









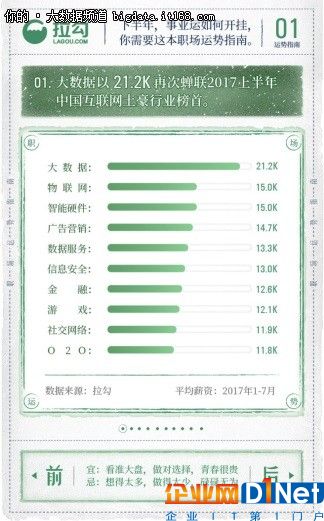
在某招聘網站2017年上半年各行業薪資調研狀況報告中,大數據行業以平均21.2k的月薪高居互聯網行業榜首,遠遠高于其他各行業。在大數據行業,Hadoop目前絕對算得上是明星產品,在行業內應用廣泛。如果你恰好想找一份與Hadoop有關的工作,不妨先看看基本面試題都有哪些吧!
1、海量日志數據提取出某日訪問百度次數最多的IP,怎么做?

2、有一個1G大小的文件,里面每一行是一個詞,詞的大小不超過16字節,內存限制大小是1M。返回頻數最高的100個詞。

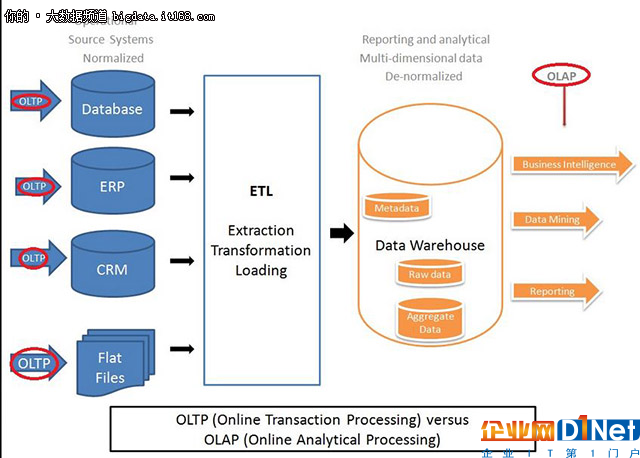
3、更智能&更大的數據中心架構與傳統的數據倉庫架構有何不同?
傳統的企業數據倉庫架構
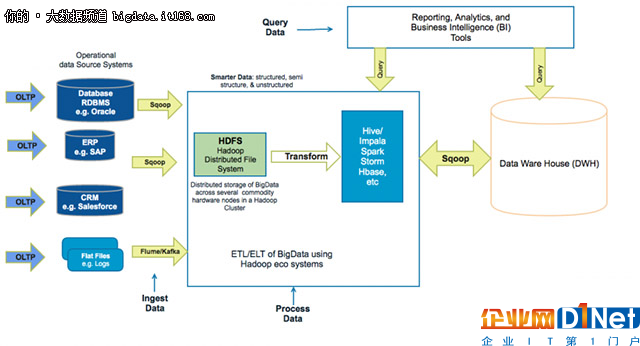
基于 Hadoop 的數據中心架構
4、運行Hadoop集群需要哪些守護進程?
DataNode,NameNode,TaskTracker和JobTracker都是運行Hadoop集群需要的守護進程。
5、Hadoop支持哪些操作系統部署?
Hadoop的主要操作系統是Linux。 但是,通過使用一些額外的軟件,也可以在Windows平臺上部署,但這種方式不被推薦。
6、Hadoop常見輸入格式是什么?
三種廣泛使用的輸入格式是:
·文本輸入:Hadoop中的默認輸入格式。
·Key值:用于純文本文件
·序列:用于依次讀取文件
7、RDBMS和Hadoop的主要區別是什么?
RDBMS用于事務性系統存儲和處理數據,而Hadoop可以用來存儲大量數據。
8、給定a、b兩個文件,各存放50億個url,每個url各占64字節,內存限制是4G,讓你找出a、b文件共同的URL?


9、如何在生產環境中部署Hadoop的不同組件?
需要在主節點上部署jobtracker和namenode,然后在多個從節點上部署datanode。
10、添加新datanode后,作為Hadoop管理員需要做什么?
需要啟動平衡器才能在所有節點之間重新平均分配數據,以便Hadoop集群自動查找新的datanode。要優化集群性能,應該重新啟動平衡器以在數據節點之間重新分配數據。
11、namenode的重要性是什么?
namenonde的作用在Hadoop中非常重要。它是Hadoop的大腦,主要負責管理系統上的分配塊,還為客戶提出請求時的數據提供特定地址。
12、判斷:Block Size是不可以修改的。(錯誤)
分析:

13、當NameNode關閉時會發生什么?
如果NameNode關閉,文件系統將脫機。
14、是否可以在不同集群之間復制文件?如果是的話,怎么能做到這一點?
是的,可以在多個Hadoop集群之間復制文件,這可以使用分布式復制來完成。
15、是否有任何標準方法來部署Hadoop?
現在有使用Hadoop部署數據的標準程序,所有Hadoop發行版都沒有什么通用要求。但是,對于每個Hadoop管理員,具體方法總是不同的。
16、HDFS,replica如何定位?

17、distcp是什么?
Distcp是一個Hadoop復制工具,主要用于執行MapReduce作業來復制數據。 Hadoop環境中的主要挑戰是在各集群之間復制數據,distcp也將提供多個datanode來并行復制數據。
18、什么是檢查點?
檢查點是一種采用FsImage的方法。它編輯日志并將它們壓縮成一個新的FsImage。因此,不用重放一個編輯日志,NameNode可以直接從FsImage加載到最終的內存狀態,這肯定會降低NameNode啟動時間。
19、什么是機架感知?
這是一種決定如何根據機架定義放置塊的方法。Hadoop將嘗試限制存在于同一機架中的datanode之間的網絡流量。為了提高容錯能力,名稱節點會盡可能把數據塊的副本放到多個機架上。 綜合考慮這兩點的基礎上Hadoop設計了機架感知功能。
20、有哪些重要的Hadoop工具?
“Hive”,HBase,HDFS,ZooKeeper,NoSQL,Lucene / SolrSee,Avro,Oozie,Flume,Clouds和SQL是一些增強大數據性能的Hadoop工具。
21、什么是投機性執行?
如果一個節點正在執行比主節點慢的任務。那么就需要在另一個節點上冗余地執行同一個任務的一個實例。所以首先完成的任務會被接受,另一個可能會被殺死。這個過程被稱為“投機執行”。
22、Hadoop及其組件是什么?
當“大數據”出現問題時,Hadoop發展成為一個解決方案。這是一個提供各種服務或工具來存儲和處理大數據的框架。這也有助于分析大數據,并做出用傳統方法難以做出的商業決策。
23、Hadoop的基本特性是什么?
Hadoop框架有能力解決大數據分析的許多問題。它是基于Google大數據文件系統的Google MapReduce設計的。
24、是否可以在Windows上運行Hadoop?
可以,但是最好不要這么做,Red Hat Linux或者是Ubuntu才是Hadoop的最佳操作系統。在Hadoop安裝中,Windows通常不會被使用,因為會出現各種各樣的問題。因此,Windows絕不是Hadoop推薦系統。
25、主動和被動“名稱節點”是什么?
在HA(高可用性)架構中,我們有兩個NameNodes - Active“NameNode”和被動“NameNode”。
· 活動“NameNode”是在集群中運行的“NameNode”。
· 被動“NameNode”是一個備用的“NameNode”,與“NameNode”有著相似的數據。
當活動的“NameNode”失敗時,被動“NameNode”將替換群集中的活動“NameNode”。因此,集群永遠不會沒有“NameNode”,所以它永遠不會失敗。
















 京公網安備 11010502049343號
京公網安備 11010502049343號