2 by Udemy Object Oriented Java Programming: Data Structures and Beyond Specialization by Coursera
Cloud
Big Data Technology Fundamentals by Amazon Web Services
Big Data on AWS by Amazon Web Services
HDFS
Big Data and Hadoop Essentials by Udemy
Big Data Fundamentals by Big Data University
Hadoop Starter Kit by Udemy
Apache Hadoop Documentation
Book –Hadoop Cluster Deployment
Apache Zookeeper
Apache Zookeeper Documentation
Book – Zookeeper
Apache Kafka
The complete Apache Kafka course for beginners by Udemy
Learn Apache Kafka Basics and Advanced topic by Udemy
Apache Kafka Documentation
Book – Learning Apache Kafka
SQL
Managing Big Data with MySQL by Coursera
SQLCourse by SQLcourse.com
Beginner’s Guide to PostgreSQL by Udemy
High-Performance MySQL
Hive
Accessing Hadoop Data using Hive by Big Data University
Learning Apache Hadoop Ecosystem Hive by Udemy
Apache Hive Documentation
Programming Hive
Pig
Apache Pig 101 by Big Data University
Programming Hadoop with Apache Pig by Udemy
Apache Pig Documentation
Book- Programming Pig
Apache Storm
Real-time analytics with Apache Storm by Udacity
Apache Storm Documentation
Apache Kinesis
Apache Kinesis Documentation
Amazon Kinesis Streams Developer Resources by Amazon Web Services
Apache Spark
Data Science and Engineering with Apache by edx
Apache Spark Documentation
Book – Learning Spark
Apache Spark Streaming
Apache Spark Streaming Documentation
本文借鑒參考了 saurabh 的Big Data Learning Path for all Engineers and Data Scientists out there
作者介紹
葉杰生,TalkingData數據科學組,主要職責是負責挖掘與處理TalkingData的地理位置數據以及開發相關位置服務,后期與數據管理組和數據收集組同事聯合開發了WI-FI采集器-來來,熟悉掌握scala編程語言、spark、hadoop、jenkins、zepplin等大數據處理相關開源工具,熟悉機器學習相關算法理論,關注大數據、人工智能以及深度學習等領域,目前轉入總部6負責AI、IOT相關研究,探索數據到智能的可行方案。
















 京公網安備 11010502049343號
京公網安備 11010502049343號