


機器學習模也是如此。他們并不使用感官來感知,而是使用數據來學習——是人類提供的數據。這就是用于訓練機器學習模型的數據盡量避免偏見變得至關重要的原因。以下內容介紹了機器學習中一些最常見的偏見形式:
(1)歷史偏見
在收集用于訓練機器學習算法的數據時,獲取歷史數據通常是最容易開始的地方。但是,如果不小心的話,很容易將歷史數據中存在的偏見包括在內。
以亞馬遜公司為例。該公司在2014年著手構建一個自動篩選求職者的系統。這個想法是為這個系統提供數百個簡歷,并自動挑選出最優秀的候選人。該系統接受了該公司10年來的工作申請及其錄取結果的訓練。那么出現了什么問題?因為亞馬遜公司大多數員工都是男性(尤其是技術崗位)。人工智能算法了解到,由于亞馬遜公司的男性員工多于女性,男性則是更合適的候選人,因此對女性求職者產生了歧視。到2015年,這個項目由于產生偏見不得不取消。
(2)樣本偏見
當訓練數據不能準確反映模型的實際使用情況時,就會出現樣本偏見。通常情況下,一個群體的代表性或者過高,或者偏低。
例如,在美國訓練將語音轉換成文本的一個項目中,需要大量音頻剪輯及其相應的轉錄。那么有聲讀物將獲得大量此類數據,這種方法有什么問題?
事實證明,絕大多數有聲讀物都是由受過良好教育的白人男性講述的。不出所料,當用戶來自不同的社會經濟或種族背景時,使用這種方法訓練的語音識別軟件表現不佳。
(3)標記偏見
訓練機器學習算法所需的大量數據需要標記才能有用。當人們登錄網站時,實際上自己也經常這樣做。例如要求識別包含紅綠燈的方塊?實際上是在確認該圖像的一組標記,以幫助訓練視覺識別模型。然而,人們標記數據的方式千差萬別,標記的不一致會給系統帶來偏見。
(4)聚合偏見
有時,人們聚合數據以簡化數據或以特定方式呈現數據。無論是在創建模型之前還是之后,這都可能導致偏見。例如下面這個圖表:
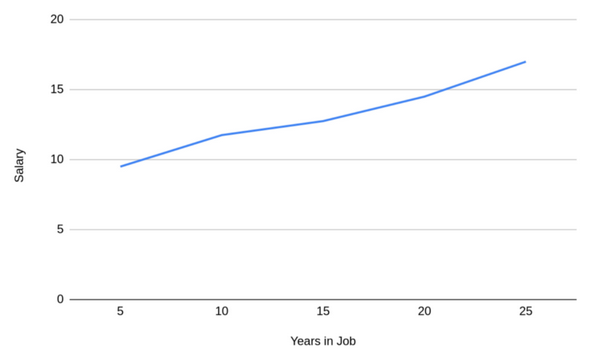
它顯示了人們的薪酬將如何隨著工作年限增加。這具有非常強的相關性,工作的時間越長,得到的報酬就越多。下圖可以了解用于創建這一聚合的數據:
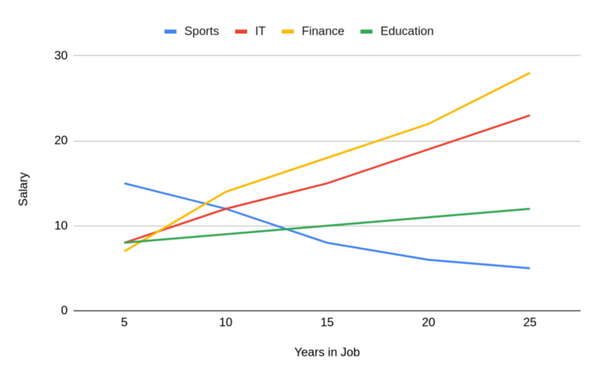
(5)確認偏見
簡而言之,確認偏見是人們傾向于相信能證實其現有信念的信息,或者丟棄不符合現有信念的信息。從理論上來說,可以構建有史以來最準確的機器學習系統,無論是數據還是建模都沒有偏見。
在機器學習的應用中,確認偏見尤其普遍,在采取任何行動之前,都需要進行人工審查。人工智能在醫療保健行業中的應用已經讓醫生們對算法診斷不屑一顧,因為它與他們自己的經驗或理解不符。通常情況下,很多醫生并沒有閱讀過最新的研究文獻,這些文獻中的癥狀、技術或診斷結果可能和他們的知識和經驗有所不同。實際上,醫生閱讀的期刊數量有限,但機器學習系統可以將它們全部收錄。
(6)評價偏見
假設一個團隊正在構建一個機器學習模型來預測美國大選期間的投票率,并希望通過采用年齡、職業、收入和政治立場等一系列特征可以準確預測某人是否會投票。于是構建了一個模型,通過當地選舉活動對其進行了測試,并且對結果非常滿意。在95%的情況下,似乎可以正確預測某人是否會投票。
隨著在美國大選活動中的應用,該團隊對這個模型感到非常失望。因為花費很長時間設計和測試的模型正確率只有55%——這只比隨機猜測的表現好一點點。其糟糕的結果是評估偏見的一個例子。通過當地選舉活動評估其模型,無意中設計了一個只對該地區有效的系統。而美國其他地區的投票模式完全不同,即使它們包含在其初始訓練數據中,也沒有得到全面的考慮。
結論
以上是偏見影響機器學習的六種不同方式。雖然這不是一個詳盡的列表,但它應該能讓人們很好地理解機器學習系統最終具有偏見的最常見方式。
版權聲明:本文為企業網D1Net編譯,轉載需注明出處為:企業網D1Net,如果不注明出處,企業網D1Net將保留追究其法律責任的權利。








 京公網安備 11010502049343號
京公網安備 11010502049343號