









在這里,你的全身上下都被數據圍繞,無處不在的物聯網、穿梭自如的無人駕駛汽車讓數據源源不斷產生,就像開著的水管,數據源一直流出。你發現曾經用于分析大數據的方法已經失效,因為他們更適合批處理。

面對新的數據場景,你迫切需要一種能夠同時滿足低延時、僅處理一次、順序保證、檢查點的新的存儲系統,否則將無法立足于5G時代。
爭分奪秒,在你的悉心研發之下,新的存儲類型終于誕生了,你將它命名為“Pravega”,取梵語中“Good Speed”之意。

在前兩期的內容里,我們介紹了未來大數據環境下需要新的存儲類型,即原生的流存儲,而Pravega正是為目的這一而生。并介紹了Pravega的關鍵特性,以及它能給開發人員和公司帶來的優勢。今天這篇文章,我們將從Pravega的動態伸縮性來談,并用一份紐約出租車數據寫入Pravega,來看它的動態伸縮表現。
作者簡介

滕昱
滕昱:就職于Dell EMC中國研發集團,非結構化數據存儲部門團隊并擔任軟件開發總監。2007年加入Dell EMC以后一直專注于分布式存儲領域。參加并領導了中國研發團隊參與兩代Dell EMC對象存儲產品的研發工作并取得商業上成功。從2017年開始,兼任Streaming存儲和實時計算系統的設計開發與領導工作。

黃一帆
黃一帆:畢業于上海交通大學計算機專業,現就職于DellEMC,10 年分布式計算、搜索以及架構設計經驗,現從事流式系統相關的設計與開發工作。

周煜敏
周煜敏:復旦大學計算機專業研究生,從本科起就參與Dell EMC分布式對象存儲的實習工作。現參與Flink相關領域研發工作。
Pravega屬于戴爾科技集團IoT戰略下的一個子項目。該項目是從0開始構建,用于存儲和分析來自各種物聯網終端的大量數據,旨在實現實時決策。其結合了戴爾易安信PowerEdge服務器,并無縫集成到非結構化數據產品組合Isilon和Elastic Cloud Storage(ECS)中,同時擁抱Flink生態,以此為用戶提供IoT所需的關鍵平臺。

Pravega能夠應對瞬時的數據洪峰,做到“削峰填谷”,讓系統自動地伴隨數據到達速率的變化而伸縮,既能夠在數據峰值時進行擴容提升瞬時處理能力,又能在數據谷值時進行縮容節省運行成本,而讀寫客戶端無需額外進行調整。這一特性對于企業尤其重要,Devops開銷在企業中都會被歸入產品TCO(Total Cost of Ownership) , 所以產品自身的動態自適應能力將會是必備條件。
下面我們就詳細講述Pravega動態彈性伸縮特性的實現和應用實例。
動態+伸縮性
對于分布式消息系統來說,一個設計良好的,可擴展的分區機制必不可少。分區機制使得讀寫的并行化成為可能,而一個良好的分區擴展機制使得企業在面臨業務增長時可以變得更得心應手。和許多基于靜態分區,或者需要手動擴展分區(如Kafka)系統不同的是,Pravega可以根據數據負載動態地伸縮Stream,以此來實時地應對流量負載變化。
Pravega,把繁瑣變輕松
在當前大數據技術環境下,我們通過將數據拆分成多個分區并獨立處理來獲得并行性。例如,Hadoop通過HDFS和map-reduce實現了批處理并行化。對于流式工作負載,我們今天要使用多消息隊列或Kafka分區來實現并行化。
這兩個選項都有同樣的問題:分區機制會同時影響讀客戶端和寫客戶端。面對持續數據處理的讀/寫,我們的擴展要求往往會有不同,而一個同時影響讀寫的分區機制會增加系統的復雜性。此外,雖然你可以通過添加隊列或分區來進行擴展,但這需要分別對讀、寫客戶端和存儲進行手動調整,然后需要手動協調調整后的參數。這樣的操作不僅復雜,也不是動態的,需要人工介入。

而使用Pravega,我們可以輕松、彈性并且獨立地擴展數據的攝入、存儲和處理,即協調數據管道中每個組件的擴展。
Pravega Stream的動態伸縮智慧
Pravega對動態伸縮的支持源自于把Stream劃分成Segment的想法。
在之前的文章中有介紹過,一個Stream可以具有一個或多個Segment。我們可以把一個 Segment類比成一個分區,寫入Stream的任何數據都會根據指定路由鍵,通過哈希計算路由至某一個Segment。實際應用場景下,我們建議應用開發者基于一些有應用意義的字段,比如customer-id,timestamp,machine-id等來生成路由鍵,這樣就可以確保將同類的應用數據路由至同一個Segment。
Segment是Stream中最基本的并行單元。
• 并行寫:一個具有更多個Segment的Stream可以支持更大的寫入并行度,多個寫客戶端可以并行地對多個 Segment 進行寫入,而這些Segment可能在物理上分布于集群中的多臺服務器上。
• 并行讀:對讀客戶端來說,Segment的數量意味著最大的讀并行度。一個具有N個讀客戶端的讀者組可以以最大為N的并行讀來消費同一個Stream。這樣,當一個Stream中的Segment數量被動態增加時,我們可以相應地增加同等數量的讀客戶端(同一讀者組)來增加并行度;反之亦然,當Segment數量動態減少時,我們也可以減少相應的讀客戶端來節省資源。
深入剖析
Pravega根據一致性散列算法將路由鍵散列至“鍵空間”,該鍵空間被劃分為多個分區,分區數量和Segment數量相一致,同時保證每一個Segment保存著一組路由鍵落入同一區間的事件。
根據路由鍵,我們將一個Stream拆分成了若干個Segment,每一個Segment保存著一組路由鍵落入同一區間的事件,并且擁有著相同的SLO。
同時,Segment可以被封閉(seal),一個被封閉的Segment將禁止寫入。這一概念在動態伸縮中將發揮重要作用。
實例說明伸縮過程
假設某制造企業有400個傳感器,分別編號為0~399,我們將編號做為routing key,并將其散列分布到 (0, 1) 的鍵空間中(Pravega也支持將非數值型的路由鍵散列到鍵空間中)。隨著部分傳感器傳輸頻率的變化,我們來觀察其Segment的變化。
如圖1 所示,在 0~1區間的鍵空間中,Segment的合并和拆分導致了路由鍵隨著時間的推移而被路由至不同的Segment。
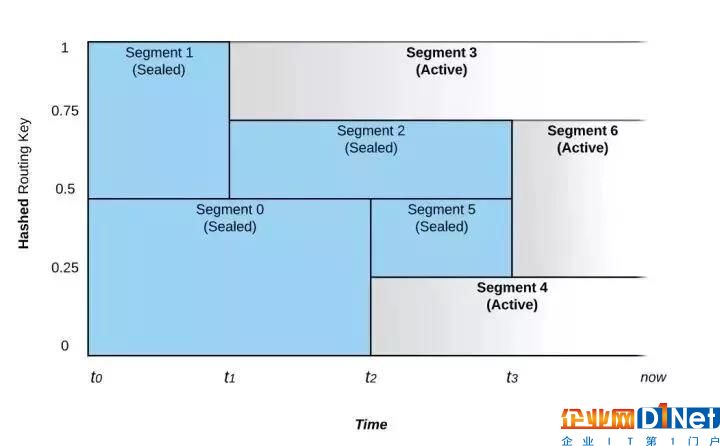
圖 1: Segment的合并和拆分對事件路由的影響
上圖所示的Stream從時間 t0 開始,它被配置成具有動態伸縮功能。如果寫入流的數據速率不變,則段的數量不會改變。
在時間點t1,Pravega監控器注意到數據速率的增加,并且選擇將Segment 1拆分成Segment 2和 Segment 3兩部分,這個過程我們稱之為Scale-up事件。在t1之前,路由鍵散列到鍵空間上半部的(值為 200~399)的事件將被放置在 Segment 1中,而路由鍵散列到鍵空間下半部的(值為 0~199)的事件則被放置在 Segment 0 中。在 t1 之后Segment 1被拆分成Segment 2 和 Segment 3,Segment 1則被封閉,即不再接受寫入。此時,具有路由鍵300及以上的事件被寫入 Segment 3,而路由鍵在200和299之間的事件將被寫入Segment 2。Segment 0則仍然保持接受與t1之前相同范圍的事件。
在t2時間點,我們看到另一個Scale-up事件。這次事件將Segment 0拆分成Segment 4和Segment 5。Segment 0因此被封閉而不再接受寫入。
具有相鄰路由鍵散列空間的Segment也可以被合并,比如在t3時間點,Segment 2和 Segment 5被合并成為Segment 6,Segment 2和Segment 5都會被封閉,而t3之后,之前寫入Segment 2和Segment 5的事件,也就是路由鍵在100和299之間的事件將被寫入新的Segment 6中。合并事件的發生表明Stream上的負載正在減少。
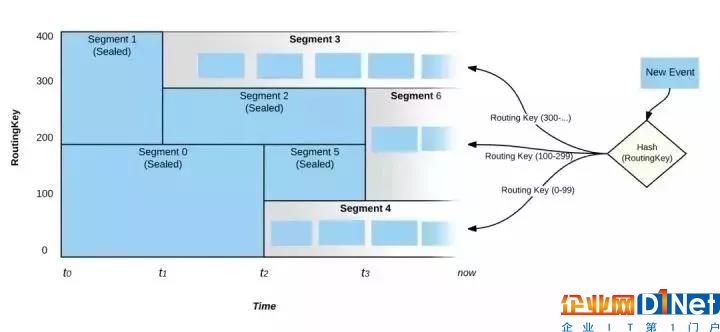
圖2: 事件的路由
如圖2,在“現在”這個時刻,只有Segment3,6 和4處于活動狀態,并且所有活躍的Segment將會覆蓋整個鍵空間。在上述的規則2和3中,即使輸入負載達到了定義的閾值,Pravega也不會立即觸發scale-up/down的事件,而是需要負載在一段足夠長的時間內超越策略閾值,這也避免了過于頻繁的伸縮策略影響讀寫性能。
真真實數據用例
我們使用由美國紐約市政府授權開源的出租車數據,包括上下車時間,地點,行程距離,逐項票價,付款類型、乘客數量等字段。我們把歷史數據集模擬成了流式數據實時地寫入Pravega。所取的數據集涵蓋的是2015年3月的黃色出租車行程數據,其數據量為1.9GB,包括近千萬條記錄,每條記錄17個字段。我們選取了其中12個小時的數據,形成如圖3所示數據統計:
黃色和綠色的出租車行程記錄包括捕獲乘客上車和下車日期/時間,接送和下車地點,行程距離,逐項票價,費率類型,付款類型和司機報告的乘客數量的字段。我們把歷史數據集模擬成了流式數據實時地寫入Pravega。所取的數據集涵蓋的是2015年3月的黃色出租車的行程數據,其數據量為1.9GB,包括近千萬條記錄,每條記錄17個字段。我們選取了其中12 個小時的數據,形成如圖3所示數據統計:
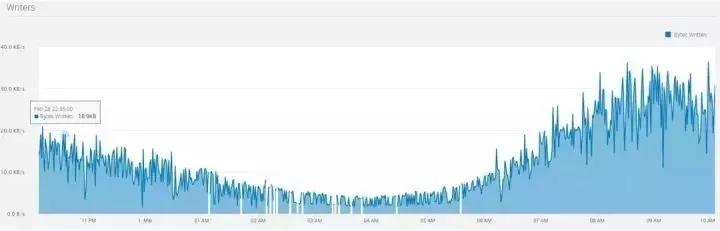
圖3: 出租車數據流量記錄
由上圖我們可以觀察到,數據流量在早上4點左右處于谷點,而在早晨9點左右達到峰值。峰值流量的寫入字節數大約為谷點流量的10倍。我們將Stream的伸縮規則配置為上述規則2(基于大小的伸縮規則)。
相對應地,Stream的Segment熱點圖如圖4所示動態變化:
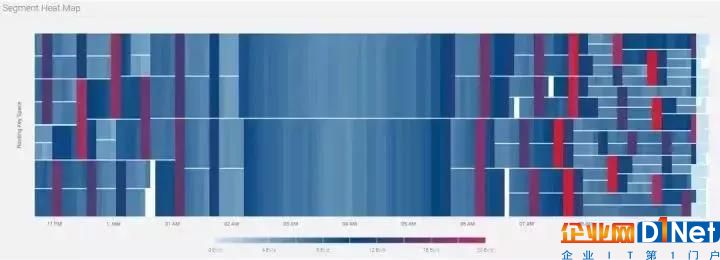
圖4: Segment 熱點圖
從上圖可以看出,從晚11點至凌晨2點,Segment逐漸合并;從早晨6點至10點,Segment逐步拆分。從拆分次數來看,大部分Segment總共拆分3次,小部分拆分4次,這也印證了流量峰值10倍于谷底的統計值(3
我們使用出租車行程中的出發點坐標位置來作為路由鍵。當高峰來臨時,繁忙地段產生的大量事件會導致Segment被拆分,從而會有更多的讀客戶端來進行處理;當谷峰來臨時,非繁忙地段產生的事件所在的Segment會進行合并,部分的讀客戶端會下線,剩下的讀客戶端會處理更多地理區塊上產生的事件。
本章總結:
本期內容我們重點介紹了Pravega的動態伸縮機制。它可以讓應用開發和運維人員不必關心因流量變化而導致的分區變化需要,無需手動調度集群。分區的流量監控和相應變化由Pravega來進行,從而使流量變化能夠實時而且平滑地體現到應用程序的伸縮上。獨立伸縮機制使得生產者和消費者可以各自獨立地進行伸縮,而不影響彼此。整個數據處理管道因此變得富有彈性,可以應對實時數據的不斷變化,結合實際處理能力而做出最為適時的反應。
截至目前,我們已經花了3個篇幅(第一期、第二期)詳細了Pravega,相信你對它已經有了一定的了解,話說百遍不如自己跑一遍,在下一期的“IoT前沿”中,我們就將為大家帶來實戰演練,介紹Pravega的部署方式。
歡迎大家持續關注,如何你有疑問,可在下方留言或知乎號上(見下方二維碼)找到我們。下一期見~

掃碼關注知乎號
你和戴爾易安信專家只有一條網線的距離~
















 京公網安備 11010502049343號
京公網安備 11010502049343號