


其實數據產品從頭到尾做的事情就是幫公司收集數據、存儲數據、呈現數據、預測數據,拆分到具體的工作中,將會在下面介紹。
收集和存儲數據:數據倉庫
數據倉庫是存放收集來的數據的地方,做數據分析現在一般盡量不在業務數據上直接取數,因為對業務數據庫的壓力太大,影響線上業務的穩定。
1. 數據收集的時間間隔
數據倉庫里的數據按照數據收集的時間間隔大致分為兩類:
一類是可以進行離線處理的數據,一般包括內部業務數據庫及外部數據(比如:爬蟲或第三方API);
一類是需要實時處理的數據,比如:內部業務日志數據。
對于第一類一般的處理多數要求在“天”級別,比如說:一天從業務數據庫更新一次數據就足夠了,一般采用MapReduce等批處理框架來處理數據,批處理框架在進行大量數據的計算的時候有計算資源比較廉價等優勢。
而第二類實時數據處理,需要采用一些流處理框架,例如:Storm、Spark等,來處理數據,當業務發展到一定階段,業務人員對數據的實時性要求會越來越高,也就對大數據技術團隊提出了更高的要求,當然實時處理數據所需要付出的代價也是更高的。
我們要分辨清楚,哪些數據采用批處理就可以了,哪些數據是有實時處理的價值的,并不是說所有數據都實時處理就是更好,畢竟集群資源是有限的,要合理利用計算資源。
2. 數據的分層存儲
另外數據倉庫的數據存儲是分層級的,這個架構一方面跟數據拉取方式有關,一方面也是為了對數據進行層級的抽象處理。
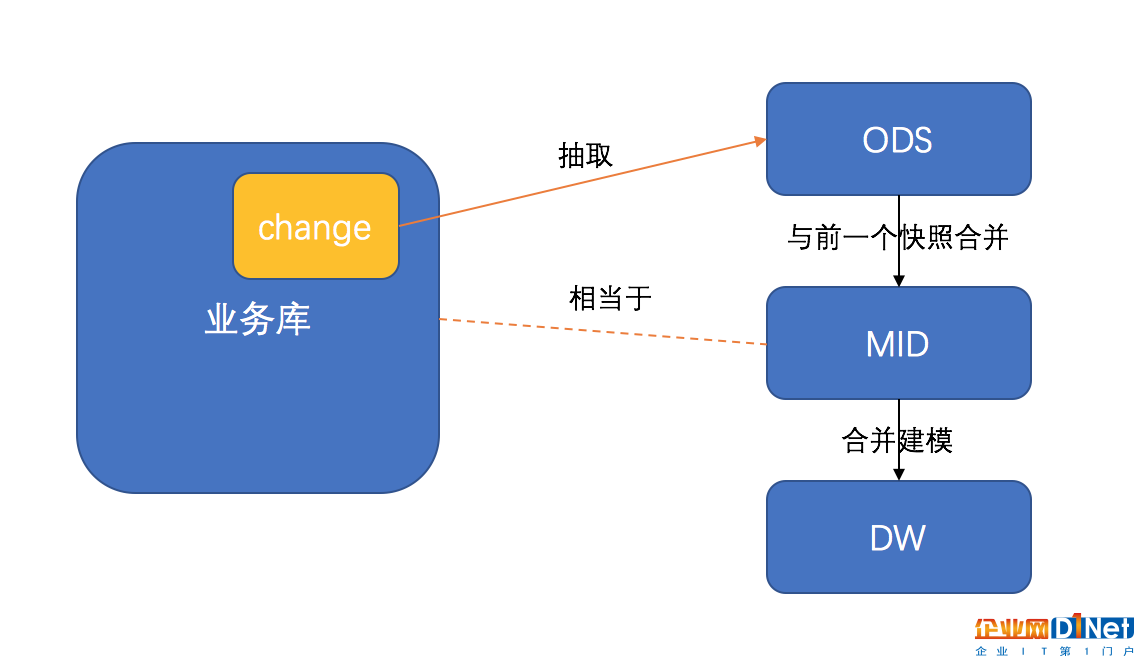
一般來說數據倉庫會至少分為ODS、MID、DW三個層級,當然層級的名稱每個公司可能不同,這里主要是在作用上進行區分解釋。
ODS層存儲的是業務數據庫在一個時間范圍內新增或更新的數據,它的存儲是線性增長的,有數據發生變化,ODS才會存儲數據。
MID層是經由ODS層數據計算得出的最新的完整版數據,相當于是業務數據庫的一個拷貝,只不過是截止到某一個時間的。
DW層是對MID層進行業務模型的抽象之后的合并層,將一些冗余的庫表簡化,做成比較利于數據抽取的庫表。
因為MID層和DW層存儲的都是完整的數據,業務數據庫數據會不斷增長,導致這兩個層級里的數據每個切片的數據都是在增長,相當于是指數增長。
3. 數據的切片存儲
數據庫的存儲是分時間戳的,相當于是把數據按照快照的方式存了n個版本,當你想追溯在某天某時間的數據的時候,就可以通過定位特定的時間戳,追溯到相關的數據。
這種設計避免了業務庫數據會不斷覆蓋的問題,相當于是在數據分析的時候加了一個時間維度,提升了一個維度,看問題解決問題的角度也就被升華了。
4. 數據倉庫建模
MID層向DW層抽象的過程,需要數據產品對業務庫表進行建模。首先要清楚了解,你所要進行抽象的業務系統是什么樣的(感覺數據產品好累,還要去了解別人的系統是怎么玩的╮(╯_╰)╭)。
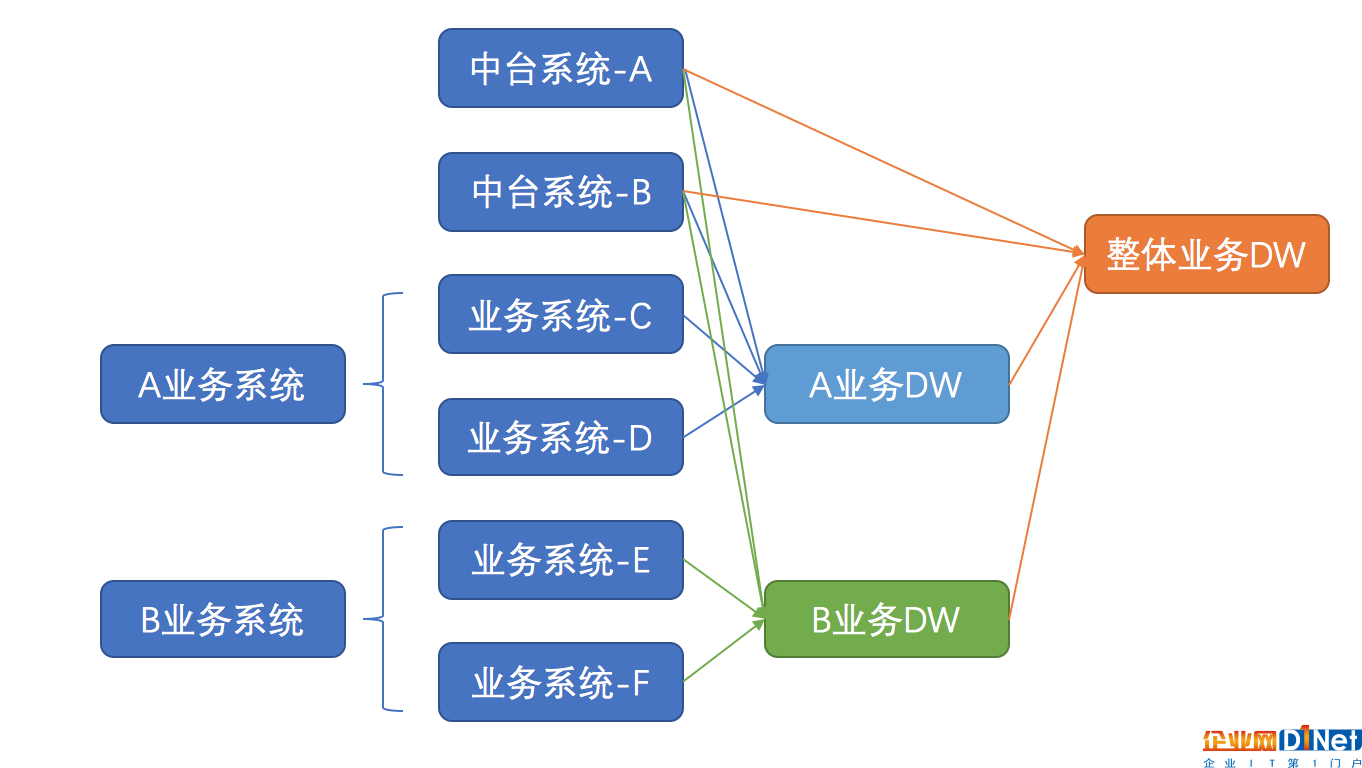
比如:你所要負責的是A業務系統的DW設計,那么首先你要把A業務系統的系統邏輯搞清楚,然后它所涉及的庫表都了解清楚,包括業務本身的庫表以及它所依賴的中后臺系統的庫表,以及各個數據庫之間的關系是怎樣,比如:是一對一還是一對多,當前庫表是否是最細粒度的數據。
一般來說建模要做到模塊互相獨立,粒度統一。因為考慮到后期做指標和取數的方便,在不同粒度上都有表是比較好的。
比如:一個電商分期業務,可能在訂單粒度上才能取到放款等數據,但是品類等維度又只能在商品粒度上取到(考慮到購物車,一個訂單可能對應多個商品),這時候就需要兩個粒度都建立對應的表才能滿足不同的取數需求。








 京公網安備 11010502049343號
京公網安備 11010502049343號