









數(shù)據(jù)分析師,無疑是數(shù)據(jù)時(shí)代最耀眼的職業(yè)之一,而統(tǒng)計(jì)學(xué),又是數(shù)據(jù)分析師必備的基礎(chǔ)知識(shí)。
知識(shí)點(diǎn)匯總:
1.集中趨勢(Central Tendency)
2.變異性(Variability)
3.歸一化(Standardizing)
4.正態(tài)分布(Normal Distributions)
5.抽樣分布(Sampling Distributions)
6.估計(jì)(Estimation)
7.假設(shè)檢驗(yàn)(Hypothesis testing)
8.T檢驗(yàn)(T-test)
一、集中趨勢(Central Tendency)
1.眾數(shù) 出現(xiàn)頻率最高的數(shù);
2.中位數(shù)
把樣本值排序,分布在最中間的值;
樣本總數(shù)為奇數(shù)時(shí),中位數(shù)為第(n+1)/2個(gè)值;
樣本總數(shù)為偶數(shù)時(shí),中位數(shù)是第n/2個(gè),第(n/2)+1個(gè)值的平均數(shù);
3.平均數(shù)
所有數(shù)的總和除以樣本數(shù)量;
小結(jié): 現(xiàn)在大家接觸最多的概念應(yīng)該是 平均數(shù),但有時(shí)候,平均數(shù)會(huì)因?yàn)槟承O值(Outlier)的出現(xiàn)收到很大影響;
舉個(gè)小例子,你們班有20人,大家收入差不多,19人都是5000左右,但是有1個(gè)同學(xué)創(chuàng)業(yè)成功了,年入1個(gè)億,這時(shí)候統(tǒng)計(jì)你們班同學(xué)收入的“平均數(shù)”就是500萬了,這也很好的解釋了,每年各地的平均收入數(shù)據(jù)出爐,小伙伴們直呼給祖國拖后腿了,那是因?yàn)榇蠹沂杖氡黄骄耍藭r(shí),“中位數(shù)”更能合理的反映真實(shí)的情況;
二、變異性(Variability)
1.四分位數(shù) 上面說到了“中位數(shù)”,把樣本分成了2部分,再找個(gè)這2部分各自的“中位數(shù)”,也就把樣本分為了4個(gè)部分,其中1/4處的值記為Q1,2/4處的值記為Q2,3/4處的值記為Q3
2.四分位距 IQR=Q3-Q1
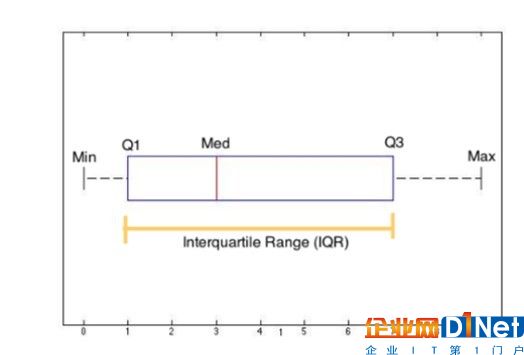
四分位數(shù).jpg
3.異常值(Outlier):
小于Q1-1.5(IQR)或者大于Q3+1.5(IQR);
對于異常值,我們在處理時(shí)需要剔除;
4.方差(Variance)
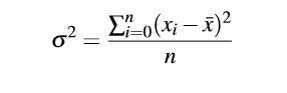
2方差variance.jpg
5.平方偏差(Standard Deviation) -方差的算術(shù)平方根
6.貝塞爾矯正:修正樣本方差 -問:為什么要用貝塞爾矯正?
實(shí)際在計(jì)算方差時(shí),分母要用n-1,而不是樣本數(shù)量n,原因如下

3貝塞爾矯正.jpg
三、歸一化(Standardizing)
1.標(biāo)準(zhǔn)分?jǐn)?shù)(Z-score)
一個(gè)給定分?jǐn)?shù) 距離 平均數(shù) 多少個(gè)標(biāo)準(zhǔn)差?
標(biāo)準(zhǔn)分?jǐn)?shù)是一種可以看出某分?jǐn)?shù)在分布中相對位置的方法。
標(biāo)準(zhǔn)分?jǐn)?shù)能夠真實(shí)的反映一個(gè)分?jǐn)?shù)距離平均數(shù)的相對標(biāo)準(zhǔn)距離。
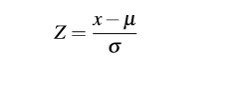
4歸一化standardizing.jpg
四、正態(tài)分布(Normal Distributions)
1.定義:隨機(jī)變量X服從一個(gè)數(shù)學(xué)期望為μ,方差為σ2的正態(tài)分布,記為N(μ,σ2)
隨機(jī)取一個(gè)樣本,有68.3%的概率位于距離均值μ有1個(gè)標(biāo)準(zhǔn)差σ內(nèi);
有95.4%的概率位于距離均值μ有2個(gè)標(biāo)準(zhǔn)差σ內(nèi);
有99.7%的概率位于距離均值μ有3個(gè)標(biāo)準(zhǔn)差σ內(nèi);

5正態(tài)分布normal distribution.jpg
2.Z-表格的查閱
五、抽樣分布(Sampling Distributions)
1.中心極限定理(Central Limit Theorem)
設(shè)從均值為μ,方差為σ2的任意一個(gè)總體中抽取樣本量為n的樣本,當(dāng)n充分大時(shí),樣本均值的抽樣分布近似服從均值為μ、方差為σ2/n的正態(tài)分布
2.抽樣分布(Sampling Distributions)
設(shè)總體共有N個(gè)元素,從中隨機(jī)抽取一個(gè)容量為n的樣本,在重置抽樣時(shí),共有N·n種抽法,即可以組成N·n不同的樣本,在不重復(fù)抽樣時(shí),共有N·n個(gè)可能的樣本。每一個(gè)樣本都可以計(jì)算出一個(gè)均值,這些所有可能的抽樣均值形成的分布就是樣本均值的分布。但現(xiàn)實(shí)中不可能將所有的樣本都抽取出來,因此,樣本均值的概率分布實(shí)際上是一種理論分布。數(shù)理統(tǒng)計(jì)學(xué)的相關(guān)定理已經(jīng)證明:在重置抽樣時(shí),樣本均值的方差為總體方差的1/n
視頻中的例子:
48盆MM豆,計(jì)算出每盆有幾個(gè)藍(lán)色的MM豆,48個(gè)數(shù)據(jù)構(gòu)成了總體樣本。然后隨機(jī)選擇五盆,計(jì)算五盆中含有藍(lán)色MM豆的平均數(shù),然后反復(fù)進(jìn)行了50次。這就是n為5的樣本均值抽樣。

6抽樣分布sampling distributions.jpg
六、估計(jì)(Estimation)
1. 誤差界限(Margin of error)
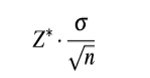
7誤差界限margin of error.jpg
2. 置信度(Confidence level)
We are some % sure the true population parameter falls within a specific range
我們有百分之多少確信總體中的值落在一個(gè)特定范圍內(nèi);
一般情況下,取95%的置信度就可以;
3. 置信區(qū)間(Confidence Interval)
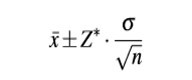
8置信區(qū)間.jpg
七、假設(shè)檢驗(yàn)(Hypothesis testing)

9假設(shè)檢驗(yàn)hypothesis testing.jpg
1. 問題:什么是顯著性水平?
顯著性水平是估計(jì)總體參數(shù)落在某一區(qū)間內(nèi),可能犯錯(cuò)誤的概率,也就是Type I Error
A Type II Error is when you fail to reject the null when it is actually false.

9假設(shè)檢驗(yàn)-零假設(shè)和對立假設(shè).jpg

9.3假設(shè)檢驗(yàn)-案例:雞.jpg
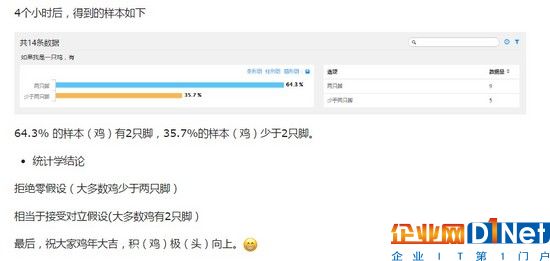
9.4假設(shè)檢驗(yàn)-案例:雞.jpg
作者:zhengweiyu 原文地址:https://discussions.youdaxue.com/t/topic/29031
2. 如何選擇備選檢驗(yàn)和零假設(shè)?
一個(gè)研究者想證明自己的研究結(jié)論是正確的,備擇假設(shè)的方向就要與想要證明其正確性的方向一致;
同時(shí)將研究者想收集證據(jù)證明其不正確的假設(shè)作為原假設(shè)H0
推薦閱讀:http://bbs.pinggu.org/thread-1071082-1-1.html
八、T檢驗(yàn)(T-test)
1. 主要用于樣本含量較小(例如n<30),總體標(biāo)準(zhǔn)差σ未知的正態(tài)分布。
流程如下:

10.t檢驗(yàn).jpg
是用t分布理論來推論差異發(fā)生的概率,從而比較兩個(gè)平均數(shù)的差異是否顯著;
一般檢驗(yàn)水準(zhǔn)α取0.05即可;
計(jì)算檢驗(yàn)統(tǒng)計(jì)量的方法根據(jù)樣本形式不同;
2. 獨(dú)立樣本T檢驗(yàn):
現(xiàn)在要分析男生和女生的身高是否相同兩者的主要區(qū)別在于數(shù)據(jù)的來源和要分析的問題。
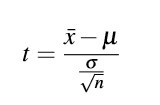
10.1 t檢驗(yàn).jpg
問題:為什么T檢驗(yàn)查表時(shí)候要n-1?
樣本均值替代總體均值損失了一個(gè)自由度
3. 配對樣本t檢驗(yàn):
分析人的早晨和晚上的身高是否不同,于是找來一撥人測他們早上和晚上的身高,這里每個(gè)人就有兩個(gè)值,這里出現(xiàn)了配對

10.3 t檢驗(yàn)-配對樣本.jpg
樣本誤差(Standard Error)

10.4 t檢驗(yàn)-樣本誤差.jpg
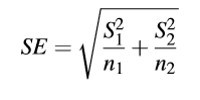
10.5 t檢驗(yàn)-樣本誤差2.jpg
4. Pooled variance 合并方差
當(dāng)樣本平均數(shù)不一樣,但實(shí)際上認(rèn)為他們的方差是一樣的時(shí)候,需要合并方差
不要被公式嚇到,他的本質(zhì)是兩個(gè)樣本方差加權(quán)平均
10.6 t檢驗(yàn)-合并方差1.jpg

10.6 t檢驗(yàn)-合并方差2.jpg
5. Cohen’s d
效應(yīng)量(effect size):提示組間真正的差異占統(tǒng)計(jì)學(xué)差異的比例,值越大,組間差異越可靠。
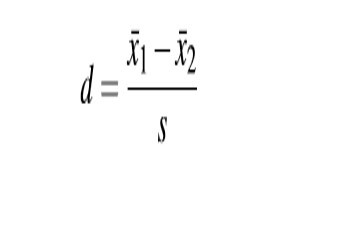
10.7 t檢驗(yàn)-cohen's d.jpg
10.7 t檢驗(yàn)-cohen's d2.jpg















 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)