


Elastic今日在其官方博客,發布了最新版本的Elastic Stack 5.4.0 Beta,其中最重要的新特性是對機器學習的支持。
機器學習正在滲透到各行各業,搜索領域也不例外。Elastic今天發布的機器學習新特性,并非一蹴而就,而是源于去年的一樁收購案——2016年9月15日,Elastic宣布收購Perlert。Perlert是一家創立于2008年的用戶行為分析技術提供商,在無監督機器學習技術方面積累了豐富的實踐經驗。Elastic在該文章中稱經過7個月的努力,成功把Perlert的無監督機器學習技術集成到Elastic Stack,并作為X-Pack的一員,在最新的5.4.0 Beta版本中發布。
博客全文:
我們很榮幸地在今天發布首個支持機器學習特性的Elastic Stack版本,該特性位于X-Pack中。加入Elastic就如登上宇宙飛船(譯者注:指2016年9月Perlert公司加入Elastic),經過7個月的努力工作,我們激動地宣布Perlert機器學習技術現已全部集成到Elastic Stack,并真誠地期待用戶的反饋意見。
注:也別太過激動,請留意該功能尚處于5.4.0版本的Beta階段。
關于機器學習
我們的目標在于,讓用戶通過工具從自己Elasticsearch數據中獲取價值和洞察力,同時我們認為機器學習對于Elasticsearch中的搜索和分析能力來說是一個很自然的延伸。比如你可以在Elasticsearch的海量數據中實時查詢用戶“steve”的交易記錄,或者通過聚合和可視化功能來展示銷量top10的產品,或者交易量隨時間的變化趨勢。而現在,借助機器學習你能更進一步來分析,比如“有哪項服務的行為改變了嗎?”或者“我們的主機上有異常進程在運行嗎?”這些問題,要求使用機器學習技術所需的數據,來自動構建出主機或服務的行為模型。
但機器學習目前在軟件業是過熱概念之一,因為根本上來講,就是一系列用于數據驅動預測、決策支持以及建模的算法和方法。因此消除這些噪聲,來介紹下我們所做的具體事情顯得更為重要。
時間序列數據的異常檢測
今天發布的X-Pack機器學習特性,旨在通過無監督機器學習提供“時間序列數據異常檢測”的能力。
未來我們計劃增加更多的機器學習功能,但目前專注于,針對在Elasticsearch中存儲時間序列數據,比如日志文件、應用和性能指標數據、網絡流量或者金融/交易數據等的用戶,提供附加價值。
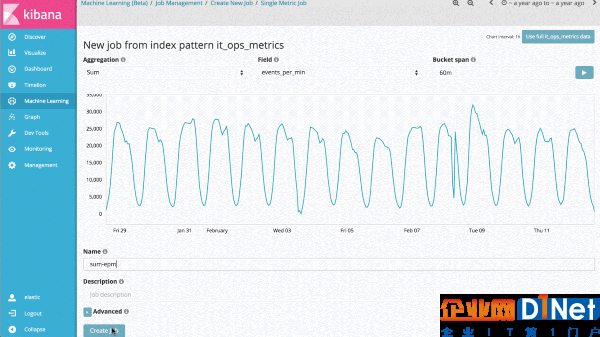
示例1——關鍵性能指標異常波動的自動告警
這項技術的最直接應用是,識別一個度量值或事件比率何時偏離了常規行為模式。比如,服務的響應時間是否顯著增加?或者預期的網站訪問用戶數是否與往日同一時段明顯不同?這類分析通常都會用到規則、閾值或簡單統計模型。遺憾的是,這些簡單方法對于實踐中的數據來說都很低效,因為它們往往依賴不合理的統計假設(比如高斯分布),所以并不適用于趨勢分析(長期或周期性的)或信號極易改變的情況。
因此,對于機器學習特性第一個可以切入的,就是單指標作業,由此可以了解該產品如何學習正常模式,以及如何識別單變量時間序列數據中的異常模式。如果所發現的異常是有意義的,就可以持續地實時運行該分析,并在異常發生時告警。
雖然這看起來只是一個比較簡單的應用案例,但產品背后卻有著大量的無監督機器學習算法和統計模型,因此對任意信號都有魯棒性和精確性。
為了在Elasticsearch集群中能更本地化地運行,我們對實現也做了優化,因此百萬級的事件可以在秒級完成分析。
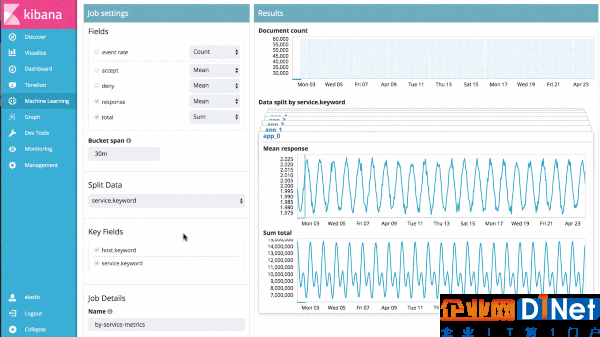
示例2——數千指標的自動化追蹤
機器學習產品能擴展到數十萬指標和日志文件,所以下一步就是同時分析多個指標;可能會是一個主機相關的多個指標、一個數據庫或應用的性能指標、或者多個主機的多個日志文件。這種情況下可以簡單地分區分析,并把結果聚合到一個透視窗口中用于展示整個系統的異常。
假設有一個大型應用服務的響應耗時數據,就能簡單地分析每個服務隨時間的響應耗時變化,并識別單個服務的異常行為,同時也能提供整個系統的異常視圖:
示例3——高級作業
最后,還有大量的更高級方式來使用該產品。比如,如果想查找與人群相比有異常行為的用戶、異常的DNS流量或者倫敦道路上的交通擁堵,高級作業提供了一種靈活的方式,來分析Elasticsearch中的任何時間序列數據。
與Elastic Stack集成
機器學習是作為X-Pack的一個特性發布的,這意味著安裝了X-Pack之后,就可以利用機器學習特性來實時分析Elasticsearch中的時間序列數據。Elasticsearch集群會自動化地分配和管理機器學習作業任務,基本上跟對待索引和分片一樣;這也就意味著,機器學習作業可以從節點故障中快速恢復。從性能的角度,緊密集成意味著數據從來無需離開集群,我們能依賴Elasticsearch聚合功能顯著地提升某些作業類型的性能。緊密集成的另一個好處是,可以從Kibana直接創建異常檢測作業并查看結果。
因為數據能現場分析而無需離開集群,所以相對于集成Elasticsearch數據到外部數據科學工具,這種方式有著明顯的性能和維護優勢。隨著我們在該領域開發的技術越來越多,這種架構的優勢將會愈加明顯。
了解最新版本Elastic Stack:https://www.elastic.co/cn/
查看英文原文:Introducing Machine Learning for the Elastic Stack
感謝杜小芳對本文的審校。








 京公網安備 11010502049343號
京公網安備 11010502049343號