









面向用戶日益增長的對于構建更智慧AI應用的計算需求,提供性能更加強悍、彈性易擴展和高性價比的云上計算能力,成為業界的共同目標。金山云基于對用戶需求的深刻把控,于近期正式推出了基于NVIDIA Tesla V100的GPU云服務器,支持最高15*8 TFLOPS的單精浮點計算能力和125*8TFLOPS的混合精度(FP16/FP32)矩陣計算能力,使深度學習訓練與推理過程性能提升300%,而成本保持不變。

210億顆晶體管構建最強計算力
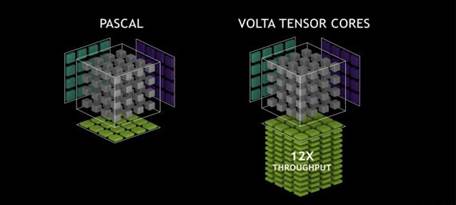
作為國內首家正式公開售賣的基于Tesla V100的GPU云服務器,使用了創新的Tensor Core引擎,將混合精度浮點的計算能力再提升10倍以上,在整體深度學習的訓練與推理應用中相比于上一代PASCAL平臺有了3倍性能提升,可輕松應對深度學習,科學運算、圖形圖像渲染等諸多應用場景,有效縮短在線預測和離線訓練時長。
目前基于V100的GPU加速計算服務已全面商用,為包括小米等在內的諸多客戶提供著高性能的計算支撐。小米最新發布的年度旗艦手機小米8,其AI加持的全面屏系統MIUI 10、AI相機、AI語音助理“小愛同學”等,背后均有金山云頂級GPU資源提供的計算服務,極大提升了產品的研發效率和使用體驗。
在基礎結構層面,Tesla V100一共包含了210億顆晶體管,搭載了84個SM(流多處理器)單元,其中有效單元有80個,每個SM單元中有64個單精度的處理單元CUDA Core以及8個混合精度的矩陣運算單元Tensor Core,總計共有5120個CUDA Core和640個Tensor Core,搭載16GB的HBM 2的顯存,帶寬可以高達900GB/s,并且支持300GB/s雙向帶寬的NVLink2.0的主線協議。
全新的Volta架構示意圖
在線程調配層面,V100是首款支持獨立線程調度的GPU,允許GPU執行任何線程,從而程序中的并行線程之間能實現更精細的同步與協作,使用戶能在更復雜多樣的應用程序上高效地工作。獨創的Tensor Core打破了單處理器的最快處理速度記錄,能夠提供比功能單一的ASIC更高的性能,在不同工作負載下仍然具備可編程性。
Tensor Core打造更專業的深度學習計算單元
Tensor Core是Volta架構最重磅的特性,是專門針對深度學習應用而設計的專用ASIC單元,是一種矩陣乘累加的計算單元。(矩陣乘累加計算在Deep Learning網絡層算法中,比如卷積層、全連接層等是最重要、最耗時的一部分)。Tensor 核心每個時鐘周期可執行64次浮點混合乘加(FMA)運算,從而為訓練和推理應用程序提供高達125 TFLOPS的計算性能。
更強悍的計算能力意味著開發人員可以使用混合精度(FP16 計算使用 FP32 累加)執行深度學習訓練,從而實現比上一代產品快3倍的性能,并可收斂至網絡預期準確度,目前Tensor Core可以支持的深度學習框架有Caffe、Caffe2、MXNet、PyTorch、Theano、TensorFƒlow等。
NVLink互聯方式示意圖
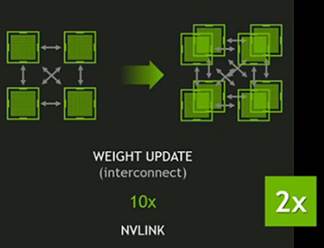
此外,Tesla V100的NVLink版本支持NVLink2.0高速互聯總線協議,Tesla P100支持的NVLink1.0協議,每顆GPU可以連接4根總線,每根總線的單向傳輸帶寬可以達到20GB/s,四根總線可以實現單向80GB/s、雙向160GB/s的IO帶寬。而Tesla V100支持最新的NVLink2.0協議,每顆GPU最多可以實現六根總線互聯,每根總線的單向傳輸帶寬可以達到25GB/s,六根總線可以實現單向150GB/s、雙向300GB/s的IO帶寬,相比NVLink1.0,帶寬幾乎提升了1倍。
高混合精度計算能力讓計算更高效
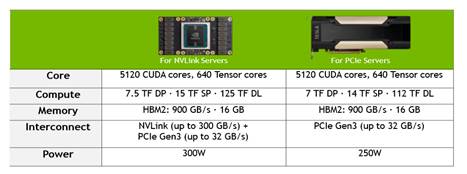
Tesla V100有NVLink和PCIe兩個版本,計算核心都是GV100,均有5120個CUDA Cores以及640個Tensor Cores, NVLink 版本主頻略高,雙精度浮點計算能力達到7.5TFLOPS,單精度浮點計算能力達到了15TFLOPS,而混合精度計算能力可以達到125 TFLOPS ,PCIe版本有7TFLOPS雙精度浮點計算能力、14TFLOPS單精度浮點計算能力和112個TFLOPS混合精度計算能力。
在訓練 ResNet-50 時,單個V100 Tensor Core GPU的處理速度能達到1075 張圖像/秒,與上一代Pascal GPU相比,它的性能提高了4倍。據測算,假如有100萬張圖片需要學習,理論上僅需約15分鐘即可訓練完成。
NVLink和PCIe版本Tesla V100對比
金山云作為國內首家正式商用Tesla V100的云服務廠商,目前在售基于V100的服務器有GPU云服務器(P4V系列)和GPU物理服務器(P4E系列)。卓越的深度學習計算性能,讓用戶能夠更加快速、高效構建AI業務,彈性易擴展和高性價比的特性,能夠為用戶節省大量計算成本,有效降低AI開發的時間風險,提高企業AI競爭力。
















 京公網安備 11010502049343號
京公網安備 11010502049343號