


數據平臺領域發展20年,逐漸成為每個企業的基礎設施。作為一個進入“普惠期”的領域,當下的架構已經完美了嗎,主要問題和挑戰是什么?在2023年AI躍變式爆發的大背景下,數據平臺又該如何演進,以適應未來的數據使用場景?
本文將從上述問題的出發,盤點和整理技術演進的趨勢,并提出一體化架構將是下一代技術趨勢的方向。新架構通過創新的“增量計算”范式來統一數據分析中流、批、交互不同的計算形式,通過“湖倉一體”統一存儲形態,真正實現一體化Kappa架構。同時,新架構以湖倉存儲為基礎,具備開放性和擴展性,能夠對接支撐AI,具備進一步迭代和擴展能力。
大數據發展20年發展歷史概述
大數據是從 2003 年開始發展的,其標志性的開端是《MapReduce: Simplified Data Processing on Large Clusters》、《The Google File System》、《Bigtable: A Distributed Storage System for Structured Data》三篇論文的發表,作為大數據發展的起點,發展至今恰好20年。這20年我們可以將其概括為3 個階段:孕育期、發展期和普惠期。
第一階段-孕育期:2003 年~ 2010 年,谷歌為支持搜索業務奠基大數據領域,以論文的形式公開架構和技術細節;Yahoo開源其搜索后端的數據處理技術,并命名為Hadoop。
第二階段-發展期:2010年~2020 年,兩個關鍵事項有力地推動了大數據的發展:1)以 Hadoop 為核心的開源技術,即開源分布式大數據平臺的繁榮發展;2)是云計算技術,極大程度上降低了大數據平臺的建設門檻。當下主流的大數據平臺大都在 2012 年前后開始發展,比如 AWS Redshift 是云上數倉的典型代表;包括Snowflake的成立,阿里云與飛天大數據平臺起步等;
第三階段-普惠期:從2020年至未來的10年,我們認為是大數據的普惠期。為什么這樣講,普惠期有兩個特點,其一是業務進入收獲期:我們能看到千帆競發后,大部分企業被淘汰,少數企業通過競爭最終占領市場,并逐步形成規模,例如Snowflake 2020年上市;其二從技術角度來看,部分成熟場景下技術開始迭代式發展,如“批計算”、“流計算”和部分“交互分析”技術成熟后不斷被后來者挑戰;同時,場景繼續外延不斷引入的技術,如 AI 相關的技術由此外延衍生出來,呈現出對其他領域的輻射作用。目前我們能看到這幾個特征同時具備。
當下數據平臺的典型架構和主要痛點
當前典型的數據平臺架構是計算部分采用Lamdba架構,存儲層由數據湖或者數據倉庫構建。AI等基礎設施尚在發展成熟中。
以下通過三個不同場景數據架構的實例,總結當前數據平臺的典型架構:

我們將當前數據平臺簡化為如下典型架構圖,其中“不變”的部分用黑底來表示,“變”的部分用灰底來表示,如圖下可見。
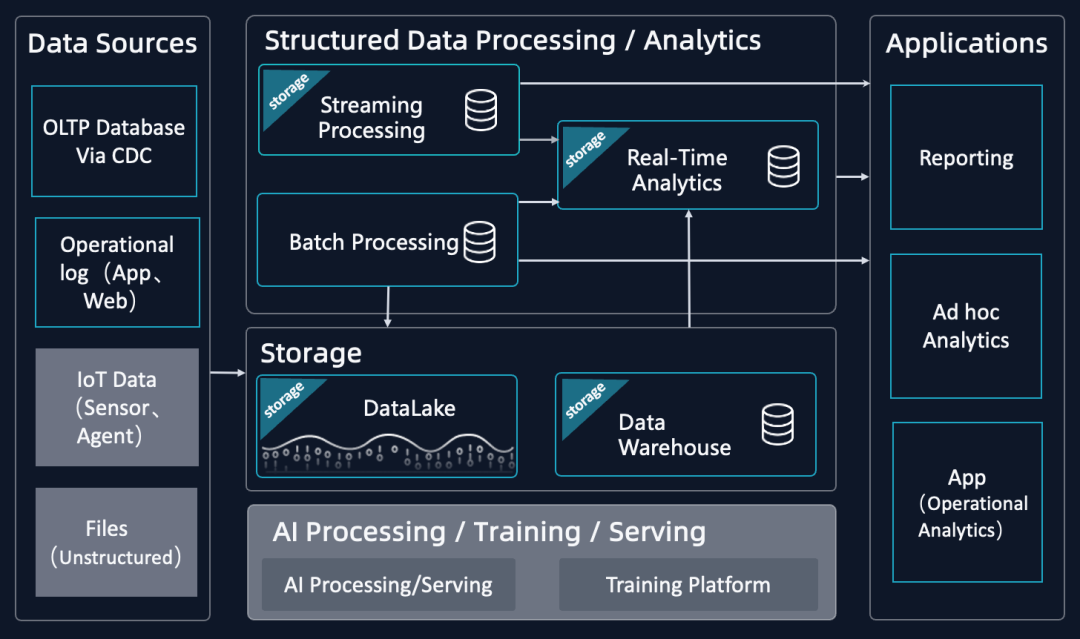
圖4: 當前數據平臺典型架構圖(簡化版)
數據源
? 不變的部分(標準場景):
? 關系型數據庫:通過 CDC 等方式采集結構化數據。
? 操作類日志:通過 APP 或是 Webservice 采集的海量日志。
? 變化發展中的兩類(新場景):
? IoT、智能設備數據:在物聯網普及之前,大多數據都是用人的行為數據。隨IoT類技術發展,設備的數據會逐步成為另外一個主要的數據來源。
? 半結構化和非結構化數據:隨著 AI 能力的增強,這部分數據開始被加速地采集上來。
數據處理
? 不變的部分(標準場景):
? 數據分析引擎分為“批處理”、“流計算”、“實時分析”,也都有各自比較固定的數據處理和分析的場景,通過組合的方式滿足不同業務需求,這個架構通常稱之為Lambda架構。
? 數據存儲架構分為“數據倉庫”與“數據湖”,二者都不算新概念,使用場景也比較固定,大多數企業選擇其一。例如hadoop體系就是一種典型的數據湖架構。
? 變化發展中的部分(新場景):
? AI相關的場景和架構還在發展中,場景差異大,尚未標準化。而最近火熱發展的LLM又帶來額外的變化:部分企業會選擇,由一個特征工程開始到 Training 到 Serving 的端到端的 Pipeline;另一部分企業不再做特別多的 AI 訓練,而是在 Huggingface 上下載一些已有模型 ,只做基礎的 AI 處理。
“典型的/不變的”結構化數據架構(Lambda)仍然過于復雜
綜合上述,總結市面上大部分數據平臺通常會選用組裝式的Lambda架構,而其需要多個API接口與多種數據組件,數據冗余度高,開發維護復雜度高。面向未來,我們認為結構化數據處理分析的趨勢會是,由一個一體化的引擎,統一“流”、“批”和“交互分析”,進而提供統一接口、統一處理邏輯,提供多種優化指標的高覆蓋度和靈活調整的能力。
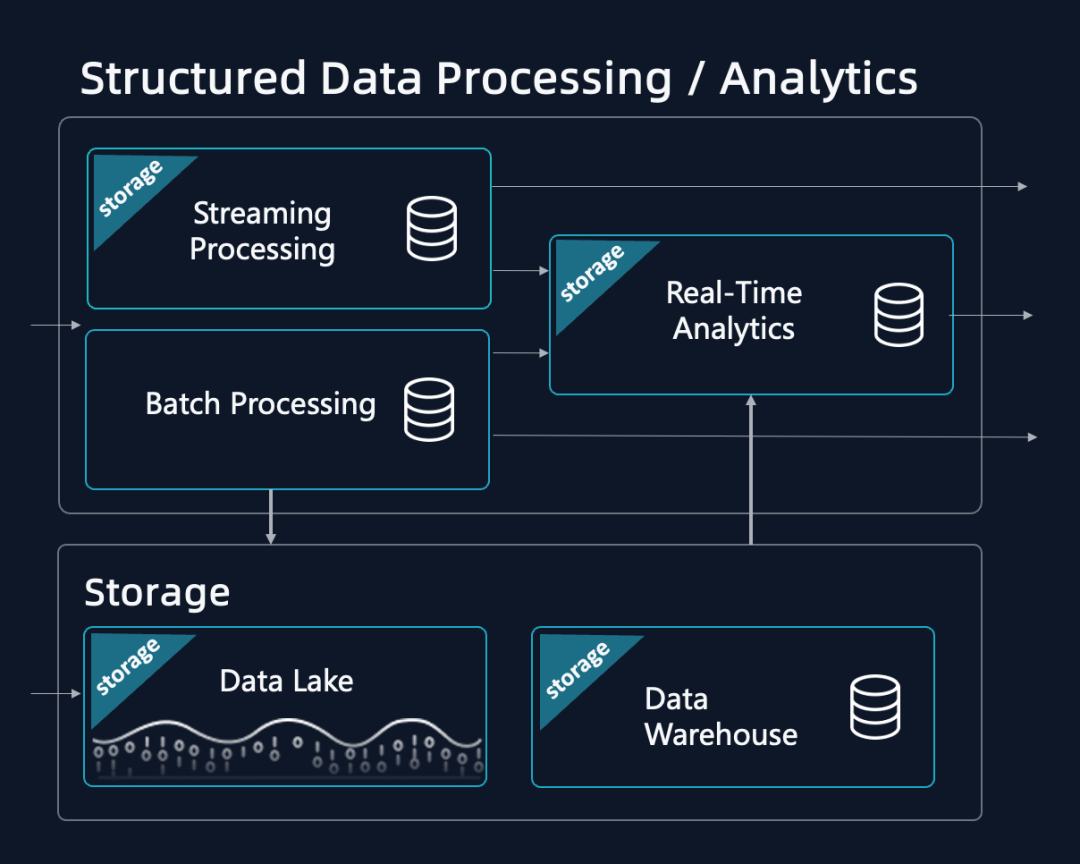
圖5: 數據分析架構圖,一種典型的Lamdba架構
Lambda組裝式架構普遍存在的三點問題:
1. 引擎數據語義均不統一,帶來極高的開發和維護人力成本。三種引擎各自獨立,查詢語言、數據語義均不統一,數據在三種引擎間流轉,開發和維護成本高。有統計數據表明用于運維這些系統的人力成本與資源成本相當。
2. 異構存儲,多套元數據,帶來大量的計算和存儲冗余和管理成本。三種引擎各自獨立但又相互關聯,為了做到局部語義統一,帶來大量的顯性、隱形的計算冗余。同時三種引擎通常配置各自獨立的存儲,帶來大量的數據冗余和數據同步的成本。湖和倉采用外表關聯,缺乏統一管理。統計這些計算和存儲冗余帶來數倍的成本負擔。
3. 缺乏滿足業務變化的靈活性。三種引擎開發運維獨立,且系統設計的優化方向不同。當用戶業務需要調整三個引擎間的配置(重新調整數據新鮮度、性能和成本的平衡點),就需要復雜的修改和重復開發。通常統計當前數據架構一旦固定下來調整的周期在 3 個月以上,難以適應靈活多變的業務發展。
但要解決這些問題,統一成一體化架構,并非數據架構師們不想,而是確有幾處難點,后文有詳細論述。
發展中的/變化的” AI 新計算范式,傳統數倉架構不能滿足,需要新架構的支持
AI給數據平臺帶來新的挑戰:AI需要更豐富的數據,數據需要更多樣的BI+AI應用。Data與AI的關系不再是Data+AI,而是Data*AI ——數據平臺不再是一對一的計算和存儲架構,而是 m 對 n 關系的架構,這樣的架構改變變化下,我們應該思考的問題是,由單點優化思路建設起來的lambda架構,能否迎接AI的挑戰,如果不能,改變的方向是什么?
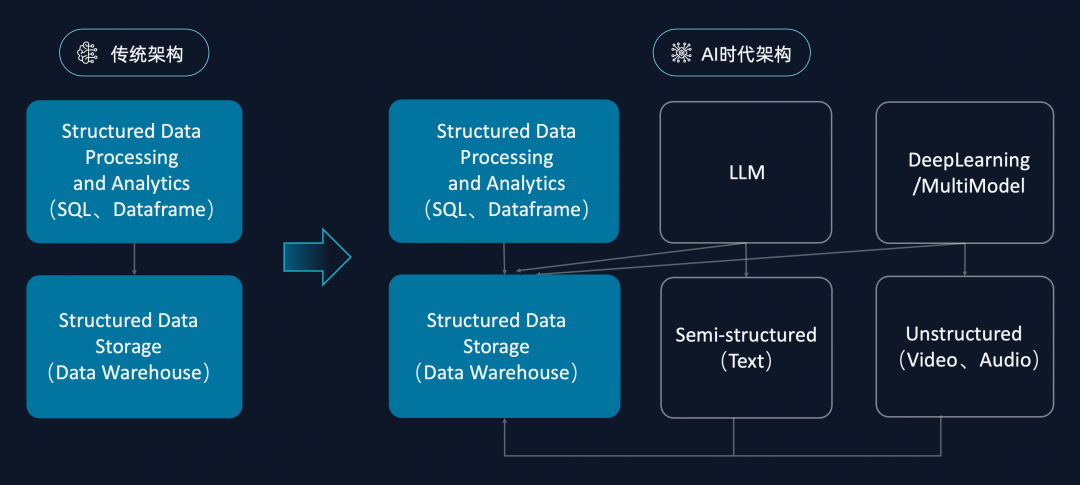
圖6: 從1對1的數倉架構,到M對N的多元異構開放架構
關系型數據庫自 1970 年誕生,到 2010 年的 40 年時間里,都是采用傳統的數倉架構(如上圖左側)面對結構化的數據處理和分析,所以存儲系統的優化都是基于結構化數據的存儲來進行的,最終迭代出來的標準化SQL引擎,也是為了做結構化數據的分析。
而最近十年,特別是隨著深度學習技術的發展,ML/AI 拓寬了數據平臺需處理的數據類型,底層引擎模式隨之改變:
? 改變一,引擎以往只能處理結構化數據二維表,現在可以通過 AI 處理包括 test 、json 在內的半結構化數據,以及處理非結構化數據(音視圖數據);
? 改變二,引擎模式的頂層計算架構也在改變,類似生成式AI對文本和數據的直接理解和解讀,類似code interpreter通過理解數據語意做大模型的插件式、多語言融合式查詢分析,是除SQL的二維關系表達和分析引擎外,將AI的計算能力納入到引擎。
未來已來,面對AI帶來的改變,我們認為數據平臺的架構更應有兼具一體化與開放性的設計。開放式湖倉一體架構,是面向Data+AI融合場景的新趨勢。
一種面向未來的新數據平臺架構概述
如上所述,我們認為能夠面向未來的下一代數據平臺,是一體化的、開放、支持Data+AI的湖倉平臺,架構設計上:
? 數據存儲部分,由湖倉一體架構承接Data+AI的統一數據底盤;
? 數據引擎部分,打破Lambda架構限制,一個引擎完成多個場景;
? 面向AI部分,在湖倉一體底盤之上向上迭代,同時與下層存儲及數據分析引擎,做融合計算。比如我們可以有SQL和Python的融合計算,通過這種方式實現一個面向未來的存儲架構。
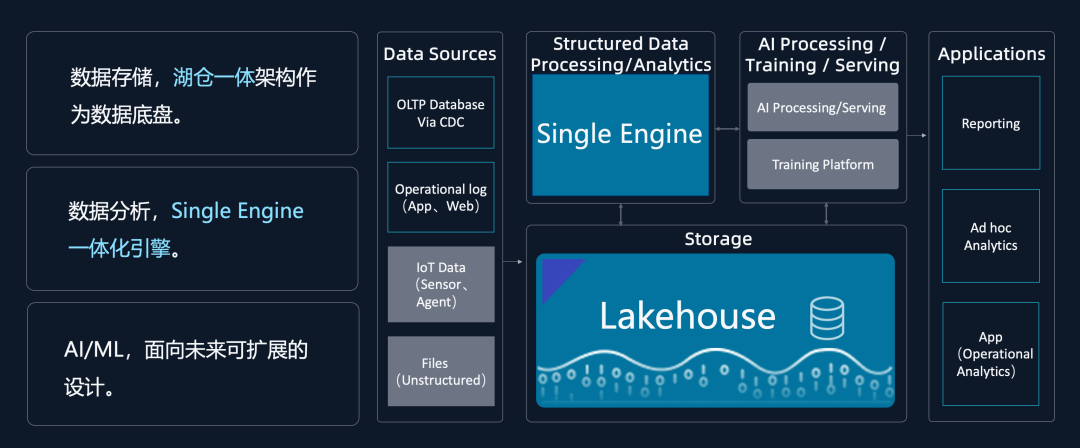
圖7:新一代數據平臺架構,基于統一分析引擎,統一湖倉一體存儲
從組裝式(Lambda)架構到一體化引擎難點在哪里?
組裝式 Lambda 架構存在的問題是業界普遍有深刻體感的,也有很多技術/產品試圖解決Lamdba架構的問題,但都不是很成功,為什么實現“一體化”的架構那么難?這主要有兩個原因:批、流、交互計算的計算形態不同,優化方向也不同。
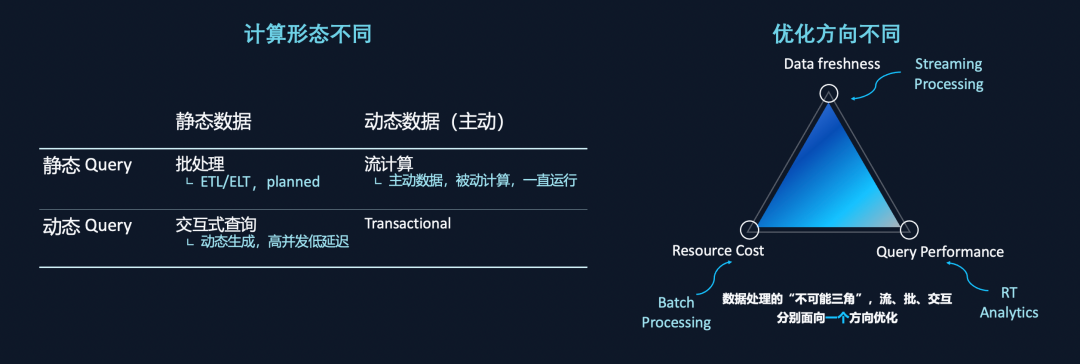
圖8: 批、流、交互三種計算形態的差異
一、有不同的計算形態
將數據狀態分靜態數據與動態數據兩類。所謂靜態數據就是當 Query 下發的一瞬間,計算是在數據的一個版本(稱為 snapshot)上進行;而動態數據是指在持續變化中的數據,由數據主動驅動計算。數據 Query 也可分成靜態 Query 和動態 Query 兩類。所謂靜態 Query 的意思是像天報表或者小時報表一樣,我們知道它在某一個時間點上會發生。動態Query是指,用戶動態下發的,很難被預測。
由以上兩個維度,可以劃分出四個象限區間,可以看出批處理、流計算、交互式分析分屬不同象限:批處理是典型的靜態數據加靜態 Query 的流程,通常是一個 Pipeline 過程;交互分析是靜態數據加動態Query,高并發低延遲;批處理和交互分析,通常是計算向數據去,是主動計算處理被動數據的過程。流計算是動態數據加靜態計算的過程,當 Plan 發起之后,就一直等待數據進入,是一個主動數據驅動被動計算的過程。
二、有不同的優化方向
上圖三角為數據平臺不可能三角,即一個平臺不可能同時實現數據新鮮度、低成本和高性能三個目標。如流計算優化的是數據的新鮮度,引擎等數據,為了使得下一條數據進來時計算的足夠快,引擎是一直拉起的狀態,Reserve了大量資源。實時數倉系統是面向性能的,也需要等待數據,需要一個非常快的數據。批處理計算面向的是 Throughput ,即 Latency 延遲,能夠提供很高的 Throughput,帶來很低的 Cost。不同的優化方向使得三個引擎也不同。
Lambda架構流行的核心原因是,流、批和交互計算,剛好覆蓋了此三角,三個不同的引擎,每一個引擎的優化方向剛好是在一個角上。通過組合的方式滿足不同業務的需求。下圖更細節地比較批處理、流計算、交互式的異同。

表1: 批、流、交互三種計算形態的差異
上圖從6個不同角度對比,在此僅選兩個例子具體展開:
對比流計算和批計算的存儲系統:
批處理的存儲是通用存儲,采用數倉分層建模的方式,數據的中間表格可以被共享,可以被其他查詢優化。
而流計算是單獨的內置存儲,不可被共享,僅面向該計算模式優化;其中流計算兩個作業之間的存儲也不同,通常用Kafka做,是純粹增量化的存儲,且僅支持某一段時間的查詢,不能做全量數據Query。
所以存儲模式的不同和計算模式的不同,使得流和批都很難統一彼此。
對比批處理和交互計算的調度模型和資源模型:
批處理通常選擇Bulk Synchronous Parallel(BSP)調度模型,是一種逐層調度模式。批處理通常作業下發后,動態向Yarn/Kubernetes申請資源,具有極佳的資源使用效率,能夠降低成本。缺點是會造成資源排隊。
而交互分析為了更好的性能,通常采用Massive Parallel Processing(MPP)調度模型,資源需要保持預置,數據被靜態劃分好,面向低延遲和高性能優化,但有很高的成本。
調度/資源模型的不同使得批處理和實時分析引擎也很難統一。
綜上可以看出由于流、批、交互三種計算引擎的計算模型、數據驅動方式、存儲系統設計、調度系統設計、資源模型等均不相同,都很難覆蓋另外兩個的場景,他們三者本身難以完成統一計算模式。
“增量計算”統一批、流、交互三種計算模式
鑒于流、批、交互三種計算模式都不能完成模式的統一,我們提出第四種計算模式:增量計算。
增量計算定義:指的是將所有計算抽象成增量的形態,實現數據的一次計算、累次使用,節省計算資源,同時能提供靈活調整的“增量時間間隔”,達成批處理或者流處理效果。因增量方式顯著降低資源使用,也能大幅提升交互分析的性能并降低延遲。
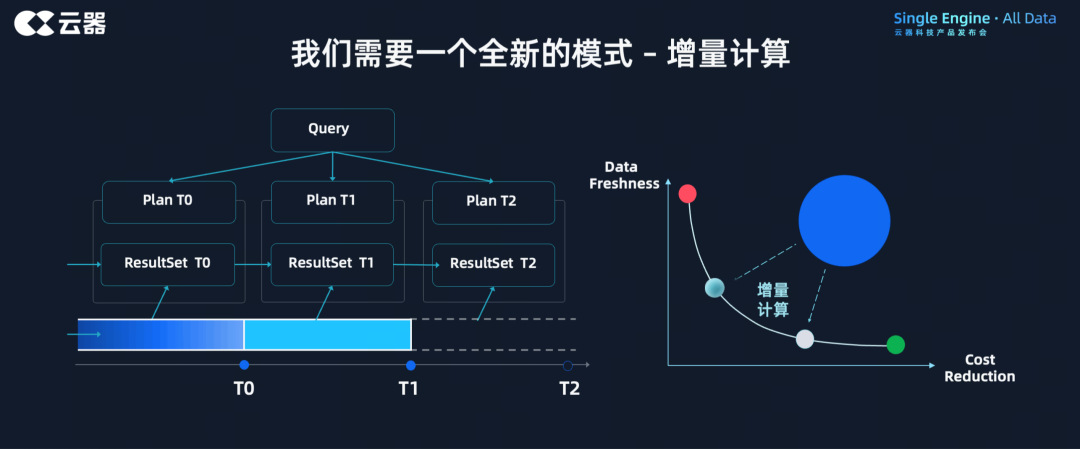
圖9:通過增量計算的方式,實現批、流、交互三種計算模式的統一
增量計算的原理:
如左圖所示,x軸時間軸代表T0、T1和T2,當Query下發時,T0動態生成Plan,基于當前最優數據和計算情況,在T0數據里得到結果集ResultSet T0;當在T1時間下發同一個Query時,該Query的計算不再從0開始,而是在T0結果集的基礎上,結合T0到T1這一階段的數據,融合起來做增量計算,得到ResultSet T1,同時在為T2計算做狀態準備。
針對批處理,可以將其作為當T0為0,從T0到T1的增量計算模式的特例,是一種從頭開始的增量計算。在最佳實踐里,用戶通常不再保持按天的批處理,而是降低調度間隔來達成更好的近實時性。
針對流計算,流計算是天然的增量計算模型,可以通過縮短T0與T1中間間隔的時間來達成。
針對交互分析,與批處理類似,交互分析也可以抽象為增量化形態,并且更簡單,因為沒有后續,所以不需要再為下一階段計算做準備。同時,因為部分交互分析的數據是持續寫入的,部分之前的計算結果也可以被后來的作業利用,大幅降低計算量。
調度增量計算的時間間隔,是由用戶根據需要調整設定的。當把調度時間間隔調整的很短,例如調整為分鐘或者秒級,整個計算模式就愈接近流計算,而如果把間隔調整天,計算模式就等同于批處理。也就是說,計算模式的改變,只需要調整調度就能實現!
總結,增量計算模式有幾點優勢:
第一,統一計算模式,進而能夠統一引擎,從根本上解決Lambda的痛點。
第二,每次Query在下發的時候,可以根據T0、T1中間的時間間隔做動態Plan,找到其中最優Plan的調節流程。能夠實現數據平臺不可能三角的平衡點,基于數據新鮮度、性能、成本的動態平衡,靈活地在三者之間找到多種多樣的平衡。
第三,結果集ResultSet均公開可用,能夠支持所有其他引擎或者平臺使用,更符合數倉建模設計邏輯,也更具開放性。
基于“增量計算”實現一體化Lakehouse數據平臺
增量計算可以解決計算模式的統一,即流、批、交互為一體;但對于數據平臺整體架構而言,還需要統一存儲和面向AI的能力,因此云器科技以增量計算為基礎,提出Single-Engine的數據平臺設計理念。

圖10:基于增量計算實現一體化Lakehouse數據平臺
基于增量計算數據計算新范式,云器科技實現了Single-Engine一體化平臺,包含如下三部分:
1. 用增量計算模式統一流、批和交互三種計算形態。
2. 用通用增量存儲的統一存儲形態。在湖倉存儲架構的基礎上增加了通用增量存儲,使得在湖倉之上能夠做增量的表達,該存儲需要做到以下三點:
• 實現大通用的存儲,是可以適應面向寫入Throughput和查詢高性能的兩個維度進行優化。
• 數據存儲支撐兩種更新模型(Copy-on-write 與 Merge-on-read 兩種模式),通過 Compaction 達到效率和成本的平衡。
• 實現數據的開放性,最終把數據的表達變成標準化的開源Iceberg存儲格式,使得其它的引擎或者平臺可以很方便地對接起來。
3. Share Everything架構。在ShareData架構基礎上增加了新維度,把數據、計算和資源三方拆開,使得批處理和交互分析在資源上可以做靈活調度。
至此,通過統一的計算模式、統一的增量存儲,并將數據、計算和資源Share Everything化,最終構成了云器Lakehouse的Single-Engine一體化架構。
云器Lakehouse具備以下關鍵能力:
1. 統一的接口,統一的語法/語義,統一且開放的數據表達(使得可以被其他引擎/工具消費)。數據與計算隔離,一套存儲支撐多種運算模式。
2. 提供面向數據新鮮度、查詢性能和資源成本三方面的多種平衡點(而不是面向三個頂點的極致優化)。具備多點優化能力,同時能支持三者之間的靈活調整。
3. 支持在平衡點之間做簡單靈活的調節。調整應該是簡單的,不需要修改大量代碼,不需要重新構建Pipeline。
4. 多種指標達到/超過當前主流產品的水平。通過Single-Engine在流、批、交互這三個場景上都有不遜于現在主流系統和架構的性能,甚至超越它們。
性能指標與能力衡量
云器Lakehouse作為一體化數據平臺,橫跨實時、離線、交互分析等多個場景,為了客觀地衡量數據集在不同場景下的表現,我們用業界標準的測試集在對應場景上,進行性能評估。特別的,云器Lakehouse由于采用了存算分離share-everything的系統架構,會通過限制virtual cluster(虛擬計算集群 abbr. VC)計算資源的規格來保證測試數據與其他產品的規格一致。盡管這樣的限制不利于發揮計算資源彈性伸縮的優勢,云器Lakehouse仍然在多個場景下同時表現出優異的性能,如圖11所示:
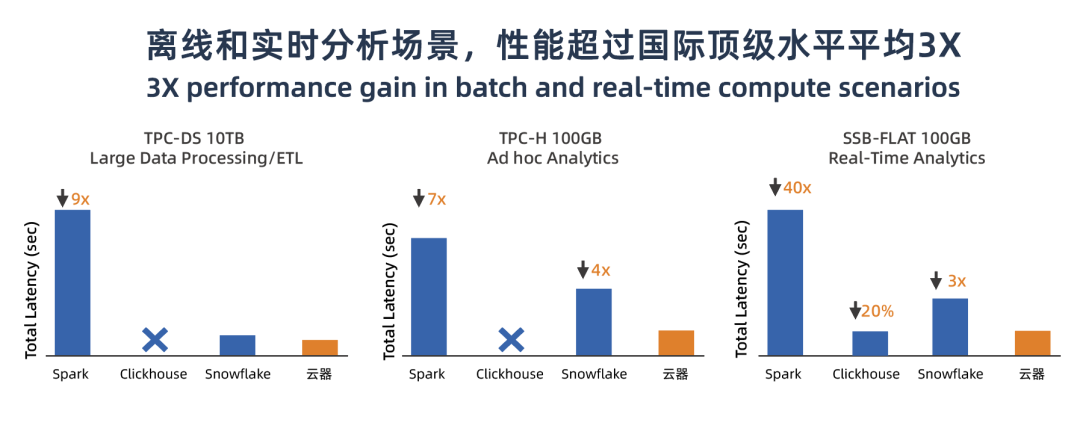
圖11:云器Lakehouse離線和實時分析場景性能指標
? 圖11-左1:大數據分析場景,TPC-DS 10TB是TPC發布的針對大數據系統的標準測試數據集,適合用于評估大數據處理及ETL處理過程,測試集包含對大數據集的統計、報表生成、聯機查詢、數據挖掘等復雜應用。以相同規格配置的處理時間評估,云器Lakehouse處理速度比Snowflake快30%,是Spark處理的9倍;
? 圖11-左2: 即時分析場景,TPC-H 100GB是由面向業務的臨時查詢和并發數據修改組成,適合用于對Ad-hoc臨時查詢評估。云器Lakehouse不僅在處理速度上達到了Spark 的7倍,且比Snowflake還要快4倍。
? 圖11-右1: 在實時分析場景,SSB-FLAT 100GB是以星型數據結構為主的數據測試集,適用于評估實時查詢性能,我們對比了Spark和Clickhouse,Snowflake。由于Spark是對批處理做優化的,實時分析會比較慢。而Clickhouse是專向實時分析優化的,它會更有優勢。測試結果顯示,云器Lakehouse比Clickhouse的快20%,是Snowflake的3倍。
在流計算領域,我們選取了4個典型場景做性能對比:
? Process場景:是單表下,單行的數據處理json展開的場景;
? 單流join場景:是雙表下,左表是一個固定的維表,Join右表是流動的實時表數據,這是一個標準的維表擴展場景;
? 單表聚合場景:是單表做aggregation,流動數據的聚合分析場景;
? 雙流join場景:是雙表流動數據的join場景。
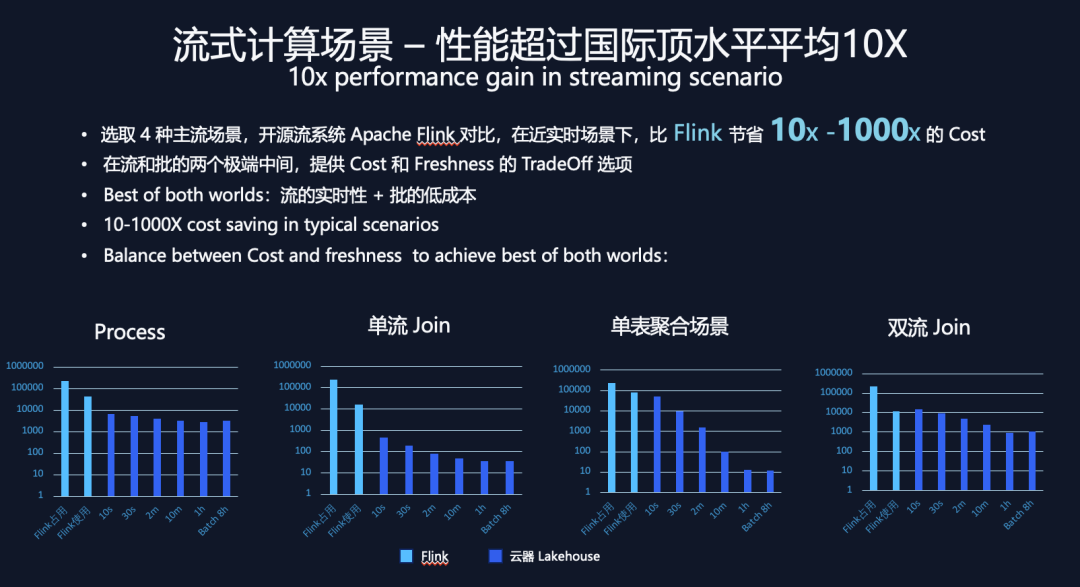
圖12:流計算細分場景的資源消耗對比
在每個場景以Apache Flink做參照對比分析,由于Flink是一個“主動數據被動計算”的過程,會有占用資源和實際使用資源的區別。如圖12所示,每張圖的前兩個數據柱狀圖指標是flink,第一個柱子代表flink的資源占用,第二個代表flink的實際資源使用。而云器使用增量計算的模式,沒有資源占用和使用差異。6個深藍色柱子代表云器Lakehouse在不同的時間間隔的資源使用情況。
在Process場景和單流join場景(圖12-左1左2)屬于“無狀態計算”,云器基于自研的向量化引擎實現,比Flink以行式處理引擎的方式快至少10倍以上,此外可以看到無論調度間隔是10秒或間隔8小時,云器流計算資源消耗差異不大。
單表聚合場景和雙流join場景,由于要考慮歷史數據/狀態,屬于“帶歷史狀態計算”,調度間隔時間的調整會很大程度上影響計算資源的消耗,從圖12右1右2兩張圖可見,云器Lakehouse在10秒調度間隔下做到和Flink持平,在30秒或調至1小時的準實時調度間隔,性能的節省可以達到百倍甚至千倍。
上述測試表明,云器Lakehouse在流處理場景上,比Flink有10x-1000x的資源消耗節省。并且,基于增量計算在“流”和“批”兩個極端場景中間,讓數據新鮮度和處理成本可以被精益平衡;讓用戶既可以獲得“流”的實時性,又可以得到“批”的低成本。
總結
針對當前主流數據架構的痛點和挑戰,云器科技提出通過增量計算的方式,統一流、批、交互三種計算模式,實現了Single-Engine的架構,覆蓋數據不可能三角,給用戶提供靈活的多種性能成本平衡點,并超越當前主流引擎的性能。此外,云器Lakehouse在湖倉架構上做到開放并實現All data技術理念,一體化的湖倉平臺能夠同時支持BI和AI的Workload。基于一體化架構,云器提出AI4D的新方向,通過AI的方式更好地優化平臺效率。(注:AI4D領域另有專題技術白皮書論述)

圖13: 總結,云器科技基于增量計算打造一體化平臺的最佳實踐









 京公網安備 11010502049343號
京公網安備 11010502049343號