



在介紹 Agora Lipsync 技術(shù)前,我們先來(lái)簡(jiǎn)單了解下目前行業(yè)比較類(lèi)似的兩類(lèi)技術(shù):Oculus Lipsync,Oculus Lipsync是一種 Unity 集成,用于將虛擬角色的唇部動(dòng)作同步至語(yǔ)音。它主要是離線或?qū)崟r(shí)分析音頻輸入,然后預(yù)測(cè)用于令虛擬角色或非玩家角色(NPC)嘴唇動(dòng)畫(huà)化的一組發(fā)音嘴型,為了提升音頻驅(qū)動(dòng)面部動(dòng)畫(huà)的準(zhǔn)確性,Oculus Lipsync 利用一個(gè)神經(jīng)網(wǎng)絡(luò)模型來(lái)學(xué)習(xí)語(yǔ)音和音素之間的映射關(guān)系。通過(guò)模型把輸入音頻轉(zhuǎn)為音素,音素能夠?qū)?yīng)到特定的視覺(jué)音素,再基于 Unity 集成技術(shù)實(shí)現(xiàn)虛擬角色嘴唇和面部的姿勢(shì)和表達(dá)。該技術(shù)主要應(yīng)用于虛擬主播與游戲領(lǐng)域。
面部捕捉技術(shù),在當(dāng)下很多發(fā)布會(huì)與活動(dòng)會(huì)議都運(yùn)用到了全息影像,嘉賓在舞臺(tái)之外身穿特定的硬件設(shè)備,他的肢體動(dòng)作與演講的嘴型動(dòng)作都會(huì)實(shí)時(shí)同步在舞臺(tái)大屏幕中的虛擬形象中,其中想要實(shí)現(xiàn)唇音同步,就需要運(yùn)用到關(guān)鍵的面部表情捕捉技術(shù)與相關(guān)的硬件設(shè)備。
相比這兩種技術(shù),聲網(wǎng)的 Agora Lipsync 有著核心區(qū)別, Agora Lipsync 無(wú)需攝像頭、無(wú)需面部表情捕捉技術(shù),而是通過(guò)深度學(xué)習(xí)算法中的生成對(duì)抗網(wǎng)絡(luò),將中英文(或其他語(yǔ)種)發(fā)音的嘴型、面部表情智能關(guān)聯(lián)起來(lái),驅(qū)動(dòng)人像模擬真人說(shuō)話嘴型,支持2D人像圖片和3D人像模型。
接下來(lái),我們將重點(diǎn)揭秘 Agora Lipsync 實(shí)現(xiàn)語(yǔ)音驅(qū)動(dòng)嘴型運(yùn)動(dòng)背后的技術(shù)原理。
生成對(duì)抗網(wǎng)絡(luò)+模型輕量化實(shí)現(xiàn)語(yǔ)音信號(hào)驅(qū)動(dòng)人像嘴型運(yùn)動(dòng)
語(yǔ)音驅(qū)動(dòng)嘴型技術(shù),顧名思義,通過(guò)說(shuō)話人的語(yǔ)音音頻信號(hào),來(lái)驅(qū)動(dòng)靜態(tài)人臉頭像的嘴部運(yùn)動(dòng),使得生成的人臉頭像嘴部狀態(tài)與說(shuō)話人的語(yǔ)音高度匹配。實(shí)時(shí)語(yǔ)音驅(qū)動(dòng)人臉圖像說(shuō)話這項(xiàng)技術(shù)的實(shí)現(xiàn)需要克服諸多挑戰(zhàn),首先要找到語(yǔ)音信息和人臉信息之間的對(duì)應(yīng)關(guān)系,音素是我們?nèi)苏f(shuō)話的最小可發(fā)音單元,可以通過(guò)音素去找到對(duì)應(yīng)的嘴型,但是發(fā)出相同音素的嘴型狀態(tài)不止一個(gè),再加上不同的人面部特征、說(shuō)話狀態(tài)也會(huì)存在差異,所以這是一個(gè)復(fù)雜的一對(duì)多問(wèn)題。其次還會(huì)面臨一些其他挑戰(zhàn),包括生成的說(shuō)話人臉是否失真,以及說(shuō)話人臉嘴型變化是否流暢等等。此外,如果是在低延時(shí)的實(shí)時(shí)互動(dòng)場(chǎng)景下使用,還需要考慮計(jì)算量復(fù)雜度等問(wèn)題。

圖1:例如a這個(gè)音素,發(fā)音的嘴型張合程度都不是唯一的
傳統(tǒng)的 Lipsync(唇音同步)方法可以通過(guò)語(yǔ)音處理結(jié)合人臉建模的方式實(shí)現(xiàn),然而語(yǔ)音能夠驅(qū)動(dòng)的口型數(shù)量往往比較有限,而聲網(wǎng)的 Agora Lipsync 通過(guò)深度學(xué)習(xí)算法,可以實(shí)現(xiàn)實(shí)時(shí)生成說(shuō)話人臉圖像。目前,深度學(xué)習(xí)算法隨著數(shù)據(jù)規(guī)模的增加不斷提升其性能,通過(guò)設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)可以從數(shù)據(jù)中自動(dòng)提取特征,削減了對(duì)每一個(gè)問(wèn)題手動(dòng)設(shè)計(jì)特征提取器的工作。深度學(xué)習(xí)目前已經(jīng)在計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理等多個(gè)領(lǐng)域大放異彩。
在實(shí)現(xiàn)語(yǔ)音驅(qū)動(dòng)人臉圖像任務(wù)中,我們需要將語(yǔ)音一維信號(hào)映射到圖像二維像素空間。聲網(wǎng)使用了深度學(xué)習(xí)中的生成對(duì)抗網(wǎng)絡(luò)(GAN),GAN的思想來(lái)自零和博弈理論,由兩個(gè)部分組成,一個(gè)是生成器Generator,接收隨機(jī)噪聲或者其他信號(hào)用來(lái)生成目標(biāo)圖像。一個(gè)是判別器 Discriminator,判斷一張圖像是不是“真實(shí)的”,輸入是一張圖像,輸出是該圖像為真實(shí)圖像的概率。生成器的目標(biāo)是通過(guò)生成接近真實(shí)的圖像來(lái)欺騙判別器,而判別器的目標(biāo)是盡量辨別出生成器生成的假圖像和真實(shí)圖像的區(qū)別。生成器希望假圖像更逼真判別概率高,而判別器希望假圖像再逼真也可以判別概率低,通過(guò)這樣的動(dòng)態(tài)博弈過(guò)程,最終達(dá)到納什均衡點(diǎn)。大自然里就存在很多生成對(duì)抗的例子,在生物進(jìn)化的過(guò)程中,被捕食者會(huì)慢慢演化自己的特征,從而達(dá)到欺騙捕食者的目的,而捕食者也會(huì)根據(jù)情況調(diào)整自己對(duì)被捕食者的識(shí)別,共同進(jìn)化。
基于GAN的深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練完成之后,生成器可以將輸入信號(hào)轉(zhuǎn)化并生成逼真的圖像。對(duì)此,聲網(wǎng)設(shè)計(jì)了針對(duì)語(yǔ)音驅(qū)動(dòng)圖像任務(wù)的深度學(xué)習(xí)模型,利用大規(guī)模視頻語(yǔ)料數(shù)據(jù),使得模型可以根據(jù)輸入的語(yǔ)音生成說(shuō)話人臉。模型內(nèi)部對(duì)輸入的語(yǔ)音與圖像兩種不同模態(tài)的信號(hào)進(jìn)行特征提取,得到相應(yīng)的圖像隱向量與語(yǔ)音隱向量,并進(jìn)一步學(xué)習(xí)到兩種跨模態(tài)隱向量之間的隱式映射關(guān)系,從而根據(jù)這種關(guān)系將隱向量特征重建成為和原始音頻相匹配的說(shuō)話人臉圖像。除了生成圖像是否逼真,還要考慮時(shí)序穩(wěn)定性和音畫(huà)匹配度,對(duì)此我們?cè)O(shè)計(jì)了不同的損失函數(shù)在訓(xùn)練中加以約束。整個(gè)模型推理計(jì)算過(guò)程是端到端實(shí)現(xiàn)的。
同時(shí),Agora Lipsync 還適配中、日、德、英文等多語(yǔ)種語(yǔ)音以及多種膚色人群,滿(mǎn)足不同國(guó)家與地區(qū)的用戶(hù)體驗(yàn)。
我們可以通過(guò)下方的圖2更直觀的了解生成對(duì)抗網(wǎng)絡(luò)是如何端到端地學(xué)習(xí)生成說(shuō)話人臉頭像。
圖2可以分為4個(gè)流程:1、深度學(xué)習(xí)模型中的 Generator 生成器接收一張人臉圖像和一小段語(yǔ)音,經(jīng)過(guò)生成器內(nèi)部的特征提取與處理生成一張偽造的人像圖片(Fake image)。2、圖中的“Real Data”指的是用于訓(xùn)練的視頻序列,從中取出和 Audio 相匹配的目標(biāo)圖像。將目標(biāo)圖像和 Generator 生成的 Fake Image 比較它們的差異,根據(jù)損失函數(shù)通過(guò)反向傳播進(jìn)一步更新生成器中的模型參數(shù),從而讓生成器學(xué)習(xí)得更好,生成更加逼真的 Fake Image;3、比較差異的同時(shí),將 Real Data 中的目標(biāo)圖像與 Fake Image 輸入到 Discriminator 判別器中,讓判別器學(xué)習(xí)區(qū)分真?zhèn)危?、整個(gè)訓(xùn)練過(guò)程中生成器與判別器相互對(duì)抗,相互學(xué)習(xí),直到生成器和判別器的性能達(dá)到一種平衡狀態(tài)。最終生成器將會(huì)生成更為接近真實(shí)人臉嘴型狀態(tài)的圖像。
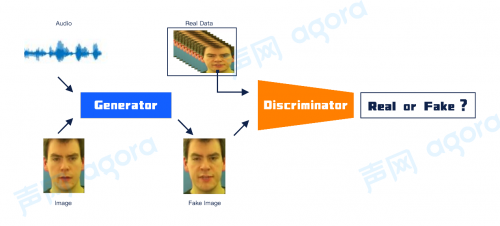
圖2:生成對(duì)抗網(wǎng)絡(luò)如何生成對(duì)應(yīng)的人臉圖像
深度學(xué)習(xí)模型可以端到端的生成說(shuō)話人臉圖像,但是往往計(jì)算量和參數(shù)量較大,由于存儲(chǔ)和功耗的要求,在低資源下實(shí)時(shí)應(yīng)用該算法仍然具有一定的挑戰(zhàn)性。目前常用的一些模型輕量化技術(shù)有人工設(shè)計(jì)輕量化結(jié)構(gòu)、神經(jīng)架構(gòu)搜索、知識(shí)蒸餾以及模型剪枝等等。在 Agora Lipsync 的語(yǔ)音驅(qū)動(dòng)嘴型任務(wù)中,聲網(wǎng)設(shè)計(jì)的模型本質(zhì)上是一個(gè)圖像生成模型,體量相對(duì)較大,我們通過(guò)模型輕量化技術(shù),設(shè)計(jì)了端到端的輕量化語(yǔ)音驅(qū)動(dòng)圖像模型,只需要傳輸語(yǔ)音流就可驅(qū)動(dòng)靜態(tài)圖像生成說(shuō)話人臉,在保證效果的基礎(chǔ)上大大地縮小了模型的計(jì)算量和參數(shù)量,從而滿(mǎn)足移動(dòng)端的落地需求,通過(guò)輸入語(yǔ)音信號(hào),能夠?qū)崟r(shí)驅(qū)動(dòng)一張靜止人臉圖像產(chǎn)生嘴部運(yùn)動(dòng),達(dá)到音畫(huà)同步的效果。
介紹完 Agora Lipsync 的技術(shù)原理,我們?cè)賮?lái)看它的應(yīng)用場(chǎng)景有哪些,相比于元宇宙虛擬世界與真實(shí)的視頻社交場(chǎng)景,Agora Lipsync 填補(bǔ)了在語(yǔ)音社交場(chǎng)景,不打開(kāi)攝像頭,卻能體驗(yàn)真人視頻連麥既視感的場(chǎng)景玩法空白,在語(yǔ)聊房、互動(dòng)播客、視頻會(huì)議等場(chǎng)景中具有巨大的應(yīng)用價(jià)值。
語(yǔ)聊房:在傳統(tǒng)的語(yǔ)聊房中,用戶(hù)通常會(huì)選擇真人頭像或者虛擬的頭像進(jìn)行語(yǔ)音連麥,往往需要通過(guò)有話題性、趣味性的聊天內(nèi)容才能保障語(yǔ)聊房間的內(nèi)容質(zhì)量與時(shí)長(zhǎng)性,而通過(guò)加入語(yǔ)音驅(qū)動(dòng)嘴型運(yùn)動(dòng)的技術(shù),可以在形式上讓聊天過(guò)程更具生動(dòng)性與趣味性,對(duì)于不想打開(kāi)攝像頭的玩家,可以選擇一張自己好看的或者搞怪的照片作為頭像,這樣大家不打開(kāi)攝像頭,也能看到彼此的人臉頭像仿佛在真實(shí)的說(shuō)話,最終增加了玩家在語(yǔ)聊房中進(jìn)一步聊天的動(dòng)力。
互動(dòng)播客:去年以Clubhouse為代表的互動(dòng)播客平臺(tái)曾風(fēng)靡全球,相比傳統(tǒng)的語(yǔ)聊房,互動(dòng)播客平臺(tái)的話題內(nèi)容、用戶(hù)關(guān)系有著明顯的差別,播客房間的聊天話題主要以科技、互聯(lián)網(wǎng)、職場(chǎng)、創(chuàng)業(yè)、股市、音樂(lè)等話題為主,用戶(hù)上傳自己真人頭像的意愿也非常高,通過(guò)加入語(yǔ)音驅(qū)動(dòng)嘴型運(yùn)動(dòng)技術(shù),可以讓用戶(hù)之間的聊天更具參與感與真實(shí)感。
視頻會(huì)議:在視頻會(huì)議場(chǎng)景中往往都會(huì)要求參會(huì)用戶(hù)盡量都打開(kāi)攝像頭,然而經(jīng)常會(huì)遇到部分用戶(hù)不方便打開(kāi)攝像頭,造成有人開(kāi)視頻、有人開(kāi)語(yǔ)音的會(huì)議場(chǎng)景,通過(guò) Agora Lipsync 一方面可以讓無(wú)法打開(kāi)攝像頭的用戶(hù)避免尷尬,通過(guò)驅(qū)動(dòng)人臉頭像的嘴部運(yùn)動(dòng)營(yíng)造出仿佛是真人參加視頻會(huì)議的場(chǎng)景感。另一方面,通過(guò)語(yǔ)音驅(qū)動(dòng)人臉說(shuō)話的方式,視頻會(huì)議傳輸可以不用傳輸視頻流,只需要語(yǔ)音流,特別是在弱網(wǎng)條件下,不僅避免了畫(huà)面卡頓或延遲,同時(shí)也減少了傳輸成本。
目前 Agora Lipsync 技術(shù)主要支持2D人像圖片和3D人像模型,未來(lái)在聲網(wǎng)算法團(tuán)隊(duì)的持續(xù)鉆研下,該技術(shù)也將進(jìn)一步升級(jí),不僅可以支持卡通頭像,還有望通過(guò)語(yǔ)音進(jìn)一步驅(qū)動(dòng)頭部、眼睛等器官的運(yùn)動(dòng),實(shí)現(xiàn)更廣泛的應(yīng)用場(chǎng)景與場(chǎng)景價(jià)值。
如您想進(jìn)一步咨詢(xún)或接入 Agora Lipsync 技術(shù),可通過(guò)聲網(wǎng)的微信公眾號(hào)找到這篇文章,點(diǎn)擊文章最下方的「閱讀原文」留下您的信息,我們將與您及時(shí)聯(lián)系,做進(jìn)一步的溝通。






Agora Lipsync 技術(shù)揭秘:通過(guò)實(shí)時(shí)語(yǔ)音驅(qū)動(dòng)人像模擬真人說(shuō)話")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)