


如今Apache Hadoop已成為大數據行業發展背后的驅動力。Hive和Pig等技術也經常被提到,但是他們都有什么功能,為什么會需要奇怪的名字(如Oozie,ZooKeeper、Flume)。
如今Apache Hadoop已成為大數據行業發展背后的驅動力。Hive和Pig等技術也經常被提到,但是他們都有什么功能,為什么會需要奇怪的名字(如Oozie,ZooKeeper、Flume)。
Hadoop帶來了廉價的處理大數據(大數據的數據容量通常是10-100GB或更多,同時數據種類多種多樣,包括結構化、非結構化等)的能力。但這與之前有什么不同?
現今企業數據倉庫和關系型數據庫擅長處理結構化數據,并且可以存儲大量的數據。但成本上有些昂貴。這種對數據的要求限制了可處理的數據種類,同時這種慣性所帶的缺點還影響到數據倉庫在面對海量異構數據時對于敏捷的探索。這通常意味著有價值的數據源在組織內從未被挖掘。這就是Hadoop與傳統數據處理方式最大的不同。
本文就重點探討了Hadoop系統的組成部分,并解釋各個組成部分的功能。
MapReduce——Hadoop的核心
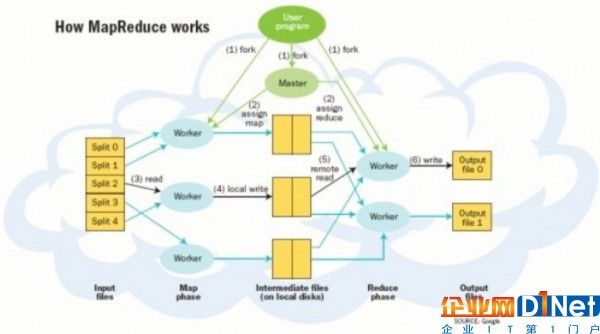
Google的網絡搜索引擎在得益于算法發揮作用的同時,MapReduce在后臺發揮了極大的作用。MapReduce框架成為當今大數據處理背后的最具影響力的“發動機”。除了Hadoop,你還會在MapReduce上發現MPP(Sybase IQ推出了列示數據庫)和NoSQL(如Vertica和MongoDB)。
MapReduce的重要創新是當處理一個大數據集查詢時會將其任務分解并在運行的多個節點中處理。當數據量很大時就無法在一臺服務器上解決問題,此時分布式計算優勢就體現出來。將這種技術與Linux服務器結合可獲得性價比極高的替代大規模計算陣列的方法。Yahoo在2006年看到了Hadoop未來的潛力,并邀請Hadoop創始人Doug Cutting著手發展Hadoop技術,在2008年Hadoop已經形成一定的規模。Hadoop項目再從初期發展的成熟的過程中同時吸納了一些其他的組件,以便進一步提高自身的易用性和功能。
HDFS和MapReduce
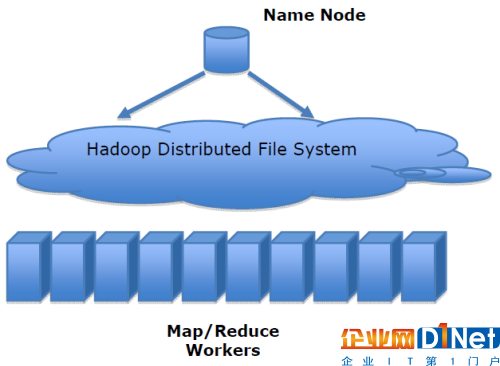
以上我們討論了MapReduce將任務分發到多個服務器上處理大數據的能力。而對于分布式計算,每個服務器必須具備對數據的訪問能力,這就是HDFS(Hadoop Distributed File System)所起到的作用。
HDFS與MapReduce的結合是強大的。在處理大數據的過程中,當Hadoop集群中的服務器出現錯誤時,整個計算過程并不會終止。同時HFDS可保障在整個集群中發生故障錯誤時的數據冗余。當計算完成時將結果寫入HFDS的一個節點之中。HDFS對存儲的數據格式并無苛刻的要求,數據可以是非結構化或其它類別。相反關系數據庫在存儲數據之前需要將數據結構化并定義架構。
開發人員編寫代碼責任是使數據有意義。Hadoop MapReduce級的編程利用Java APIs,并可手動加載數據文件到HDFS之中。
Pig和Hive

對于開發人員,直接使用Java APIs可能是乏味或容易出錯的,同時也限制了Java程序員在Hadoop上編程的運用靈活性。于是Hadoop提供了兩個解決方案,使得Hadoop編程變得更加容易。
Pig是一種編程語言,它簡化了Hadoop常見的工作任務。Pig可加載數據、表達轉換數據以及存儲最終結果。Pig內置的操作使得半結構化數據變得有意義(如日志文件)。同時Pig可擴展使用Java中添加的自定義數據類型并支持數據轉換。
Hive在Hadoop中扮演數據倉庫的角色。Hive添加數據的結構在HDFS(hive superimposes structure on data in HDFS),并允許使用類似于SQL語法進行數據查詢。與Pig一樣,Hive的核心功能是可擴展的。
Pig和Hive總是令人困惑的。Hive更適合于數據倉庫的任務,Hive主要用于靜態的結構以及需要經常分析的工作。Hive與SQL相似促使其成為Hadoop與其他BI工具結合的理想交集。Pig賦予開發人員在大數據集領域更多的靈活性,并允許開發簡潔的腳本用于轉換數據流以便嵌入到較大的應用程序。Pig相比Hive相對輕量,它主要的優勢是相比于直接使用Hadoop Java APIs可大幅削減代碼量。正因為如此,Pig仍然是吸引大量的軟件開發人員。
改善數據訪問:HBase、Sqoop以及Flume
Hadoop核心還是一套批處理系統,數據加載進HDFS、處理然后檢索。對于計算這或多或少有些倒退,但通常互動和隨機存取數據是有必要的。HBase作為面向列的數據庫運行在HDFS之上。HBase以Google BigTable為藍本。項目的目標就是快速在主機內數十億行數據中定位所需的數據并訪問它。HBase利用MapReduce來處理內部的海量數據。同時Hive和Pig都可以與HBase組合使用,Hive和Pig還為HBase提供了高層語言支持,使得在HBase上進行數據統計處理變的非常簡單。
但為了授權隨機存儲數據,HBase也做出了一些限制:例如Hive與HBase的性能比原生在HDFS之上的Hive要慢4-5倍。同時HBase大約可存儲PB級的數據,與之相比HDFS的容量限制達到30PB。HBase不適合用于ad-hoc分析,HBase更適合整合大數據作為大型應用的一部分,包括日志、計算以及時間序列數據。
獲取數據與輸出數據
Sqoop和Flume可改進數據的互操作性和其余部分。Sqoop功能主要是從關系數據庫導入數據到Hadoop,并可直接導入到HFDS或Hive。而Flume設計旨在直接將流數據或日志數據導入HDFS。
Hive具備的友好SQL查詢是與繁多數據庫的理想結合點,數據庫工具通過JDBC或ODBC數據庫驅動程序連接。
負責協調工作流程的ZooKeeper和Oozie
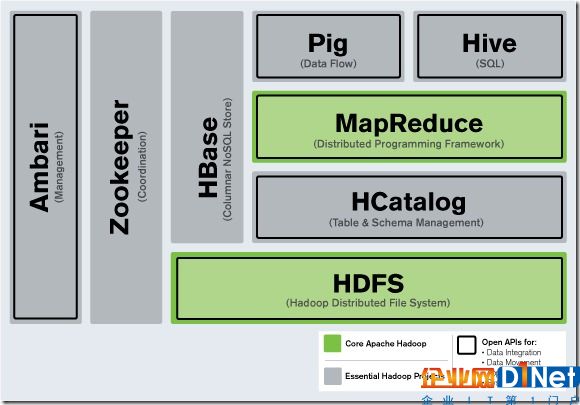
隨著越來越多的項目加入Hadoop大家庭并成為集群系統運作的一部分,大數據處理系統需要負責協調工作的的成員。隨著計算節點的增多,集群成員需要彼此同步并了解去哪里訪問服務和如何配置,ZooKeeper正是為此而生的。
而在Hadoop執行的任務有時候需要將多個Map/Reduce作業連接到一起,它們之間或許批次依賴。Oozie組件提供管理工作流程和依賴的功能,并無需開發人員編寫定制的解決方案。
Ambari是最新加入Hadoop的項目,Ambari項目旨在將監控和管理等核心功能加入Hadoop項目。Ambari可幫助系統管理員部署和配置Hadoop,升級集群以及監控服務。還可通過API集成與其他的系統管理工具。
Apache Whirr是一套運行于云服務的類庫(包括Hadoop),可提供高度的互補性。Whirr現今相對中立,當前支持Amazon EC2和Rackspace服務。
機器學習:Mahout

各類組織需求的不同導致相關的數據形形色色,對這些數據的分析也需要多樣化的方法。Mahout提供一些可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程序。Mahout包含許多實現,包括集群、分類、推薦過濾、頻繁子項挖掘。
使用Hadoop
通常情況下,Hadoop應用于分布式環境。就像之前Linux的狀況一樣,廠商集成和測試Apache Hadoop生態系統的組件,并添加自己的工具和管理功能。








 京公網安備 11010502049343號
京公網安備 11010502049343號