35 萬行代碼,曠視重磅開源天元深度學習框架 ,四大特性實現簡單開發
責任編輯:xfuesx |來源:企業網D1Net 2020-03-30 15:50:31
本文摘自:CSDN

【導讀】2020 年 3 月 25 日,人工智能企業曠視科技舉辦線上發布會,曠視聯合創始人兼 CTO 唐文斌宣布正式開源其 AI 生產力平臺 Brain++ 的核心組件——天元(MegEngine)。本次發布為 Alpha 版本,基于 Apache License 2.0,向外界共開源約 35 萬行代碼,包括 C++、CUDA 和 Python代碼,在GitHub 上進行發布。
發布會上,曠視研究院高級技術總監田忠博詳細介紹了這款剛剛正式對外開源的深度學習框架。

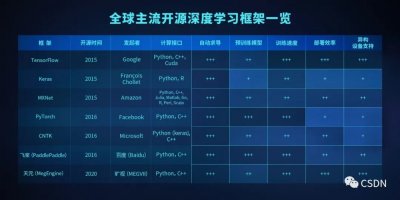
曠視天元開源之時,正值深度學習框架百花齊放的時代。
自 2007 年 Theano 誕生以來,經過十余年發展,深度學習技術與應用突飛猛進,深度學習框架也處在不斷迭代與進化的過程;另一方面,開源的概念在全球范圍內越來越深入人心,這使得人工智能開發依賴的環境安裝、部署、測試,以及不斷迭代改進準確性和性能調優的工作變得更加簡單,在人工智能領域,開源深度學習框架已經成為開發者離不開的平臺和工具。
學界和業界的共同努力下,誕生了早期從學術界走出的 Caffe、 Torch 和 Theano,現如今引領著產業界的 TensorFlow,Amazon 押注的 MXNet,Facebook 傾力打造的 PyTorch,Microsoft 內部開源的 CNTK,以及相對小眾的深度學習引擎 DSSTNE 等深度學習框架。
簡單梳理一下這些主流深度學習框架發展的歷程,我們會發現它們各有各的特性:

TensorFlow 由 Google 于 2015 年 11 月正式開源,很快就成為深度學習領域占據絕對統治地位的深度學習框架,很多企業的產品都基于這一框架開發,如小米、京東、Airbnb 等。TensorFlow 全面的開發語言和模型訓練服務器、移動設備支持,使得其成為產業界采用最多的深度學習框架。
MXNet 項目誕生于 2015 年 9 月,當時在卡耐基梅隆大學 CMU 讀博的李沐創造了這個輕量級、可移植、靈活的分布式的開源深度學習框架,后成為 Amazon 官方主推的深度學習框架,支持 CNN、RNN、LTSM,為圖像、手寫文字和語音的識別和預測以及自然語言處理提供了出色的工具。
Keras 的創造者是谷歌 AI 研究員 Francois Chollet,自 2015 年 11 月開源以來,已發展成為第二大流行深度學習框架。這個由 Python 編寫的開源人工神經網絡庫可以作為 Tensorflow 、CNTK 和 Theano 的高階應用程序接口,進行深度學習模型的設計、調試、評估、應用和可視化,目標是只需幾行代碼就能讓你構建一個神經網絡。
2016 年,微軟開發的認知工具包 CNTK 問世,支持 RNN 和 CNN 類型的神經模型,成為處理圖像,手寫和語音識別問題的最佳候選者。雖然 CNTK 的分布式計算性能較高,但缺乏對 ARM 架構的支持限制了其在移動設備上的功能。
2017 年,Facebook 開源了用于神經網絡訓練的 Python 包 PyTorch,它改編自基于 Lua 的深度學習庫 Torch,類似于 Numpy,非常 Python 化,很容易就能和 Python 生態系統的其他部分集成。由于對動態圖的支持, PyTorch 的靈活性相比 TensorFlow 大大提升,特別是用于快速驗證和算法復現,因此備受學術界的青睞。
有了這些功能強大的開發框架,AI 開發者基本上也都會用之進行科研或業務落地。但是在人工智能領域,大家使用比較多的還是 Google、Facebook、微軟、亞馬遜的開源框架,國內雖然有很多互聯網巨頭都在開始這方面的工作,但目前還沒有形成風潮。
2016 年,互聯網巨頭百度開源了飛槳(PaddlePaddle),可能是國內目前最有影響力的 AI 框架;2019 年,通訊行業巨頭華為宣布即將在 2020 年一季度開源 MindSpore,但目前仍無進一步消息;3 月 25日,曠視研發的深度學習框架天元(MegEngine)正式開源。
與主流深度學習框架相比,曠視的 MegEngine 有哪些特點呢?

唐文斌介紹,本次曠視天元共開源約 35 萬行代碼,包括 C++、CUDA 和 Python 的代碼。

天元是一套伴隨曠視自身 AI 產業實戰經驗的框架,是曠視 Brain++ 的核心組件之一。為了這次開源,曠視為天元做了一次全面的升級。
從 2014 年開始研發,2015 年全員使用,到今年 3 月開源,曠視目前所有的算法都是基于天元 MegEngine 這個框架訓練和推理的。它不僅能夠在 AI競賽擂臺上為曠視打怪升級加 Buff,更撐起了曠視工程化、產品化的半邊天。
發布會上,天元項目的負責人,也是曠視研究院高級技術總監田忠博指出,天元是一套訓練推理一體化、動靜態合一的工業級深度學習框架。

從上到下,天元可以分為五個層次,最上面是計算接口層,向外連接了 Python 和 C++ 接口,開發者可以通過 Python 和 C++ 兩種語言對整個框架進行使用和編程,以及系統的設計和研發、訓練和推理。
再往下是一個完整的一體化核心計算引擎,具有自動求導機制,圖優化和圖編譯功能,有了這個層次就可以支撐起動態、靜態和接口完整的功能。
在這個層次之下的運行時管理層由兩個主要部分組成,一部分是計算調度,可以將計算設備抽象為執行流,由調度器對這些執行流進行合理的調度;另一部分是一整套內存管理機制,包括靜態內存和動態內存管理。此外,這個模塊里還內置了許多關于內存的高級優化,其中值得一提的是,在其中實現了靜態的亞線性內存的優化器,使得內存管理效率得到大幅提升。
最底層是支撐整個系統的核心計算內核層,其中包含一個高性能算子庫,它支持常見的計算設備,包括 X86、CUDA、ARM 和專業計算芯片等。同時,這個層還包含一個高性能異構通信庫,能夠使得整個計算框架可以在分布式多結點上進行大規模使用,來支撐更大規模的訓練。


曠視研究院高級技術總監 田忠博
在過去幾年,曠視在研發過程中遇到了很多行業共通的痛點,而天元的核心特色就是緊緊圍繞著這些痛點的。
具有來說,天元四大核心特性:訓練推理一體化、動靜合一、兼容并包和靈活高效。
-
比如其中的一個痛點,是深度學習從研究到生產的流程非常復雜,各個階段模型精度往往很難對齊。
田忠博指出,在傳統深度學習研發流程中,訓練框架和推理框架往往會分別設計和實現,訓練框架和推理框架是兩個階段,當進行算法設計時,這個算法要首先經過訓練框架的支持,變成一個可訓練的模型,還要再把它轉換到一個推理框架上可以接受新的表示,再由推理框架在不同的計算設備上進行計算。
在這里會有一個訓練和推理的轉換過程,這一過程中會產生很多問題,比如因為訓練框架和推理框架是分別設計的,所以其中有些算力可能不被支持,導致無法自動完成轉換,需要手工進行優化,轉換過程中也可能引入了大量冗余的算子,致使最后的模型性能和精度并不理想。當最后把推理框架投放在芯片上進行計算時問題暴露,但因為整個流程復雜,我們無法精準地找到問題所在。
因此,天元框架的設計理念,就是希望訓練和推理一體,即讓它能夠同時進行訓練,也能夠進行推理。
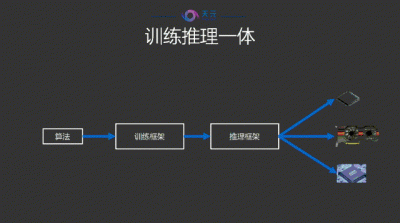
針對這個痛點,天元的訓練推理一體化可以很好地解決。
(1)它無需進行模型的轉換,可以直接使用訓練后得到的模型進行推理;
(2)可以通過這一機制,保證訓練的速度和精度與推理保持一致;
(3)模型訓練結束后,需要在不同的設備上進行推理、使用,該框架也能夠保證跨設備的模型精度實現對齊(最小化精度差別);
(4)通過簡化流程,天元框架能夠內置一個自動模型優化過程,減少手工模型遇錯處理,可以直接自動使用內置流程,簡化流程,形成高效的研發體系。
這樣一來,AI 真正落地要考慮的多端部署和在線服務的問題就得以解決,大大減少了訓練成本的問題。
-
痛點二,靜態圖好部署,動態圖易調試,但二者難以兼得。田忠博介紹道,深度學習框架大致分為兩類,一類是以 TensorFlow 1.0 為代表的靜態深度學習框架,它非常容易部署,能夠很快地產出產品,是現在工業界非常喜歡的部署方式,它的性能高,占用資源少,但是難以調試。在學界,大家更喜歡以 PyTorch 為代表的動態計算框架,因為它在研究階段調試更方便,使用更靈活,但是動態圖也有缺陷,比如內存占用嚴重,很難做優化等。
面對這個魚與熊掌不可兼得的問題,曠視嘗試把兩種框架的優點集成在一起,在設計天元時希望能夠達到動靜合一的效果。
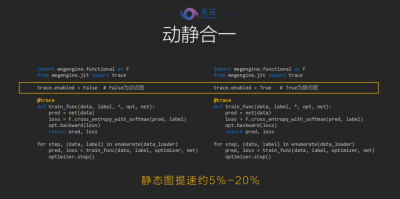
上圖展示的是天元框架代碼中從動態到靜態切換的情況。可以看到,通過使用一個 @trace 的 Python 裝飾器來裝飾其中一段函數,實現了這段函數具備既可在動態下正確運行,也可以轉換到靜態形態運行的狀態。只需把「Enabled」開關設為True或者False,用戶就可以自由選擇動態或靜態計算。
這樣,開發者就可以在動態的過程中,非常方便地進行原型的研發和調試,同時當希望在生產環節使用,或希望借助更好的靜態優化器、靜態編譯機制進行提速時,可借助靜態圖進行提速。
田忠博表示,在測試中,靜態提速往往可以達到 5% 到 20% 的加速效果,節省時間,提高效率。
-
第三個痛點,是市面上有很多框架,但每種框架使用的接口都不一樣,這導致大家在進行學術交流時,首先要了解它是用什么框架實現的,在使用中還需要在常用的環境和框架中再重新進行模型實現,這對于一般的開發者來講是一件高成本的事。
因此,為了簡化這個問題,天元在設計時還希望它是一個兼容并包的體系。

上圖為使用天元框架進行深度學習的代碼,它的風格與Numpy 和 PyTorch 的寫法非常相似,Pythonic 風格的簡化 API 讓 Python 使用者可以自然地接受,所以在函數的命名風格和參數的設計細節中尊重原有 Python 社區的傳統。
值得一提的是,天元還提供一個實驗性的功能,讓開發者可以便利地將以往寫過的模塊,如 將PyTorch Module 直接導入到框架中,和其他天元組件一起使用,以更好地進行模型復現。
另外,田忠博提到,曠視在計算機視覺領域有一些獨特的積累,因此也把其在這方面的成果融入到天元系統中,集成了很多為計算機視覺特別優化的算子,讓計算機視覺研發更加簡便。
-
痛點四,對于一家進 AI 生產公司來說,可能會面臨很多設備和場景,需要在每一種設備上實現極致的性能。
在框架設計時,天元秉持要靈活高效的原則,在許多的設備、算法上,都能得到領先的性能。接下來,田忠博放出了訓練性能對比圖,與若干擅長推理的框架進行橫向對比。
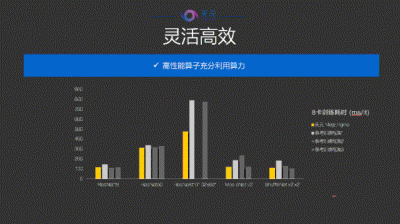
結果顯示,在 CPU 推理場景下,天元在訓練性能上有顯著的提升和優勢,即可以同時在訓練和推理過程中保持高性能。另外,如果要把算法更好地部署在各種設備中,或者在訓練時能夠利用現有的設備訓練更大的模型,支持更多的算法種類,顯存或設備的片上內存使用是一個非常關鍵的因素。所以,節省內存也是天元所關注的。
天元內置了一個高效的內存優化策略,它能夠顯著減少訓練時的顯存占用,實現在同樣的設備上可以訓練更大的模型,支持更多算法。
此外,天元還有很多內存和速度的優化機制,比如亞線性內存優化。可以發現,在使用天元動態圖能力時,可以支持 32 Batch 左右的計算;如果轉換到靜態圖下,就可以支持 64 Batch 的計算。那么,如果希望在這種情況下,訓練更大的 Batch 和模型,則完全可以在這里采用亞線性自動內存優化技術,在幾乎不降低計算速度前提下,達到 256 Batch 的訓練能力,而且模型越大、越深,它的效果越好。
田忠博表示,在內部評測中,天元可以實現某些大模型訓練時內存節省 20 倍以上,而速度幾乎不變。
這些特性,使得天元能夠實現產品從實驗室原型到工業上能夠部署的小時級轉化能力,以及大規模的、彈性的訓練,并支撐頂級研究團隊進行最前沿的學術開發。
這樣,天元可以做到“簡單開發”,讓開發者真正體驗到“訓得好”、“訓得動”、“訓得快”。

從 Theano 為源頭,到不斷迭代到今天發布的MegEngine Alpha 版本,天元的誕生來之不易,背后是曠視研究院團隊從 0 到 1 的打磨過程。
曠視成立初衷是希望把計算機視覺應用于傳統產業,用技術改變世界。當 2013 年中深度學習剛剛興起之時,清華宿舍中一名實習生埋首兩周,研發出一套人臉識別檢測算法,算法性能技驚四座,于是曠視正式走上用神經網絡解決一切問題的道路。
起初,曠視用 Theano 框架寫模型代碼,訓練神經網絡,但隨著網絡越訓越大,越來越復雜,低效耗時的框架令人崩潰,公司中的一些大牛開始琢磨其他的辦法。
2013 年底,曠視當時的研發負責人曹志敏提出打造一套能夠打通數據、訓練和業務的自動化算法研發系統 Cycle++,不需要投入過多人力和時間就可以實現算法從研發到應用的自循環體系(曠視 Brain++的早期設想)。于是,2014 年初,曠視自研的初版深度學習框架誕生了。
經過磨合,曠視在 2015 年年中完成了自研框架與公司內部所有業務的接軌,公司業務線上的模型全部換成了自研框架訓練出來的版本。
2015 年 11 月 9 日,Google 正式發布并開源 TensorFlow,曠視發現原來他們是殊途同歸,都是基于計算圖的方式來做框架,但這也給曠視的自研框架造成很大沖擊,公司內部在是否要繼續堅持自研框架上發生分歧。經過激烈的討論和詳細的評測后,曠視發現當時的TensorFlow 的性能并不理想,竟比自研框架要慢若干倍。最終曠視選擇了堅持自研的道路。
此后,經過不斷迭代,同時在工業實踐的鍛煉中,除了最底層的框架,曠視也在同時進行數據和算力基礎設施的變革。2013 年,曠視研究院成立了自己的數據團隊,隨著業務數據的暴增,數據管理不斷出現問題,曠視又開始建立自己的數據管理系統 MegData。
2015 年底,天元MegEngine 已經進入了穩步發展期,但公司“小作坊”模式開始扛不住業務需求,計算資源成為瓶頸問題,于是曠視建設了“正經的機房”,研發出深度學習云計算平臺 MegCompute,并僅用一個季度的時間完成了業務從單機到集群的徹底遷移。
曠視從研發到業務全面向自有深度學習框架和自有計算集群的遷移,標志著曠視數據、算法和算力三個核心組件正式完成“大一統”,自此曠視 AI 生產力平臺 Brain++ 雛形初現。
2016 年,曠視開始組建大規模的團隊持續優化 Brain++ 的整個套件開發流程,2019 年開始籌備將 Brain++ 最核心的深度學習框架開源,并為 MegEngine 起了一個中文名字——天元。這期間框架研發團隊可以說是經歷了一場浴火重生,把原來封裝好的代碼分解再重組,讓開發者上手更快。
經過一年的籌備,天元今天終于如期開源,賦能開發者。未來,天元還有更多計劃,發布會現場曠視就首次曝光了天元的開發路線圖。

田忠博表示,本次曠視開源的天元是 Alpha 版本,未來的開發計劃是在今年 6 月份發布 Beta 版本,屆時天元將提供ARM 系列 CPU 支持,更多的加速設備支持,以及量化和低比特計算支持;到 9 月 份發布正式 1.0 版本時,天元支持的主流計算設備將更全面,動態能力升級,并優化訓練推理全流程使用體驗。
他說,在 Beta 版本和正式版本之間,希望更多人能夠參與并貢獻 code,“也許下一代天元并不是由曠視的研發團隊做出來的,而是與你一起共創出來的 Beta 和正式版本,所以我們也希望跟大家一起來共建更好的深度學習框架。”

了解萬天元的架構、技術細節和曲折的研發背景及研發全景圖,下面該進入“靈魂提問”環節了:曠視這個深度學習開源框架到底好不好用?為什么我要從已經熟悉的 NumPy、TensorFlow、PyTorch 、Keras 或其他框架轉而學習天元?這個學習過程難嗎?
對此,田忠博打消了大家的疑慮,他表示,在整個框架接口設計和使用習慣上,天元尊重以往大家在傳統的 PyTorch 機器學習和數學計算使用方面的習慣,在整體設計和框架完善過程中盡量減少阻力,讓大家更容易上手。
值得注意的是,此次發布的內容里已經包含了一些工具,如開箱即用的在線深度學習工具 MegStudio,它能夠讓開發者便捷、快速地體驗天元框架,進行深度學習訓練。
而壓縮和部署工具等周圍支持模塊的量化工具還在繼續整理中,預計在年中會和大家見面,系統的可視化工具和可視化系統的集成則會更晚一些。
在開源文檔維護方面,田忠博表示基礎能力手冊和代碼是同步進行研發的,曠視會有內部流程確保文檔維護并保證文檔質量,希望有更多志愿者加入,共同維護修正。
同時,天元還提供一個模型中心 ModelHub,匯聚頂尖算法的預訓練模型,并把曠視研究院的最新技術和研發成果發布到該平臺。曠視表示,更多 SOTA 的模型正在增加中。
從無到有,從“授人以魚”到“授人以漁”,曠視滿懷誠意,正在通過開放 Brain++,嘗試為 AI 打造一套 Visual Studio,將 AI 能力帶給更多開發者,在算法研究的“煉丹”過程中,提供一套設備完善的“煉丹房”,至于煉丹的原材料和柴火,那就需要用戶按需自取了。
在發布會上,曠視公布了天元在 GitHub 的代碼托管地址,想了解體驗如何不如直接試試吧!
GitHub:https://github.com/MegEngine/MegEngine
想盡快上手一試?可進入天元官方網址體驗https://megengine.org.cn/












 京公網安備 11010502049343號
京公網安備 11010502049343號