


本文作者:王齊,前Intel資深架構師,《PCI Express 體系結構導讀》圖書作者,公眾號“南郭比特”。
2016年7月初,ITRS (International Technology Roadmap for Semiconductors)發布了也許是最后一份有關半導體工藝的報告。硅半導體工業在歷經五十余年的輝煌后,逐步走向盡頭,基于硅的晶體管尺寸(Physical Gate Length)可能在五年后于10nm處終結[1]。我們繼續從理論上探討晶體管能否到達5nm愈顯蒼白,芯片在大規模量產時使用5nm日趨渺茫。
在實驗室早已取得成功的7nm技術,前景并不樂觀。基于性價比的考慮,使得在沒有足夠商業利益驅動的7nm技術,面臨著無法大規模產品化的現實。南美蝴蝶翅膀幾次微不足道的扇落,足以使得繼續在刀尖上行走的5nm與7nm技術,跌下神壇,粉身碎骨。
摩爾定律已正式結束,但永存于世間。
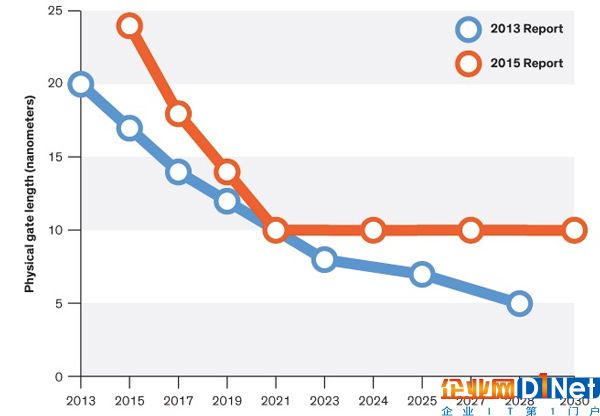
圖11摩爾定律的終結[2]
在世界范圍內,對硅半導體的材料科學,制作工藝,有能力也有意愿繼續的廠商可能只留下了Intel,Samsung,TSMC與Global Foundries。在近期或者在不久的將來,或許中國為了完成世界工廠的巨大轉型,將接過半導體生產制造的旗幟,使其更加廉價,使其更加缺乏必要的盈利以支撐整個產業鏈的持續發展,維系也在終結這個行業。我繼續悲觀地維持在幾年前的判斷[3],基于硅的半導體工業不可或缺,也不再重要。
談計算
緣起于上世紀四十年代的馮諾依曼體系正在等待著最后一根稻草。至今處理器的設計者再也無法按照自身的理念決定自己的設計方向,當這些處理器的設計者不知道做什么合適,而轉身專注于Cache、內存與I/O通路時,基于馮諾依曼體系的傳統處理器事實上已經結束。掌握用戶場景與應用的廠商目前是處理器真正的設計主導者。定制化時代不再是多年之前的預判[4],而是已然來臨,并主宰著處理器設計的方向。
硅半導體與傳統處理器的停滯不前,不會結束人類對于硅的依賴,在短期內尚無任何材料能夠完全替代硅。應用對于硅的需求依然明確。在一分鐘內,Youtube將至少接收長達100個小時的視頻文件[5];在Facebook上,每天有40億次視頻點擊播放[6]。這些應用需求將通過網絡,到達各類服務器,并從存儲器中獲取或者寫入數據,進行著各類數據的處理。在計算、網絡與存儲這些基礎架構中,硅半導體依然占據主導地位。
神奇的半導體硅改變了人類歷史的發展軌跡,也幾乎走到了盡頭。近半個世紀以來,硅一直有互補品,如砷化鎵GaAs與氮化鎵GaN,這些在大功率與高頻領域已有著重大應用的半導體材料無法取代硅,基于二硫化鉬MoS2和碳納米管CNT (Carbon Nanotube)的晶體管甚至可以將Gate Length做到1nm[7],但是依然處于實驗室階段,用其替代硅僅僅停留在論文的紙面之上。至今硅工業的天花板制約了整個IT基礎設施行業前進的腳步。
在計算領域,被軟銀收購的ARM已經難以對x86處理器帶來持續的壓力。在手機處理器上取得了長足進步的蘋果、高通、三星與華為,在近期難以在服務器市場上對Intel帶來實質性的挑戰。許多ARM服務器在SPECInt的測試中宣稱已逐漸接近了x86處理器,卻在有意無意的忽略著一個顯而易見的事實,這一代的服務器,甚至是手機處理器,都不應該繼續關注SPECInt與SPECfp這類單純比拼計算性能的基準測試。
目前處理器的設計中心已經轉向I/O與Memory Hierarchy通路的建設。在Intel的Broadwell-E處理器的Die Map[8]中,10個處理器微架構(Core)合在一起所占的比例已經不算太大,Memory Hierarchy與I/O占據了大多數的Die資源。
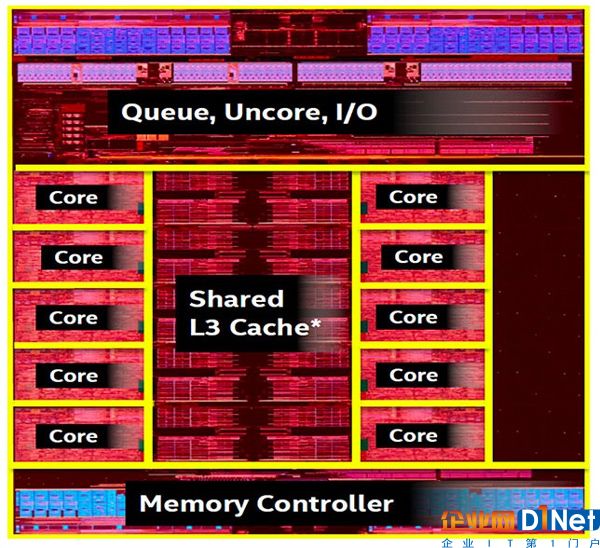
圖12 Intel的Broadwell-E處理器的Die Map[8]
在一個處理器微架構中,運算單元所占的比例幾乎可以忽略不計,在處理器微架構中,依然是種類繁多,各類數據緩沖占據著主導位置。事實上,除了模擬器件以及與模擬器件強相關的芯片外,在多數芯片Die Map中,緩沖都占據著關鍵位置。迄今為止,計算領域的多數應用對處理器的使用都是訪存密集型。
處理器的設計初衷本是為計算服務,但是在今天的許多應用場景中,處理器所承擔更多的任務是通過各類I/O設備獲取數據;這些數據在穿越Memory Hierarchy后抵達CPU的核心部件;CPU核心部件在精確計算著心跳的過程中,盡可能地快速處理這些數據,而后將其再次轉發至遠方。和密集計算相關的任務,已經通過各類硬件加速引擎,GPU或者專用ASIC實現。
我們無法直面一個簡單而令人沮喪的事實,在處理器運行著的各類協議棧的代碼組成中,用于實現快速路徑的代碼可能不超過1%;99%以上的用于異常處理的代碼,可以在超過99.9%以上的時間段內安然入睡,其存在只為等待著可能的異常出現。
不是因為這些多如牛毛的異常需要處理,也許我們這個世界已經不再需要通用處理器了。從純計算的角度上分析,各類硬件加速引擎,GPU、FPGA或者專用ASIC,遠勝今日的處理器,但是這些加速引擎在面對成千上萬種異常時無能為力。在移動互聯網廠商的數據中心中,處理器存在的最主要目的是對各類數據流進行分析、組裝、打包后發往下一站。
在這些應用場景中,處理器存在的首要原因依然不是其高效的報文轉發能力,而是能夠應對在報文處理過程中出現的各類異常。在數據中心中,處理器存在的主要作用是能夠相對高效地處理數據報文,同時還能對各類異常進行查漏補缺。不僅在計算領域,在IT基礎設施的網絡與存儲領域,通用處理器的使用方式依然如此。
能夠對通用處理器帶來挑戰的GPU,前景沒有想象中樂觀。從設計策略上看,GPU與通用處理器的最大區別在于對異常的處理。GPU專注極致計算,盡最大的可能提升TLP (Thread-Level Parallelism),而忽略異常處理;通用處理器需要考慮異常狀態的處理,以追求更大的適用性。
在不同設計策略的引導下,GPU走出了一條與通用處理器迥異的道路。Nvidia的Pascal GP100由最多可達6個的一組GPC (Graphics Processing Clusters)構建;這些GPC共享同一個4096 KB的L2 Cache;通過8個512位的Memory Controller對外交換數據;使用高速的NVLink接口與其他GP100互聯;最后通過PCIe 3.0總線與通用處理器進行連接[9]。
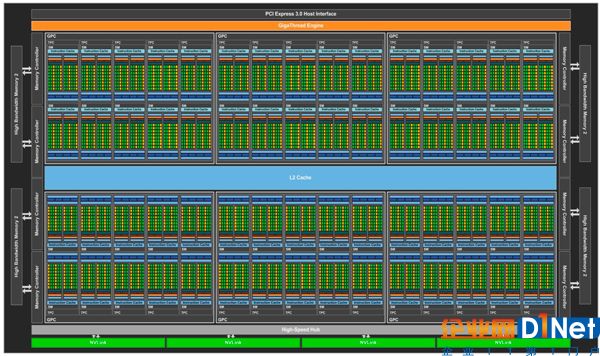
圖13 Nvidia Pascal GP100 GPU組成結構[9]
在每一個GPC中,最多可以容納5個TPC (Texture Processing Clusters);每個TPC中集成兩個SM (Streaming Multiprocessors);每一個SM包含64個CUDA和4個TU (Texture Unit)。其中最基本的CUDA核心和TU數目分別可達3840與個240個。GPU的Die Size可達610mm2,所能容納的晶體管數目可達153億個[9]。
GPU與通用處理器,是設計者在面對有限的Die Size資源,做出的不同選擇,以適用于不同的應用場景。由數目繁多的運算單元所組成的GPU,其組成結構不比通用處理器復雜,反而更為簡單。但是這無法解釋,Intel可以做出更為復雜的通用處理器,卻在高端GPU領域上反復折戟沉沙;也無法解釋,服務器級處理器的設計難度超過手機處理器,Intel依然屢戰屢敗。
通用處理器需要處理各類已知與未知的異常,在進行計算的同時,不斷地處理各類分支跳轉語句;隨時準備應對各類中斷事件;與此同時需要具備大規模的數據吞吐能力;也因此通用處理器需要一個規模龐大的通用操作系統。至今,計算已是通用處理器中的一個微小組成模塊,通用處理器中最大的模塊,是各類Cache和與其緊密聯系在一起的Memory Hierarchy。
GPU聚焦的計算世界相對單純;所處理的數據規整;數據間幾乎沒有太多的依賴;不需要管理外部設備,不需要處理各類中斷與異常,也不需要一個操作系統。從GPU的發展歷史上,可以發現,GPU所處理的圖像數據并不具備非常強的Locality特性。在GPU中,Cache存在的主要作用不是為了保存需要反復使用的數據,而是為了彌補GPU內部運算部件與外部DRAM之間的訪問延遲,從而沒有如通用處理器那樣的,復雜程度令人嘆為觀止的Cache Hierarchy結構。
在GPU中,存在與通用處理器類似的流水線,Nvidia的GP100中的基本組成模塊SM,本身就是也是一個流水線,這個流水線也被稱為Graphics Pipeline,在不考慮光柵化處理的場景下,Graphics Pipeline也被稱為Rendering Pipeline。
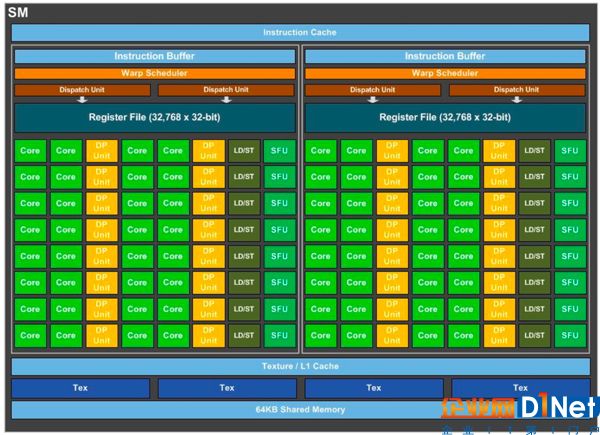
圖14 Pascal GP100中SM的組成結構[9]
在Graphics Pipeline中,依然包含與指令流水線中類似的概念,如指令Cache, Dispatch Unit, Scheduler, 與Register File等。也與指令流水線有很多不同之處,Graphics Pipeline不包含通用處理器用于數據相關性檢查與亂序處理的Reservation Station與ROB (Reorder Buffer)。在Graphics Pipeline中的ALU充斥著大量的CUDA Core,并設置了專門的TMU (Texture Mapping Unit),以便于對圖像數據做進一步處理,如旋轉、縮放、扭曲等改變尺寸的操作。
這些表面差異并非GPU的Graphics Pipeline與通用處理器指令流水線的最大區別。GPU與通用處理器的差異依然是設計策略上的區別,在于異常與中斷的處理策略上。從處理的數據源上看,GPU與通用處理器的最大區別在于所處理的數據是兩維或者多維;從解決具體問題的層面上看,通用處理器側重于對問題的精確求解,而GPU側重于獲得一個相對模糊的答案。從計算的頂層結構向下俯視,GPU與通用處理器依然遵循馮諾依曼的設計哲學。
存儲器瓶頸制約著通用處理器的發展,也同樣制約著GPU的進一步發展。主要用于計算的GPU,繼續提高TLP (Thread-Level Parallelism)不是提高GPU整體效率的有效方法。與許多人的預估并非一致,GPU繼續提升TLP,非但不能因為其高并發隱藏了存儲器延遲,而且對存儲器系統帶來了更大的壓力[10]。GPU沒有脫離馮諾伊曼體系,只是一種不同的處理器實現策略。
以馮諾依曼體系的提出作為一個重要的分水嶺,計算大致分為三個階段。第一個階段,科學家們用當時較為復雜,目前看來簡單的電路邏輯,搭建各類定點與浮點算法,嘗試精確獲得某類問題的答案;馮諾依曼體系提出至今這個階段,所解決的問題是從模糊到逐步精確,直到今天的舉步維艱;在今天,我們將基于一維的定點與浮點算法推向前人無法企及的高度之后,開始漫長的等待,從逐步精確到模糊而不可預知。
人類的努力可歌可泣,他們在不知道如何選擇是正確之時,做出從精確再次重歸模糊的選擇,重拾在上個世紀末被暫時擱置的人工智能,引入了一個新的詞匯深度學習,開始了從一維空間的接近精確到多維空間模糊決策的探索之旅。目前深度學習的理論基礎還顯薄弱,這一代的計算平臺,無論是通用處理器或者GPU還可能都不是一個合理的計算平臺。
這些事實并沒有阻擋,深度學習領域對GPU的嚴重依賴。如果僅從今天人類掌握的技術中做選擇,GPU比通用處理器更加適合模糊計算這個領域。GPU從誕生之日起,就沒有追求精準的計算結果,設計目標是其處理結果能夠滿足人眼模糊的分辨率。
Alpha Go戰勝李世石,在弈城網與野狐網上橫掃天下,沒有保證每一步棋都是絕對最優,只需保證每一步棋比人類所能構想的最優稍勝一籌。至今利用深度學習的所有已知成果,甚至無法幫助我們精確地確定,某一個指紋或是某一個面孔一定歸屬于某一個人。
似乎在深度學習領域,我們很難得到一個精確結果。這些沒有實現,且有機會實現的目標,為人類的發展提供了新的希望。在很多情況下,人類所追逐的是希望,而不是最終的結果。在內心深處,我并不情愿這一次的探索之旅成功。因為每當出現一個領域,其模糊決策能夠比人類更加接近精確時,在這個領域,機器都將戰勝人類。
談網絡
計算、通信與人類文明形影不離。不同的時代賦予了計算不同的內涵,也賦予了通信不同的內涵。在每一個時代,計算與通信總是密不可分,相輔相承。計算離不開網絡,反之亦然。在今天,計算領域無法突破馮諾伊曼體系,通信領域面臨著香農極限。幾乎在同一個時間點起步的IT基礎設施的兩大領域,計算與通信,也幾乎在同一個時間點止步不前。
在上世紀的四十年代末期,近代IT歷史上,出現了兩個對電子與電信行業的發展產生深遠影響的事件,香農發現了以自己名字命名的三大定律,香農的三大定律奠定了信息論與編碼理論的基礎,也給人類帶來了一個新的詞匯比特(Bit)。與此同時肖克利發明了晶體管,晶體管的出現極大促進了計算與通信的發展。
晶體管很快應用在電話系統中,也同時出現在計算領域。集成電路的出現進一步加快了現代的計算與通信系統的演進。在Intel的第一個處理器4004正式推出之后,以太網如影隨形。計算與網絡兩大領域,在硅工業的持續進步過程中,在自身與自身的劇烈碰撞與相互繁殖中,持續擴展著各自的應用邊界,之至今日的云基礎設施。
1973年,施樂的Bob Metcalfe發明以太網,之后DEC與Intel的加入極大促進了以太網的發展,以太網的第一個版本DIX (DEC Intel Xerox) V1于1980年正式發布[11]。以太網在陸續戰勝FDDI (Fiber Distributed Data Interface)、ATM (Asynchronous Transfer Mode)等一系列競爭者之后,一路絕塵。在局域網領域,建立了一個不可匹敵的以太帝國。
上世紀末出現的IB (InfiniBand) 試圖對以太網發起挑戰,卻在近期無法看到動搖以太帝國的絲毫可能。IB的V1.0版本出現在2000年,設計野心是替代處理器系統的局部總線PCI,互聯網中大規模應用的以太網,與SAN (Storage Area Networks)中的FC (Fibre Channel)。IB最本分的應用依然在大規模處理器集群應用中。
IB從誕生起的十年中備受磨難,Intel不會坐視IB與PCI Express總線競爭;比IB誕生更早的FC在SAN領域已根深蒂固;無所不能而且無處不在的以太網最后還是將IB擠壓至其本分的應用領域,集群服務器。TOP500處理器一直是IB不能失守的最后陣營。IB是學術界的寵兒,在對高性能計算有所追求的領域,IB在許多應用場景中憑借著出色的性能與較低的延時勝出,而在HPC (High Performance Computing)和高性能云計算領域得到的廣泛應用[12]。
IB架構唯美,干凈,一秋若水。這個一秋若水緣于在其漫長的發展過程中,一直被忽略也樂于被忽略,沒有經受過多的干擾,二十幾年前,我第一次去喀納斯湖,除了震撼外,體會的是寂靜而后的肅殺。偶爾為之,別樣風景。人的存在會打破自然的靜謐,也帶來勃勃生機,缺少萬物之靈的景色,難抵極境。我喜歡現在這樣的,有三兩好友陪伴著的喀納斯。因為人的存在,風景格外精彩。
以太網精彩世界源自于諸人參與的熙熙攘攘。InfiniBand很少有機會去介入而分享這份精彩。縱觀IT史冊,能取得流行而大獲成功的技術不會唯美,多數是黑大傻粗,成本低廉的。Unix的設計哲學KISS (Keep It Simple and Stupid)在今天無限接近真理。有所長的丑戰勝無缺的美發生在此時此刻,而且在不斷的演繹進化與升級。
以太網從誕生之日起至今日,從未完美過,與優雅ATM (Asynchronous Transfer Mode)相比,始終是下里巴人,直到把陽春白雪的ATM徹底趕出歷史舞臺。如果IB的所有優點,都能通過以太網進行應用場景微調,或者上層協議補充,IB依然還叫IB,無法更近一步。以太帝國是有日出不窮的缺陷,但是以太帝國還是以太帝國。
私有數據中心的興起,使得以太網與其身后的Ecosystem愈顯臃腫。在一個數據中心所使用的傳統交換機與路由器中,大多數軟件協議棧并沒有太多的用武之地,其中許多協議是為了解決廣域網存在的各類問題。在廣域網技術持續發展,取得顯著進步的同時,也不可避免的積累了一系列問題,在解決這些問題的過程中,更多的新協議在持續產生的同時,必須要兼容舊協議。不同廠商因為各自的利益,所提供的網絡設備在互聯互通上并沒有想象中完美。
以太網的使用過于廣泛,這個廣泛在帶給以太網無限空間的同時,也帶給設計者不小的麻煩。以太網所面對的問題絕不是TCP/IP協議棧的低效,不是存儲轉發模式帶來的延遲,不是吞吐量不足,不是流控機制,也不是QoS。這些問題在理論上全部可以解決。
以太網所面臨的主要問題在于自身使用的過于廣泛,參與者過于眾多,Ecosystem過于強大。這使得以太帝國在長期以來只能有變化而無真正變革。治大國如烹小鮮,基于以太網的網絡基礎架構設計者,對任何一個微小調整都會陷入“什么是權衡,什么是掣肘,什么是不得已,什么是怎樣做都是錯的”,這樣深重的哲學思考中。
Internet網絡組成的復雜程度已經不能用任何詞匯去描述。從最末梢的移動設備,引申到2G、3G、LTE (Long Term Evaluation)、IP RUN到核心網;從最末端的PC機,引申到Wi-Fi、交換機,各級路由器到骨干網。即便我們不去討論國家級的網絡基礎設施這樣的深重話題,一個大型跨國公司的網絡拓撲結構也足以復雜到令人無法直視。
網絡設備價格始終居高不下,但是對于許多應用場景而言,這些昂貴的網絡設備所提供的多如牛毛的Feature,除了必不可少的硬件通路部分,只有部分功能真正有用。在交換機與各類路由器中,硬件成本所占比例很低,其售價的多數是為了補貼軟件上的投入。這些盈篇滿籍的軟件投入,所體現更多的是商業利益,而非技術驅動所帶來的需求。
移動互聯網的興起重置了網絡基礎設施的發展軌跡。承載著數以億計用戶的互聯網應用背后,是龐大的數據中心。互聯網數據中心的野蠻成長,逐步觸發了云計算與云存儲技術的誕生與發展,云時代的到來對網絡基礎設施提出了新的挑戰。來自這個領域的精英,首先面對的挑戰是理解已有的網絡基礎設施。擺在這些人面前的第一道難關不是溫習基礎的網絡經典著作,而是去理解在他們眼中,毫無道理,不知所云,只能死記硬背的幾千種RFC與ITU制定的協議。
RFC與ITU標準已多如牛毛,從TCP/IP到OSPF、BGP、IGMP、STP多達幾千種。這些協議無法消除不同提供商的網絡設備,在數據交換層面上的統一;在控制與管理層面每家廠商的做法更加不會相同。最為重要的是,傳統的交換機與路由器并不能滿足一些新增的業務需求。
一個新增協議,從制定、討論、發布到實際部署的周期之長,使得最有耐心之人亦無法忍受。這些協議是否被接受,在很多情況下并無至深的理論依據,所遵循的只是質樸的商業叢林法則。
人類文明得以持續向前的動力,在某種程度上,是因為總有一些不安現狀的精英們,敢于持續地挑戰現有的叢林法則,并創建新的秩序。這些精英通常是近乎強迫癥的完美主義者。他們的病態只有兩種解藥可救,一是融入舊的體制用時間與精力換取空間,或是另辟蹊徑。待到直面成千上萬,不知所云的網絡協議時,他們最終選擇另辟蹊徑。
基礎網絡設施在經歷了最初爆發期之后,步履蹣跚。網絡運營商與設備制造商,在各種商業利益,甚至是在國與國的利益間周旋,騰挪空間有限,這種空間有限所帶來的直接后果是各種類型的低效,這一低效使得在這個行業的精英進一步流失,使這個行業事實上止步不前;也進一步使得這個行業持續發生著各類并購重組,使得從事這個行業的公司總量在逐步縮小。
一個曾在華為數通的朋友與我講,我們打敗甚至打死了一個又一個對手,卻也每況愈下。我的回答是你們熬死了一個又一個對手,對手是自己打敗了自己,他們的精英不是英雄遲暮,就是轉行做了其他事情,只有你們堅持了下來。這種堅持對這個產業是一種維持,也使得依靠自身驅動帶給這個產業的創新乏善可陳。
這些問題使得SDN (Software Define Network)的出現順理成章。我們很難將SDN定義為一種新技術。從上世紀七八十年代至今,IT基礎設施始終處于高速螺旋的上升階段,我們在并不算長的四十年間,在同一片領域完成了多次迭代,以至于在信息科學領域,幾乎很難再次出現諸如Shannon的“A Mathematical Theory of Communication”這類革命性文章。SDN并不例外。
2007年,Martin Casado在他的博士畢業論文《Architecture Support for Security Management in Enterprise Network》中,提出目前的企業網規模較大,運行著各類網絡應用與協議棧,對網絡安全配置管理帶來了一系列問題。在這些企業內,網絡安全策略由復雜的路由、橋接策略以及ACL表、包過濾等機制組成,導致整個網絡管理的復雜性,并帶來的一些網絡安全問題。
為此Martin Casado提出了一種理想化的網絡架構,稱作SANE解決這些問題。在SANE中,控制器通過其分發能力對請求轉發的數據流進行授權,SANE交換機僅僅負責報文的轉發。SANE介紹了一種全新的網絡分層,并且該設計可以很容易擴展到幾十甚至幾百個網絡節點[13]。
我不認為當時的Martin Casado能夠真正理解,這個世界的基礎網絡設施可以復雜到何等程度,強大如Stanford這樣的世界級院校,搭建一個諸如Intel這樣跨國企業的網絡環境也很困難,更不用說運行其上承載的各類應用。也許當時的Martin Casado只是認識到了這些網絡的復雜性,見識到了多如牛毛的網絡協議棧與諸多術語后,決定不再去理解,而另辟蹊徑。
在此后的第二年,Nick McKeown et al. 在ACM SIGCOMM上發布了一篇題為《OpenFlow: enabling innovation in campus networks》[14]的論文,正式提出了OpenFlow的概念。這兩篇論文宣告了SDN的誕生。
SDN誕生后,這一新型的網絡設計框架首先得到了互聯網廠商的熱捧。2011年,Google、FaceBook、Microsoft與Yahoo等廠商成立了ONF (Open Networking Foundation),聚焦于OpenFlow技術標準[15]。2012年,Linux內核集成了OVS (Open vSwtich)[16]。2013年4月,以思科為首的網絡廠商如夢初醒,成立ODL (OpenDayLight),致力于開源的SDN控制器框架的實現,這個框架的名稱也被稱為OpenDayLight[17]。
思科類傳統網絡設備提供商的參與,在某種程度上極大促進,也極大制約了SDN的進一步發展。網絡設備提供商的參與,使得SDN技術有機會進入國家層面的網絡基礎設施領域;也因為這些既有利益的獲得者首先也是既有投資的保護者,他們的參與使得SDN技術在遵循商業原則的前提下在遲鈍且平緩的演進,不再是一個劇烈的變革。
即便如此,SDN的發展依然超乎了Martin的想象,以至于Martin在回答什么是SDN時,總是在回答“I actually don't know what SDN means anymore, to be honest”。或許Martin認為,SDN在容納著各類不完美的不斷前行中,已物是人非,偏離了至清至澈的論文軌跡。
2016年2月,Martin Casado離開VMware加入著名的風險投資公司Andreessen Horowitz并成為合伙人[18]。如同Andy Robin離開Android,這些創始人的離開無論是因為什么外因,最重要的內因依然是,他們認為在這個領域他們已經完成了歷史使命。或者說在Martin Casado的內心深處,SDN尚未開始,就已經結束。
SDN所解決的最重要的問題首先是解耦,分離底層硬件與網絡操作系統。無論是思科的IOS (Internetwork Operating System),還是華為的VRP (Versatile Routing Platform)都是耗費了成千上萬人年的產品。我們在購買這些傳統路由器的時候,都在為這些人年埋單。在多數應用場景,我們所購買的路由器使用的僅是IOS和VRP提供的極少數功能。而且IOS和VRP雖然在盡最大可能包羅萬象,依然無法解決所有問題,一些用戶的自定義需求依然無法得到滿足。
通常網絡設備在邏輯上分為控制平面(Control Plane)和數據通路(Data Plane)。其中控制平面的主要由兩大部分組成。一是設備硬件資源的維護,包括網絡端口狀態的掃描和系統的初始化與監控等;二是運行網絡協議,如BGP、OSPF、ISIS與ARP等。網絡設備通過運行這些網絡協議,生成用于數據通路的各類查找表。
網絡設備的數據通路則使用這些查找表,盡最大的可能性快速地進行報文轉發。對于一些交換機和路由器以外的網絡設備,如DPI、防火墻、Load Balancer類設備,數據通路的設計稍有不同,這些設備偏向于根據控制平面配置的策略決定如何處理網絡報文。
在SDN理論正式定型以前,每個網絡設備同時具備控制平面和數據通路。對于性能要求高的企業級設備,控制平面采用的是專用CPU,以及圍繞該CPU的存儲、總線、和外設來實現。數據通路多采用專用ASIC,并作為一個外設連接到控制平面的CPU。
對于家用級別的設備,如Wireless Access Point而言,數據通路和控制平面往往做在同一個以嵌入式 CPU 為核心的系統中。Linux是最常見的針對家用設備的操作系統。控制平面的程序,如DHCP服務器、Web服務器、Iptables、NAT等運行在Linux的用戶層。Linux 的內核負責報文轉發。在這樣的小設備中,Linux用戶層和內核之間的Netlink,有時也加上一些POSIX API做輔助,構成了數據通路和控制平面的通信方式。
SDN的核心思想是,進一步分離網絡設備的數據通路和控制平面,并定義兩者之間的通信標準。這個思想解決了很多實際存在的問題,首先是數據通路設備和控制平面設備可以分別演化;其次是在不同的應用場景中,對數據通路的性能和控制平臺的 Scaling 要求各有不同,設計者可以針對應用環境來自由搭配。對于網絡設備的用戶和運營商來說,更為關鍵的一點是 SDN 體系結構減輕了對硬件廠商的依賴。
在SDN出現之前,用戶購買的網絡設備,由于每個廠商設備的配置方法不同,其上控制平面的協議設計并不相同,彼此間很難做到完全兼容。這使得用戶在初期選定了某個廠商的產品,后續更新的時候有時也必須繼續選擇該廠商的產品,否則前期網絡運營獲得的經驗和固定下來使用方式都將失效。
SDN把數據通路設備僅僅定義為一個必須支持公開接口的黑盒子,而控制平面的程序通過這個公開的接口對數據通路設備編程。采用這種方法,傳統硬件廠商提供的一系列控制平面的程序失去了原有的作用。用戶只需要維護自己的控制平面程序就可以保證網絡運營的連續性。數據通路設備可以隨時隨意進行更換。
SDN引入了Flow Table。在傳統的交換機與路由器中,每支持一種新的協議,不是在固有表中添加表項,就是添加一張新的表格。網絡世界經過了幾十年的發展,在傳統路由器與交換機中已經積累了過多的表項。Flow Table的引入在提高了端口控制靈活度的同時,對所有表項進行了歸一化處理,這也使得SDN網絡有機會從邏輯上實現集中管理。SDN使用的集中管理策略,與傳統網絡設備采用的自適應管理,原本談不上孰優孰劣。只是事物發展螺旋上升中的不同狀態。
SDN的出現,依然為本已死氣沉沉的網絡基礎設施帶來了一絲活力,SDN在持續著輝煌的同時,也在按照幾乎不可控制的態勢引入更多的功能。但是當我們從整個網絡基礎架構的更上層俯視SDN時,卻很難體會得出SDN是一次顛覆性變革的結論。整個網絡基礎架構并無根本的變化,只是一次管理策略的調整與重構,路由器與交換機內部基礎的緩沖管理與算法幾乎絲毫未變。
事實上SDN的前綴軟件定義SD (Software Design)更加令人關注,在SDN嶄露頭角后不太長的一段時間里,各類軟件定義風起云涌,有軟件定義云計算,軟件定義數據中心,軟件定義存儲,軟件定義基礎設備,直到Software Design Everything。在這些種類繁雜的軟件定義中,恐怕最有共性的一件事情莫過于把之前配置各類設備所使用CLI (Command Line Interface)方式,換成了RESTful API。
本已停滯不前的x86處理器一夜間重回中心,似乎x86處理器重新強大到了無所無能。NFV (Network Function Virtualization)的提出,進一步神話了x86處理器與其下的虛擬化部件。卻在有意無意中無視x86 XEON處理器自從Nehalem起,在微架構層面的創新已乏善可陳的事實。即將大規模推廣的Kaby Lake僅在計算層面上,與Nehalem相比并無質得提高。x86處理器在計算領域完敗于GPU之后,Kaby Lake所做出的選擇是重歸這個公司的起點,存儲。
談存儲
從人類有語言之日起,吟游詩人用歌謠頌揚著傳說;文字出現之后,我們使用甲骨文與紙張記載著歷史;每一次新材料的出現,人類總試圖將其與存儲聯系在一起,各類磁介質、硅介質,直至堅硬的藍寶石介質。至今,存儲世界已歷經五千余年。在IT基礎設施的三大領域,計算、網絡與存儲中,如果說計算在比拼著智慧,網絡在比拼著記憶力,存儲就是在比拼著一份執著。
存儲對于穩定性的要求壓倒了一切。在一個存儲系統的所有Feature中,穩定性是1,剩余的所有特性是其后的0。如果一個存儲系統談不上穩定,那么其身后的所有特性都將無用武之地,一個存儲系統所追求的首要目標,永遠不是速度、帶寬、延時與IOPS。而證明穩定性的方法無他,唯有時間的磨練。這決定了進入存儲行業就是參加了一場沒有終點的馬拉松賽跑。
在IT基礎設施的三大領域中,存儲行業之執迷守舊,刻骨銘心。計算與網絡的世界雖然精彩,但是人類文明的傳承,最終還是依靠那幾頁紙。始皇帝的焚書坑儒,使華夏殷商前的文明成為傳說;亞歷山大的幾次大火,讓古埃及文化在人類歷史上的展現僅剩下了幾座金字塔。人類已無法再次忍受數據的大規模丟失。
這種無法忍受對存儲系統的穩定性提出了苛刻的需求,也使得證明過自己存在價值的存儲設備極難被淘汰。紙張依然在使用中,至今尚無退出歷史舞臺的征兆。也許是因為杰文斯效應作梗,在全世界大力提倡并實施無紙化的今天,紙張的使用有增無減。單純從穩定性和數據保存的持久性上看,當代的多數存儲系統還遠不如墨水與紙張。
曾多次被預言很快退出歷史舞臺的磁帶,依然活躍在今天的云歸檔基礎設施中,NAND Flash與最新的存儲類內存SCM (Storage-Class Memory)也沒有終結硬盤。存儲行業是最苛刻同時也是最寬容的領域,進入門檻極高也極難被淘汰。移動互聯網嘗試過的各類無孔不入的顛覆,并沒有對存儲這個古老的行業帶來質的沖擊。近期出現的SD存儲遠沒有確立自己最后的存在。
在移動互聯網爆發之前,世間沒有任何IT基礎設施能夠滿足其對于超級高并發的需求。這使得以Google、Amazon、FaceBook、包括中國的TAB在內的移動互聯網廠商,為滿足自身IT基礎設施需求,所進行的試錯與開發過程中,創建了一套計算、網絡與存儲混合的IT基礎設施框架。Wikibon將這個正在使用的,基于移動互聯網的IT基礎框架,統稱之為ServerSAN。
ServerSAN是近期軟件定義存儲各種概念的合集,具備計算、網絡、存儲與服務器虛擬化功能,幾乎包羅萬象。ServerSAN最重要的兩個子集是虛擬化計算與分布式存儲層。在云計算時代,傳統的IOE架構很難適應彈性擴展要求與高并發而舉步維艱。這使得世界上幾乎每一個角落的移動互聯網廠商都在去IOE,并不限于中國政府。Wikibon對ServerSAN的發展寄予厚望,在2016年提出了一個激進的路線圖。
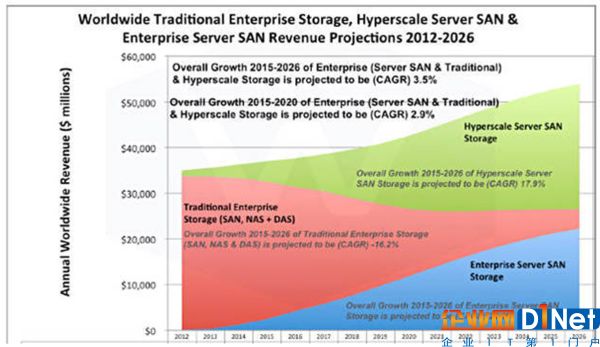
圖15 2016年Wikibon對ServerSAN的預測[19]
Wikibon堅信Server SAN在未來將逐步取代傳統的存儲設備,包括SAN、NAS與DAS,但是也將E3S(Enterprise Server SAN Storage)的年復合增長率CAGR(Compound Annual Growth Rate)從2015年預測的44.2%劇烈的下調至22%[20]。顯然,這個增長還是一個非常激進的數字,也很顯然Wikibon的評估充滿變數。
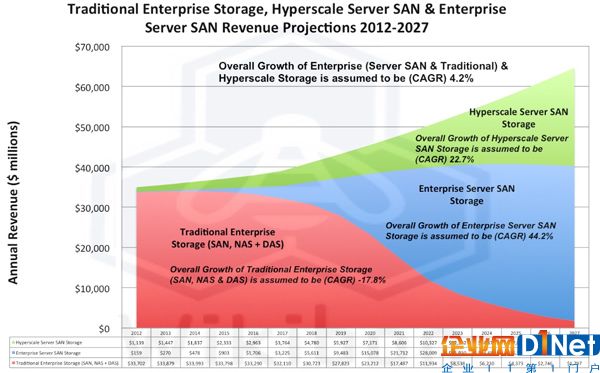
圖16 2014年Wikibon對ServerSAN的預測[20]
硅工業的事實停滯影響了整個IT基礎設施行業,也使得與這個行業相關的多數產業很難獲得兩位數以上的CAGR,在這個大背景下,整個IT基礎設備進行的依然還是此消彼長的零和游戲。ServerSAN與之前出現的HCI (Hyper Convergence Infrastructure)是計算,是網絡,還是存儲,還是三者皆非?ServerSAN自身到底是什么?
Wikibon從未給出過Server SAN的精確定義,這種不精確為Wikibon帶來的最大優點是,其觀點很難出現錯誤。Wikibon之外的組織也沒有給出過Server SAN的精準定義。相比較而言,只有H3S (Hyperscale Server SAN Storage)的定義相對較為清晰,Google、Facebook、Amazon、TAB這些移動互聯網廠商正在使用的,自產自銷的IT基礎架構即為H3S。
剩余的存儲本質可以歸為一類,無論是傳統的企業級存儲或者是E3S。E3S與傳統的企業級存儲可以在文字游戲中轉化。圖15中的各種數據也許很容易得出,首先計算存儲直至2027年的CAGR,并以此獲得存儲市場的總容量,之后計算移動互聯網廠商的自產自銷,剩余的兩部分使用文字上的技巧進行份額劃分即可。
E3S的定義事實上可有可無。本質上,ServerSAN所面臨的問題是,移動互聯網所使用的H3S架構如何真正進入一個企業內部。對于多數企業,不存在移動互聯網廠商追求的超高并發度和高彈性擴展需求,也不需要規模如此龐大的IT基礎設施;H3S的維護者是昂貴的研發工程師,而不是普通的獲得幾個認證即可從業的IT工作人員。
ServerSAN架構需要在企業中找到適合的應用,找到用戶真正使用ServerSAN而拋棄傳統存儲架構的原因。如果僅是因為傳統存儲廠商不情愿使用Scale Up方法向上擴展存儲,而導致傳統存儲的價格居高不下,我并不認為ServerSAN找到了自己的生存空間。諸多ServerSAN廠商提供的產品,就其技術上的合理性而言,是否真正超過了雙控盤陣列這個歷盡滄桑的設計。
我們無法忽視絕大多數移動互聯網廠商使用的H3C架構,依然停留在二層交換機連接著的廉價PC機的組成結構中。在移動互聯網快速演進的時代,這些H3C架構主要在為移動互聯網的應用,更為準確的說是超高并發訪問服務。Google、Amazon、Facebook與TAB這些廠商從解決共同面臨的超高并發訪問處入手,并在解決各自面臨的不同問題的過程中,迅速差異化。至今,現有移動互聯網IT基礎設施的H3S架構,最大的特點是任意兩家的H3S架構間并無相近之處。
移動互聯網廠商所進行的大規模工程化而后逐步形成的H3S,設計之初,只為解決自身應用的一個或者幾個問題,所構建的基礎設施,從全局視覺下觀看,遍體鱗傷。事實上,幾乎任何一個存活超過十年的大型IT基礎設施,都是遍體鱗傷,在無限追求完美的設計者心中,都有強烈地將其推倒重來的沖動。也許這些H3S在等待著下一次輪回,直到世界盡頭。萬生終有一死。
已然如此的H3S架構,直接將其通用化,并大規模替換現今企業正在使用的IT系統的前景,沒有Wikibon想象中樂觀。如果準備進入企業市場的超融合架構,依然基于H3S使用的二層交換機組合大量的廉價PC的設計理念,不管是披著HCI或是ServerSAN的外衣,依然會面對絕大多數企業沒有大規模并發、高度彈性擴展的業務需求的這些事實。
即便如此,國內外還有許多初創公司涉足ServerSAN這個領域。很多打著ServerSAN旗號的產品,僅是從Github下載若干開源軟件,之后進行簡單的排列組合,最后再加上一個管理界面而已。許多準備進軍這個廣闊的企業級存儲市場的初創公司,真正的技術含量甚至只有一個華麗的用戶界面。
H3S和E3S在架構上的合理,可能遠不及幾十年前的Supercomputer。在多數Supercomputer系統中,處理器與I/O設備獨立組成兩張網絡,之后這兩張網絡采用某種拓撲結構進行連接,分離計算節點與I/O節點,以便于分離計算與I/O,獲得最短的平均訪問延遲與最大的訪問帶寬。但是這種結構在十幾年前,在移動互聯網呈爆發式增長的前夜,沒有被主流互聯網廠商接受。
在那個年代,沒有太多的移動互聯網廠商真正關心所采用IT基礎設施的絕對合理性,而是重點關注著業務的高速推進,和與其密切相關的超高并發訪問。移動互聯網廠商當時所追求的是用最快的速度,不是最完美的IT基礎設施解決所面臨的問題。有些互聯網廠商嘗試過IBM在銀行系統中使用的Mainframe,Mainframe的居高不下的價格并不是被他們棄用的最主要的原因。
搭建IT基礎設施的首要目的是為應用服務,Mainframe與SQL數據庫的組合沒有解決移動互聯網應用對高并發訪問的需求,遲鈍的售后無法滿足高速運轉的互聯網應用的開發步伐。這使得移動互聯網廠商決定搭建一套屬于自己的全新的系統。對未來的茫然,使得他們務實地選擇了,最易于重構系統也是最易獲得的,基于以太網與PC機的系統。
幾乎所有互聯網應用對數據庫都有著重度的依賴。傳統的SQL數據庫不僅價格昂貴,可擴展性差,而且無法滿足移動互聯網應用所要求的高并發,隨著移動互聯網的蓬勃發展,這類數據庫迅速的在移動互聯網應用中淪為配角。
NoSQL (Non SQL, Not Relational or Not Only SQL)數據庫應運而生,這個新型數據庫重創了SQL數據庫,也重創了SQL數據庫之后的傳統集中式存儲。這些NoSQL的一個顯著特征,就是相互間沒有什么絕對的共性。兩個都被稱為NoSQL的數據庫,其相互間的差異遠大于兩個都被稱之為SQL的數據庫。
在移動互聯網時代,各類業務快速推進,且基于對未來不確定性的考慮,使得NoSQL數據庫的每次發展更似一次試錯。NoSQL數據庫對于存儲系統的使用更加務實,可以直接使用內存,也可以直接使用本地硬盤。NoSQL數據庫的設計初衷不是為了排斥集中式存儲,只是Cassandra、HBase和MongoDB的設計者可能沒有購買盤陣列的資金,所以采用了RAM、硬盤、SSD、PC機這類最容易獲得的硬件資源,以搭建底層的存儲系統。這使得集中式存儲在無意中被冷落。
為了保證數據存儲的可靠性,NoSQL數據庫多采用了直接且粗暴的做法,最常用的手段是使用DHT (Distributed Hash Table)算法保存多個副本。這種至簡有顯而易見的不足,簡陋的多副本策略甚至可以將香農氣醒,也因為其至簡,NoSQL相對于SQL數據庫更具可擴展性,可以運行在相對低廉的硬件系統中,由普通PC機與交換機組成的集群系統中。
如果從ACID (Atomicity, Consistency, Isolation and Durability)的特性上對比NoSQL與SQL,前者不堪一擊。ACID模型是SQL數據庫創建時立下的規則,在這套規則體系下,SQL數據庫是上帝。NoSQL建立在BASE (Basically Available, Soft state and Eventually Consistent)模型基礎之上,所堅持的只是基本可用。這種基本可用所帶來的靈活性,使得移動互聯網應用所追求的極度高并發特性得以滿足。ACID與BASE本質上兩種完全不同的設計策略,
BASE模型的特點之一是我行我素,對Consistency沒有過高的要求,這種我行我素在某種程度上,使得基于BASE設計理念的NoSQL數據庫各不相同。移動互聯網應用絕非不重視數據的Consistency,只是在更加追求系統的高可用與高并發性的過程中,不得已舍棄了Consistency特性。對于絕大多數的移動互聯網應用,過強的Consistency特性并非不可或缺。
為了降低系統訪問延遲并盡最大可能的保證容錯,移動互聯網廠商所使用的存儲系統多采用Geo-Replicated架構。在這種架構下,數據在不同的地理區域中有多個副本存在,這些多個數據副本的Consistency在跨地域布置的前提下,需要與系統的可用性進行取舍。
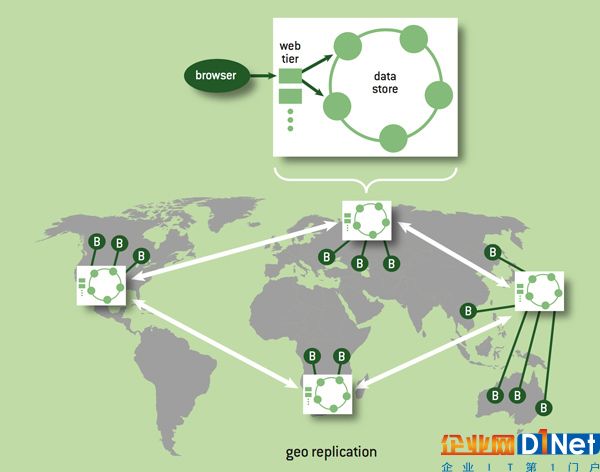
圖17 Geo-replicated架構下的數據分布[23]
移動互聯網廠商所采用Geo-Replicated架構使得Eventual Consistency模型幾乎成為必然的選擇。Eventual Consistency模型似乎很簡單,在不同分區下的數據副本最終獲得一致即可,對數據的最后一次更新最終將體現在所有的分區中,但是并不保證每次讀取的數據是最新的。這種對Eventual Consistency的定義非常模糊,而且在一定程度上是誤導。事實上一個數據中心的設計者如果不采用一定的策略,即便是最簡單的Eventual Consistency模型也無法滿足。
Lloyd Wyatt et al.[21]給出了Eventual Consistency模型較為嚴格的定義,在一個Geo-Replicated架構中,寫入到一個數據中心的數據,需要最終寫入到其他數據中心,如果所有數據中心都收到了相同數據集合的寫入操作,那么在整個系統中這個數據集合的所有的數據副本需要保持一致。即便不考慮有人惡意插拔網線與主機電源而制造的數據分區,僅考慮網絡報文延遲與傳輸順序,在整個系統中即便只保證Eventual Consistency也并非易事。
Eventual Consistency這種弱一致性模型,有許多顯見的問題。Lloyd Wyatt et al.列舉了一些互聯網應用,因為采用Eventual Consistency所導致的一系列問題,如Comment Reordering、Photo Privacy與Double Money Withdrawal等[21]。有些問題不傷大雅,有些問題較為嚴重。Lloyd Wyatt et al.所列出的這些問題是,移動互聯網廠商為了追求系統容錯與訪問延遲所付出的應有代價。
Consistency是一個非常重要的概念,但是99.9%的IT從業人員不必去深入理會這些概念。除非你立志做個類似于SPARK的系統,而不是去簡單地使用。雖然SPARK這類系統,世界上只需要一個,但是依然有一個問題值得思考,這個系統為什么不能出自中國。
在移動互聯網世界中,Consistency概念首次引發較大范圍的關注是在1998年。那一年Eric Brewer正式提出CAP (Consistency, Available and Partition tolerance)[22]猜測并于1999年正式發表“Towards robust distributed systems”這篇文章。
其正確性在2002年由Seth Gilbert和Nancy Lynch證明,CAP Conjecture也正式轉換為Theorem[23]。傳統的CAP理論認為,在一個網絡系統中,數據一致性(C)、數據的高可用性(A)和數據對分區的容忍性(P),三者不可兼得。
CAP理論的最簡單的解釋是假設系統僅存在兩個節點,并處于分區的兩側。如果僅允許一個節點更新狀態會導致數據不一致,即喪失了C性質。如果為了保證數據一致性,將分區一側的節點設置為不可用,那么又喪失了A性質。除非兩個節點可以互相通信,才能既保證C又保證A,但是這又會導致喪失P性質。一般來說跨區域的系統,設計師無法舍棄P性質,那么就只能在數據一致性和可用性上做一個艱難選擇[24]。
2012年,Eric Brewer重新回顧了CAP理論,并針對實際情況做出了一些修訂。在CAP三個特性中選二,并不是簡單的非黑即白。首先在一個分布式系統中,真正支持絕對分區的系統并不多見,Kyle Kingsbury在[24]中列舉的在分布式系統中存在的分區情況,基本上都是因為各類異常導致的。
即便是在數據分區成立的前提下,為了實現100%的可用性而不顧一致性,或者為了實現100%的一致性而不顧可用性,都是過于絕對,而并不可取。在一個實際系統中,可以在時間空間的更加細粒度的劃分中,使得系統基本可用,基本一致。這些對“基本”的選擇是系統設計中需要考慮的權衡與取舍[25]。
CAP理論緣于Eric Brewer一次閑聊,對于之前熟悉Leslie Lamport分布式系統的學者或者工程師而言,CAP理論嚴格意義上是一次不錯的推導,不過這并不影響CAP原理帶給互聯網與移動互聯網的巨大推動作用,也許更多的人開始學習并認識分布式理論源自簡單的CAP推論而不是Leslie Lamport晦澀的論文。
CAP理論的出現,給予了NoSQL對抗SQL數據庫的有力武器,特別是在討論強Consistency對于一個數據庫是否不可或缺這樣的話題。此后依照BASE理念,而不是ACID理念,互聯網廠商逐步自行研發自己的分布式系統,以滿足移動互聯網應用對于超大并發數的追求。之后Google提出了MapReduce、GFS (Google Filesystem)和Bigtable這些簡練的能夠讓普通程序員即可掌握的分布式編程模型。
隨后繼承了MapReduce方法和GFS理念的Apache Hadoop分布式得到了迅速普及與發展。Hadoop使用HDFS (Hadoop Distributed File System)管理文件系統,可以部署在低廉的硬件平臺之上的同時,提供較高的吞吐量。從分布式計算的理論上講,MapReduce模型較不完美,但是簡單實用的編程模型使Hadoop系統突飛猛進。
MapReduce將所有操作歸為Map和Reduce兩個操作,可能是當時的Google在面對當時的程序員素質在當時做出的選擇。這種簡單分類并不完美,但是極易被程序員掌握。MapReduce編程模式采用了最簡單的分而治之策略,簡單粗暴,易于掌握,卻很難是最優,甚至是次優編程模型。而后出現的SPARK在計算框架上與Hadoop相比有了一次較大的提升,我認為在集群計算模型上優于Hadoop,也依然認為Hadoop由于是第一次出現,其歷史地位不可撼動。
整個IT史冊在充斥著并不完美中奮然前行。在IT基礎領域中,太難的算法和實現策略很難推行,晦澀的算法不容易實現,也不容易理解。這個行業在飛速發展的年代,一邊是市場人員Time-to-Market的壓力,一邊是盡快提交代碼的壓力,這一切使得在工程實現的算法都可能不是已知理論的最優,甚至不是次優算法。KISS理論在移動互聯網高速發展的時代再度勝出。
至今IT基礎設施的三大領域,均遭遇瓶頸。硅工業發展的事實停滯,使得基礎設施跌下神壇,不能再次依靠自身驅動自身的方式前行。這使得一些更優的算法與體系結構有機會重整旗鼓,至少嘗試一下已知理論上的最優,以精益求精。另一方面尋求下一個硅的腳步從未停息,ITRS在面臨硅工業的困境,提出了六個可能的方向,System Integration、Heterogeneous Integration、Outside System Connectivity、More Moore、Beyond CMOS和Factory Integration[1]。
在這些方向中,最具顛覆的莫過于Beyond CMOS。Beyond CMOS是在尋求新的材料替代硅,也許需要幾個世紀,也許就在明天。假設這些Beyond CMOS的某一種新材料能夠真正取代硅,那么這種新材料的應用將率先在存儲領域出現。從設計的角度上看,諸多存儲Cell的一字排列,其復雜程度遠低于CPU或者網絡設備的交叉矩陣;人類歷史上也從來沒有像今天這樣依賴著存儲,所有歷史上存在的數據已不堪舍去,新的數據川流不息。
這使得在IT基礎設施的三大領域,計算、網絡與存儲中,存儲被寄予厚望,存儲級內存SCM正在暫露頭角。從Intel與Micron合作的3D xPoint開始,近些年會陸續誕生一些新型的SCM,2017年1月已經宣布量產的CrossBAR的ReRAM[26];Nantero與富士通合作在2018年推出基于CNT (Carbon Nanotube)的NRAM[27];Samsung收購Grandis后與IBM一道全力推進STT-RAM[28].
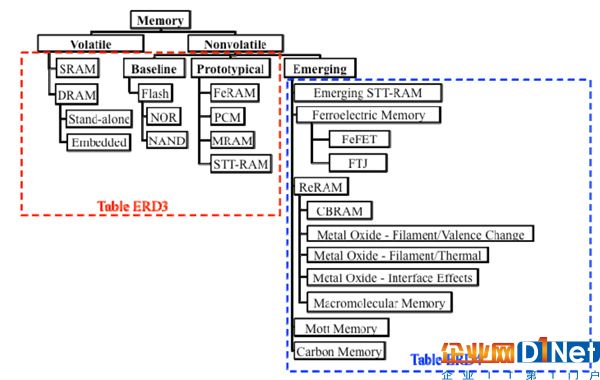
圖18 存儲器分類[29]
這些SCM也許在近期很難在Volatile領域全面替代DRAM,或者在Nonvolatile領域全面替代NAND Flash,但至少會給一潭死水的存儲器層次結構引入變數,從而帶來沖擊。內心深處,希望一切使用新型材料的SCM取得革命性的突破,心中堅信在計算、網絡與存儲三大領域中,存儲將最先取得突破。
參 考 資 料
[1].International technology roadmap for semiconductors 2.0 2015 edition executive report (ITRS)[J]. Semiconductor Industry Association, 2016.
[2].Courtland R. Transistors could stop shrinking in 2021[J]. IEEE Spectrum, 2016, 53(9): 9-11.
[3].http://blog.sina.com.cn/s/blog_6472c4cc0102e9hr.html
[4].http://blog.sina.com.cn/s/blog_6472c4cc0102e0xg.html
[5].www.youtube.com/yt/press/statistics.html
[6].https://techcrunch.com/2015/11/04/facebook-video-views
[7].Desai S B, Madhvapathy S R, Sachid A B, et al. MoS2 transistors with 1-nanometer gate lengths.[J]. Science, 2016, 354(6308):págs. 100-102.
[8].http://hothardware.com/reviews/intel-core-i7-6950x-extreme-edition-10-core-cpu-review-broadwell-e-arrives
[9].Nvidia whitepaper, NVIDIA Tesla P100, The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World’s Fastest GPU.
https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf
[10].Kay ran O, Jog A, Kandemir M T, et al. Neither more nor less: optimizing thread-level parallelism for GPGPUs[C]//Proceedings of the 22nd international conference on Parallel architectures and compilation techniques. IEEE Press, 2013: 157-166.
[11].The History of Ethernet. NetEvents.tv. 2006. Retrieved September 10, 2011.
https://www.youtube.com/watch?v=g5MezxMcRmk
[12].Subramoni N S I H, Panda D K D K. Performance Analysis and Evaluation of InfiniBand FDR and 40GigE RoCE on HPC and Cloud Computing Systems [J]. 2012.
[13].Casado M. Architectural support for security management in enterprise networks[D]. Stanford University, 2007.
[14].McKeown N, Anderson T, Balakrishnan H, et al. OpenFlow: enabling innovation in campus networks[J]. ACM SIGCOMM Computer Communication Review, 2008, 38(2): 69-74.
[15].Open Networking Foundation Formed to Speed Network Innovation. Press release. Open Networking Foundation. March 21, 2011. Retrieved October 30, 2016.
[16].Corbet J. Routing open vswitch into the mainline[J].
[17].Medved J, Varga R, Tkacik A, et al. Opendaylight: Towards a model-driven sdn controller architecture[C]//Proceeding of IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks 2014. 2014.
[18].Darren Pauli. NSX Daddy Martin Casado leaves VMware to become a VC. Feb. 2016.
[19].David Floyer. Server SAN Readies for Enterprise and Cloud Domination. Aug. 2016. http://wikibon.com/server-san-readies-for-enterprise-and-cloud-domination/
[20].David Floyer. The Rise of Server SAN. July 2015.
http://wikibon.org/wiki/v/The_Rise_of_Server_SAN
[21].Lloyd W, Freedman M J, Kaminsky M, et al. Don't settle for eventual consistency[J]. Communications of the Acm, 2014, 57(5):61-68.
[22].Brewer E A. Towards robust distributed systems[C]// Nineteenth ACM Symposium on Principles of Distributed Computing, July 16-19, 2000, Portland, Oregon, Usa. DBLP, 2000:7.
[23].Seth Gilbert and Nancy Lynch. Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services. ACM SIGACT News, Volume 33 Issue 2 (2002), pg. 51-59.
[24].Kyle Kingsbury. A blog post on network partitions in practice.
https://github.com/aphyr/partitions-post
[25].Brewer E. CAP twelve years later: How the" rules" have changed [J]. Computer, 2012, 45(2): 23-29.
[26].Peter Clarke, Times E E. Crossbar ReRAM in Production at SMIC[J]. 2017.
[27].Peter Clarke, Times E E. Fujitsu Is Licensee of Nantero's Carbon-Nanotube RAM [J]. 2018.
[28].McGrath D, Times E E. Samsung buys MRAM developer Grandis[J]. 2011.
[29].International technology roadmap for semiconductors 2.0 2015 edition beyond CMOS (ITRS)[J]. Semiconductor Industry Association, 2016.








 京公網安備 11010502049343號
京公網安備 11010502049343號