









各位讀者,《IoT前沿》欄目已經進行了三期啦~
之前的內容里,我們已經對Pravega的特性和優勢進行了介紹,相信大家對它已經有了一個完整的了解。
現在問題來了,既然Pravega歪瑞酷,能夠解決未來流數據處理的難題,那么我要什么時候才能用上這項技術呢?
咳咳,雖然正式推出市場還在戴爾易安信的計劃之中...
但是,Pravega的發行版已經開放,可以供大家下載使用了!
俗話說“眼過百遍不如動手一遍”,Pravega說得再好,那也是王婆賣瓜,不如讓各位讀者親自動手部署一番,因此在今天的這篇文章里,我們將為大家詳細介紹Pravega的部署方法。
Pravega從入門到精通,從這里開始~
作者簡介

滕昱
滕昱:就職于Dell EMC中國研發集團,非結構化數據存儲部門團隊并擔任軟件開發總監。2007年加入Dell EMC以后一直專注于分布式存儲領域。參加并領導了中國研發團隊參與兩代Dell EMC對象存儲產品的研發工作并取得商業上成功。從2017年開始,兼任Streaming存儲和實時計算系統的設計開發與領導工作。

劉晶晶
劉晶晶:現就職于DellEMC,10 年+分布式、搜索和推薦系統開發以及架構設計經驗,現從事流存儲相關的設計與開發工作。

周煜敏
周煜敏:復旦大學計算機專業研究生,從本科起就參與Dell EMC分布式對象存儲的實習工作。現參與Flink相關領域研發工作。
Pravega屬于戴爾科技集團IoT戰略下的一個子項目。該項目是從0開始構建,用于存儲和分析來自各種物聯網終端的大量數據,旨在實現實時決策。其結合了戴爾易安信PowerEdge服務器,并無縫集成到非結構化數據產品組合Isilon和Elastic Cloud Storage(ECS)中,同時擁抱Flink生態,以此為用戶提供IoT所需的關鍵平臺。
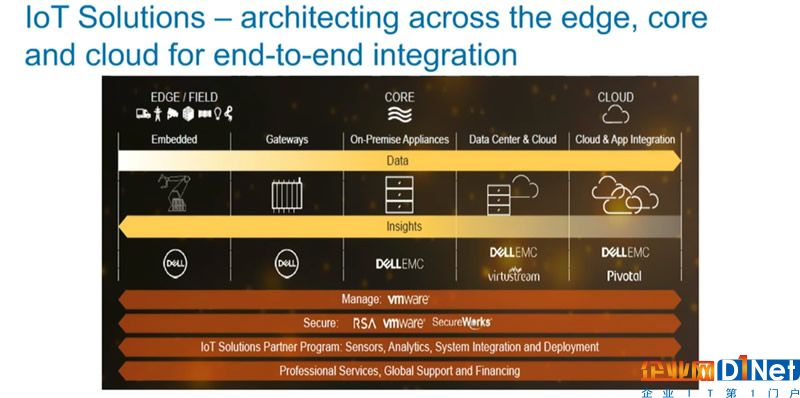
戴爾科技集團IoT解決方案集合了戴爾科技家族的力量,覆蓋從邊緣到核心再到云端
1云原生與Pravega
隨著容器技術和云服務的發展,Kubernetes和云原生已經重定義了應用設計和開發的一些方面。
Pravega從設計之初就是云原生應用,可以在各大公有/私有云平臺上進行部署和運行。
• 它的組件都是以低耦合的微服務形式存在,通過運行多個服務實例保證高可用性。
• 每個服務實例運行于單獨的容器中,使用容器實現服務的相互隔離。
• 可以使用容器編排工具(如Kubernetes)進行統一的服務發現、治理和編排,提高資源利用率,降低運營成本。
同時,Pravega團隊通過第三方資源機制擴展了Kubernetes的API,開發了能夠使得Pravega集群的創建、配置和管理更高效和自動化的Operator,包括 Pravega Operator和Zookeeper Operator,通過他們可以使得Pravega在Kubernetes環境中快速創建集群和動態擴展。這些Operator以及其他相關的容器鏡像會上傳至Pravega在DockerHub官方的鏡像倉庫:https://hub.docker.com/u/pravega中,用戶也可以直接拉取使用,源代碼也在GitHub網站:https://github.com/pravega上公開。
2Pravega核心組件及交互
Pravega能夠以一致的方式靈活地存儲不斷變化的流數據,主要得益于控制面(Control Plane)和數據面(Data Plane)的有機結合。兩者都由低耦合的分布式微服務組件管理,前者主要由控制器(Controller)實現,后者主要由段存儲器(Segment Store)實現,它們通常以多實例的形式運行在集群中。除此以外,一個完整的Pravage集群還包括一組Zookeeper實例,一組Bookkeeper實例,以及用于提供第二層的存儲的服務或接口。 它們的關系如圖:
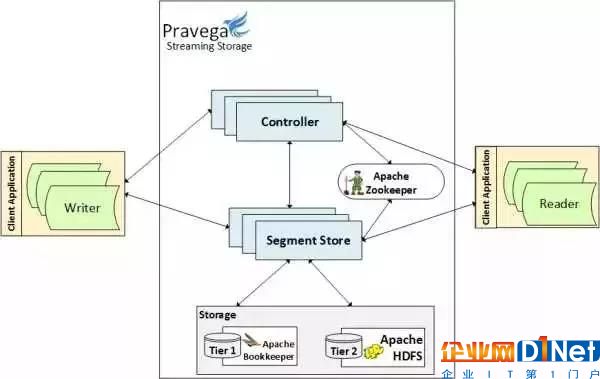
控制器是Pravega的控制中心,對外提供 JAVA 和 REST 接口,接收客戶端對于Stream的創建、刪除、讀寫等請求;對內負責Segment的管理和集群的管理。客戶端對于Stream的讀寫請求在控制器中被分拆為對Segment的請求,控制器確定需要使用哪些Segment,從而分發給相應的段存儲器來操作。
段存儲器(Segment Store)提供了Segment的管理入口,實現了Segment的創建、刪除、修改和讀取功能。數據被存儲在一層和二層存儲上,由段存儲器負責數據的存儲和降層操作。其中一層存儲由低延遲的Bookkeeper擔任,通常運行于集群的內部;二層存儲由容量大且成本較低存儲的擔任,一般運行于集群的外部。
Zookeeper做為集群的協調者, 它維護可用的控制器和段存儲器列表,控制器會監聽它們的變化。當一個控制器從集群中刪除時,它的工作會被其他的控制器自動接管。當段存儲器發生變化時,控制器也會將段容器重新映射以保證系統的正常運行。
3Pravega的部署
了解Pravega最好方法就是自己動手部署一個,然后跑一下Pravega示例程序:
https://github.com/pravega/pravega-samples
單機版部署
單機版部署是最快捷的方式,你只需要從Pravega Release Github:https://github.com/pravega/pravega/releases下載一個Pravega發行版,解壓后運行:
bin/pravega-standalone
單機版部署只能用來學習和測試,不能用于生產環境中,程序一旦關閉所有的數據也會丟失。
集群部署
Pravega可以運行于多個主機所組成的集群中,也可以運行于云平臺中。這里我們只介紹Kubernetes環境下的部署,其他的方式參考:
http://pravega.io/docs/latest/deployment/deployment/
運行之前,需要保證你擁有一套Kubernetes環境,可以是公有云上的Kubernetes服務(如GKE,Amazon EKS),或者是分布式集群上自建的Kubernetes環境(如通過Kubeadm),以及命令行工具kubectl,helm。
1首先,在你的Kubernetes環境中創建一個Zookeeper集群。
Zookeeper集群可以使用Zookeeper Operator來創建,你可以直接使用deploy文件夾中的資源描述文件來部署。
git clone https://github.com/pravega/zookeeper-operator && cd zookeeper-operator
# 創建名為 ZookeeperCluster 的自定義資源定義(custom resource definition)
kubectl create -f deploy/crds/zookeeper_v1beta1_zookeepercluster_crd.yaml
# 創建 Zookeeper Operator 的服務賬號、角色和角色綁定,并部署 Zookeeper Operator
kubectl create -f deploy/default_nsall_ns/rbac.yaml
kubectl create -f deploy/default_nsall_ns/operator.yaml
# 部署 Zookeeper 集群,根據該資源描述文件,將會創建有三個節點的 Zookeeper 集群
kubectl create -f deploy/crds/zookeeper_v1beta1_zookeepercluster_cr.yaml
2然后,為Pravega第二層存儲創建單獨的持久化存儲卷(PV)及持久化存儲卷聲明(PVC)。
這里我們使用NFS Server Provisioner:https://github.com/kubernetes/charts/tree/master/stable/nfs-server-provisioner ,其他的方式請參考Pravega Operator的自述文件。
NFS Server Provisioner是一個開源工具,它提供一個內置的NFS服務器,可以根據PVC聲明動態地創建基于NFS的持久化存儲卷。
通過helm chart創建nfs-server-provisioner,執行helm install stable/nfs-server-provisioner將會創建一個名為nfs的存儲類(StorageClass)、nfs-server-provisioner服務與實例、以及相應的服務賬戶和角色綁定。
新建一個持久化存儲卷聲明文件pvc.yaml,這里storageClassName指定為nfs。當它被創建時,NFS Server Provisioner會自動創建相應的持久化存儲卷。pvc.yaml內容如下:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pravega-tier2
spec:
storageClassName: "nfs"
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
通過kubectl create -f pvc.yaml創建該持久化存儲卷聲明,你會發現相應的持久化存儲卷也被創建。
3接著,部署一個Pravega Operator。
你可以直接使用deploy文件夾中的資源描述文件部署:
git clone https://github.com/pravega/pravega-operator && cd pravega-operator
kubectl create -f pravega-operator/deploy
這里會創建一個名為PravegaCluster自定義資源定義(Custom Resource Definition)、服務賬號、角色、角色綁定,并把Pravega Operator部署到Kubernetes集群中。
4最后,修改資源描述文件并創建Pravega集群。
資源描述文件cr.yaml指定了Zookeeper地址、各組件的實例數和存儲空間。完整文件可以從這里獲得:
https://github.com/pravega/pravega-operator/tree/master/example
apiVersion: "pravega.pravega.io/v1alpha1"
kind: "PravegaCluster"
metadata:
name: "pravega"
spec:
# 配置 zookeeper 集群的地址
zookeeperUri: example-zookeepercluster-client:2181
# 配置 bookkeeper,建議至少三個實例
bookkeeper:
replicas: 3
...
pravega:
# 配置控制器實例,建議至少兩個實例
controllerReplicas: 2
# 配置段存儲器實例,建議至少三個實例
segmentStoreReplicas: 3
# 配置第二層存儲,使用之前創建的持久化存儲卷聲明
tier2:
filesystem:
persistentVolumeClaim:
claimName: pravega-tier2
...
根據描述文件(cr.yaml)創建一個Pravega 集群:
kubectl create -f pravega-operator/example/cr.yaml
集群創建成功后,你可以通過以下命令查看集群的運行狀態:
kubectl get all -l pravega_cluster=pravega
4創建一個簡單的應用
讓我們來看看如何構建一個簡單的Pravega應用程序。最基本的Pravega應用就是使用讀客戶端(Reader)從Stream中讀取數據或使用寫客戶端(Writer)向Stream中寫入數據。兩個簡單的例子都可以在Pravega示例中的gettingstarted應用程序中找到:
https://github.com/pravega/pravega-samples/tree/master/pravega-client-examples/src/main/java/io/pravega/example/gettingstarted
要正確實現這些應用,首先了解一下Pravega是如何高效并發地讀寫Stream:
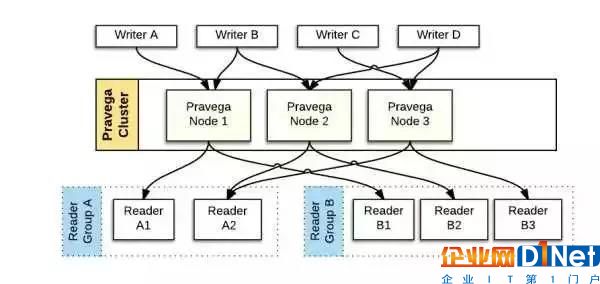
• 為了實現并發地讀寫,Stream被分為一個或多個Segment,系統可以根據I/O負載動態調整Segment的數目。
• 寫數據時,多個Writer可以同時向多個Segment追加數據而無需知道它們的變化,由路由鍵(Routing key) 保證順序的一致性。
• 路由鍵是一個字符串,控制器會根據它的哈希值而決定該事件將會被派發到哪個Segment中。具有同樣路由鍵的事件會被派發到同一個 Segment,這樣可以保證它們能以一致的順序被訪問。
• 如果Segment發生了變化,具有相同路由鍵的事件也會一致的被映射到新的Segment中。
• 讀數據時,讀者組(ReaderGroup) 中的一組Reader可以同時從不同的Segment中讀數據。
• 一個ReaderGroup包含一個或多個Reader,每個Reader從一個或多個Segment中讀數據。
• 為了保證每個事件只被讀取一次,一個Segment只能被當前ReaderGroup中的一個Reader讀。
• 一個ReaderGroup可以從一個或多個Stream中讀數據,不同的ReaderGroup是相互獨立的。
• 寫數據只能向Stream的尾部追加,讀數據可以從指定位置讀。
5使用Writer向流中寫數據
示例HelloWorldWriter舉例說明了如何使用EventStreamWriter向Stream中寫一個事件。 我們來看一下其中最關鍵的run()方法:
? 使用StreamManager創建一個Scope。
StreamManagerstreamManager = StreamManager.create(controllerURI);
final booleanscopeCreation = streamManager.createScope(scope);
StreamManager是創建、刪除和管理stream及scope的接口,通過指定一個控制器地址與控制器通信。
? 使用StreamManager創建一個Stream。
StreamConfigurationstreamConfig = StreamConfiguration.builder()
.scalingPolicy(ScalingPolicy.fixed(1))
.build();
final booleanstreamCreation = streamManager.
createStream(scope, streamName, streamConfig);
創建stream的時候需要指定scope,名稱和配置項。
其中,流配置項包括流的伸縮策略(Scaling Policy)和降層策略(Retention Policy)。Pravega支持三種伸縮策略,將會在下一篇《Pravega動態彈性伸縮特性》中具體介紹。降層策略已經在上一篇中介紹過。
? 使用ClientFactory創建一個Writer,并向Stream中寫數據。
try (ClientFactoryclientFactory = ClientFactory.withScope(scope, controllerURI);
EventStreamWriter
new JavaSerializer
EventWriterConfig.builder().build())) {
final CompletableFuture
}
ClientFactory是用于創建Readers,Writers和其它類型的客戶端對象的工具,它是在Scope的上下文中創建的。ClientFactory以及由它創建的對象會消耗Pravega的資源,所以在示例中用try-with-resources來創建這些對象,以保證程序結束時這些對象會被正確的關閉。如果你使用其他的方式創建對象,請確保在使用結束后正確的調用這些對象的close方法。
在創建Writer的時候還需要指定一個序列化器,它負責把Java對象轉化為字節碼。事件在Pravega中是以字節碼的形式存儲的,Pravega并不需要知道事件的具體類型,這使得Pravega可以存儲任意類型的對象,由客戶端負責提供序列化/反序列化的方法。
用writeEvent方法將事件寫入流,需要指定一個路由鍵(Routing key)。
6使用Reader從流中數據
示例HelloWorldReader舉例說明了如何使用EventStreamReader從Stream中讀取事件,其關鍵部分也是在run()方法中。
? 使用ReaderGroupManager創建一個ReaderGroup。
finalReaderGroupConfigreaderGroupConfig = ReaderGroupConfig.builder()
.stream(Stream.of(scope, streamName))
.build();
try (ReaderGroupManagerreaderGroupManager =
ReaderGroupManager.withScope(scope, controllerURI)) {
readerGroupManager.createReaderGroup(readerGroup, readerGroupConfig);
}
ReaderGroupManager類似于ClientFactory,也是在scope的上下文中創建的。
創建ReaderGroup需要指定名稱和配置項,其中配置項規定了該ReaderGroup從哪些Stream中讀數據,以及所要讀取的Stream的起止位置。Pravega具有Position的概念,它表示Reader當前所在的Stream中的位置。應用保留Reader最后成功讀取的位置,Position的信息可以用于Checkpoint恢復機制,如果讀失敗了就從這個保存的檢查點重新開始讀。
? 創建一個Reader并從流中讀數據。
try (ClientFactoryclientFactory = ClientFactory.withScope(scope, controllerURI);
EventStreamReader
readerGroup,
new JavaSerializer
ReaderConfig.builder().build())) {
EventRead
do {
event = reader.readNextEvent(READER_TIMEOUT_MS);
} while (event.getEvent() != null);
}
Reader也是由ClientFactory創建的。一個新建的Reader會被加入到相應的ReadGroup中,系統根據當前ReaderGroup的工作負載自動分配相應的段給新創建的Reader。Reader可以通過readNextEvent讀取事件。
由于Pravega的自動伸縮功能,Segment的數量會隨著負載的變化而變化,當ReaderGroup管理的Segment總數發生變化時,會觸發段通知(SegmentNotification),ReaderGroup可以監聽該事件并適時地調整Reader的數量。 如果當前的Segment比較多,為了保證讀的并發性,建議增加Reader;反之,如果當前的Segment比較少,建議減少Reader。由于Reader和Segment是一對多的關系,Reader的數量大于Segment的數量是沒有意義的。
本章總結:
本期內容我們重點介紹了Pravega的云原生特性、核心組件、安裝部署實踐以及Reader/Writer的基本應用實踐。
截至目前,我們已經花了4個篇幅(第一期、第二期、第三期)詳細了Pravega,相信你對它已經有了全面的了解,在下一期的內容里,我們將對Pravega的僅一次語義及事務支持進行介紹。歡迎大家持續關注,如何你有疑問,可在下方留言或知乎號上(見下方二維碼)找到我們。下一期見~

掃碼關注知乎號
你和戴爾易安信專家只有一條網線的距離~
















 京公網安備 11010502049343號
京公網安備 11010502049343號